Whose Responsibility Is It To Get Generative AI Right?
The limitless possibilities of the technology that transcends boundaries.

Image from Canva
The rate at which the data has been created over the last few years has been exponential, primarily signifying the increased proliferation of the digital world.
It is estimated that? 90% of the world’s data was generated in the last two years alone.
The more we interact with the internet in varied forms? – from sending text messages, sharing videos, or creating music?, we contribute to the pool of training data that powers up Generative AI (GenAI) technologies.
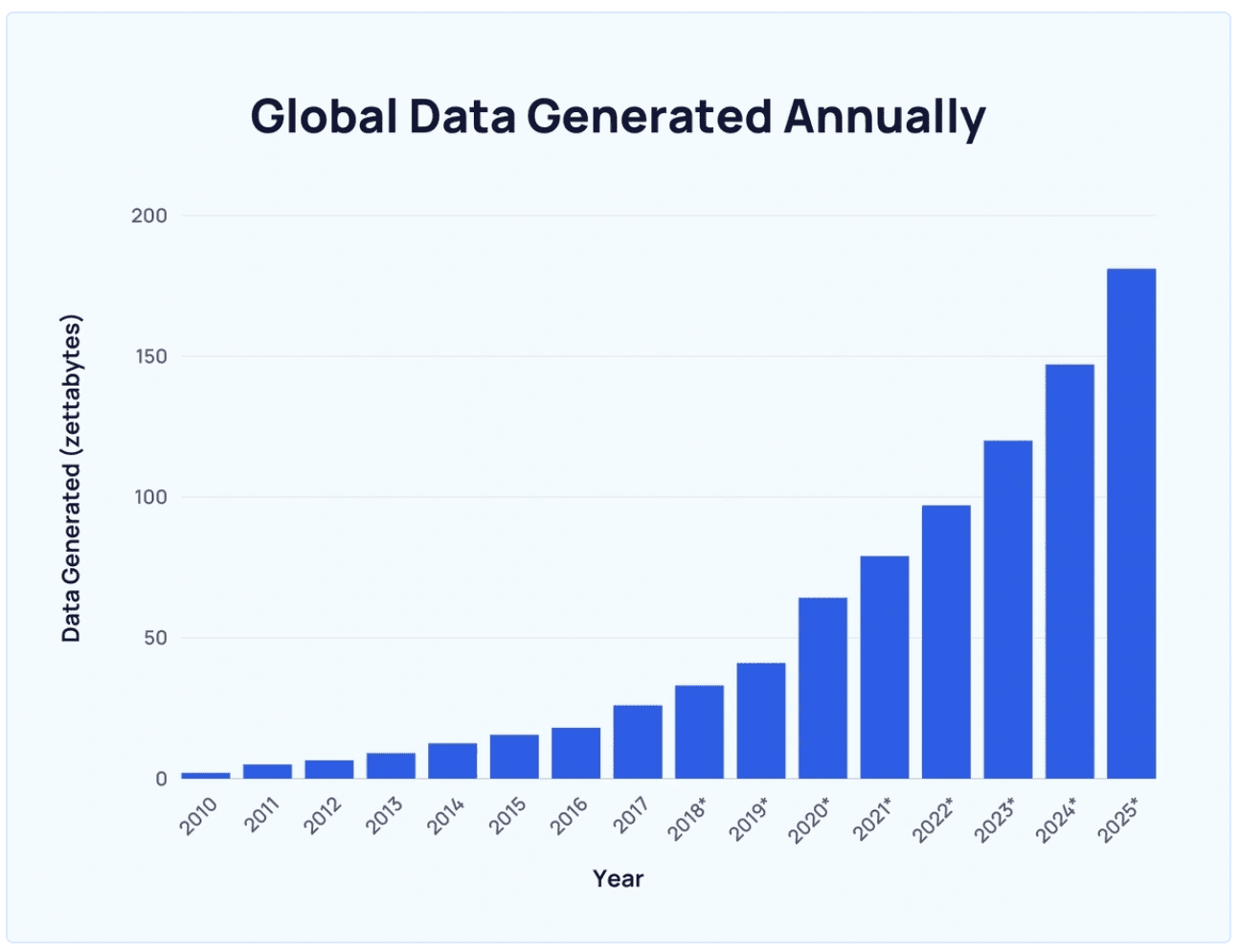
Global data generated annually from explodingtopics.com
In principle, our data goes as input to these advanced AI algorithms that learn and generate newer data.
The Other Side of GenAI
Needless to say that it sounds intriguing at first, but it starts posing risks in various forms as the reality begins to set in.
The other side of these technological developments soon opens the pandora's box of problems? in the form of misinformation, misuse, information hazards, deep fakes, carbon emissions, and many more.
Further, it is crucial to note the impact of these models in rendering a lot of jobs redundant.
As per Mckinsey’s recent report “Generative AI and the future of work in America”?—? jobs that involve a high share of repetitive tasks, data collection, and elementary data processing are at increased risk of becoming obsolete.
The report quotes automation, including GenAI, as one of the reasons behind the decline in demand for basic cognitive and manual skills.
Besides, a vital concern that has persisted from the pre-GenAI era and continues to pose challenges is data privacy. The data, which forms the core of GenAI models, is curated from the internet, which includes a fractional part of our identities.

