WavJourney: A Journey into the World of Audio Storyline Generation
From Prompt to Power: Unleashing Stories and Audio with a Single Spark!
Introduction
The recent advent of Large Language Models has taken the world by storm. Now, imagination is the limit. Today, WavJourney can automate the art of storytelling. Given a single prompt, WavJourney leverages the power of LLMs to generate grasping audio scripts, complete with an accurate storyline, lifelike human voices, and engaging background music.
To properly view the powers of audio generation, consider the following scenario. We only need to provide a simple instruction, describing a scenario and scene setting, and the model generates a gripping audio script highlighting the supreme context relevance to the original instruction.
INSTRUCTION: Generate audio in Science Fiction theme: Mars News reporting that Humans send a light-speed probe to Alpha Centauri. Start with a news anchor, followed by a reporter interviewing a chief engineer from an organization that built this probe, founded by United Earth and Mars Government, and end with the news anchor again.
GENERATED AUDIO: https://audio-agi.github.io/WavJourney_demopage/sci-fi/sci-fi%20news.mp4
To truly understand the internal workings of this marvel, let us dive deep into the methodology and implementation details of the generation process.
Generation Process
The image below summarizes the complete process in a simple flowchart.
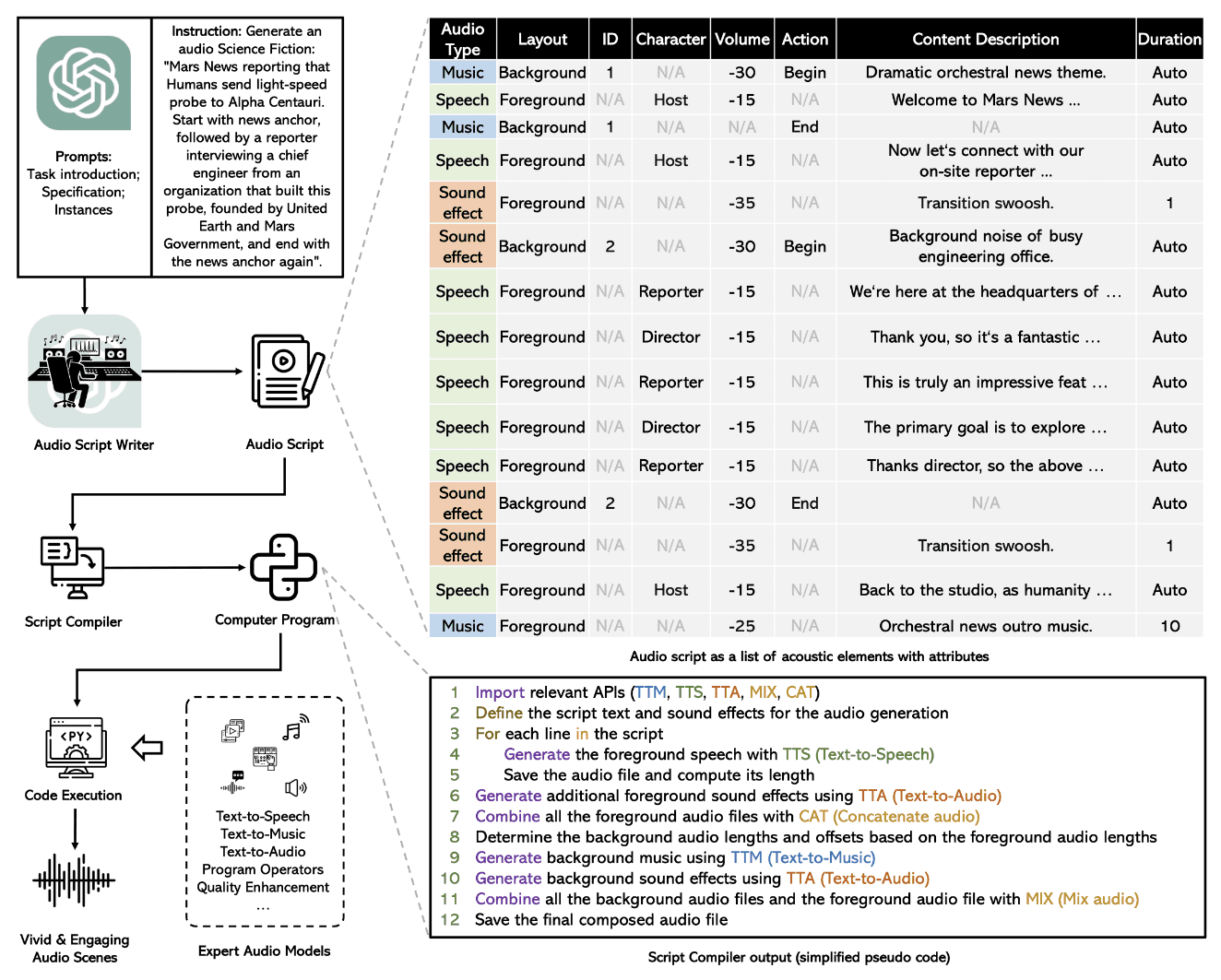
Image from Paper
The end-to-end audio generation process is composed of multiple submodules, that are executed sequentially for a complete Text-to-Audio model.
Audio Script Generation
WavJourney utilizes GPT-4 model with a predefined prompt template to generate the script. The prompt templates restrict the output to be in a simple JSON format, that can easily be parsed later by a computer program. Each script has 3 different audio types as shown in the image above: Speech, sound effects, and music. Each audio type can then be run as foreground audio, or overlaid as a background sound effect over other audio. Other attributes such as content description, length, and character are sufficient attributes to formally define an audio setting for script generation.
Script Parsing
The output script is then passed through a computer program, that parses the relevant information from the predefined JSON script format. It associates each description and character to a preset speech audio. This process helps in breaking down the audio generation process into separate steps, that include text-to-speech, music, and sound addition.
Audio Generation
The parsed script is executed as a Python program. Foreground speech is first generated that is overlaid by background music and sound effects. For speech generation, the model uses the pre-trained Bark model and a VoiceFixer restoration model to improve audio quality. AudioLDM and MusicGen models are utilized for sound effects and music overlays. The outputs of all three models are combined for the final audio output.
Human-Machine Co-Creation
The process maintains context of the generated scripts, and can be prompted similar to GPT models. You can easily modify the generated script using human feedback and chat capabilities of GPT models.
Adding specific details and sound effects could not have been easier than this.The flowchart below shows how simple it is to add or modify specific details of the generated script.