Image from The Conversation
One such LLM is claimed to be trained on some 300 billion words with data scraped from the internet, including books, articles, websites, and posts. What is concerning is that we were unaware of its collection, consumption, and usage all this while.
MIT Technology Review finds it “next to impossible for OpenAI to comply with the data protection rules”.
Is Open-Source The Solution?
With all of us being fractional contributors to this data, there is an expectation to open-source the algorithm and make it transparent for everyone to make sense of.
While open access models give details about code, training data, model weights, architecture, and evaluation results?—?basically everything under the hood that you need to know.

Image from Canva
But would most of us be able to make sense of it? Probably not!
This gives rise to the need to share these vital details in the proper forum – a committee of experts, including policymakers, practitioners, and government.
This committee will be able to decide what is best for humanity?—?something that no individual group, government, or organization can decide on their own today.
It must consider the impact on society as a high priority and evaluate the effect of GenAI from varied lenses?—?social, economic, political, and beyond.
Governance Does Not Hinder Innovation
Leaving the data component aside, the developers of such colossal models make massive investments to provide computing power to build these models, making it their prerogative to keep them closed-access.
The very nature of making investments imply that they would want a return on such investments by using them for commercial use. That's where the confusion starts.
Having a governing body that can regulate the development and release of AI-powered applications does not inhibit innovation or impede business growth.
Instead, its primary aim is to build guardrails and policies that facilitate business growth through technology while promoting a more responsible approach.
So, who decides the responsible quotient, and how does that governing body come into being?
Need For a Responsible Forum
There should be an independent entity comprising experts from research, academia, corporates, policymakers, and governments/countries. To clarify, independent means that its funds must not be sponsored by any player that can cause a conflict of interest.
Its sole agenda is to think, rationalize and act on behalf of 8 bn people in this world and make the sound judgment, holding high accountability standards for its decisions.
Now, that is a big statement, which means, the group has to be laser-focused and treat the task entrusted to them as secondary to none. We, the world, can not afford to have the decision-makers working on such a critical mission as a good-to-have or side-project, which also means that they must be funded well too.
The group is tasked to execute a plan and a strategy that can address the harms without compromising on realizing the gains from the technology.
We Have Done It Before
AI has often been compared with nuclear technology. Its cutting-edge developments have made it difficult to predict the risks that come with it.
Quoting Rumman from Wired on how the International Atomic Energy Agency (IAEA)?—?an independent body free of government and corporate affiliation was formed to provide solutions to the far-reaching ramifications and seemingly infinite capabilities of nuclear technologies.
So, we have instances of global cooperation in the past where the world has come together to put chaos into order. I know for sure that we will get there at some point. But, it is crucial to converge and form the guardrails sooner to keep up with the rapidly evolving pace of deployments.
Humanity can not afford to put itself on voluntary measures of corporates, wishing for responsible development and deployment by tech companies.
Vidhi Chugh is an AI strategist and a digital transformation leader working at the intersection of product, sciences, and engineering to build scalable machine learning systems. She is an award-winning innovation leader, an author, and an international speaker. She is on a mission to democratize machine learning and break the jargon for everyone to be a part of this transformation.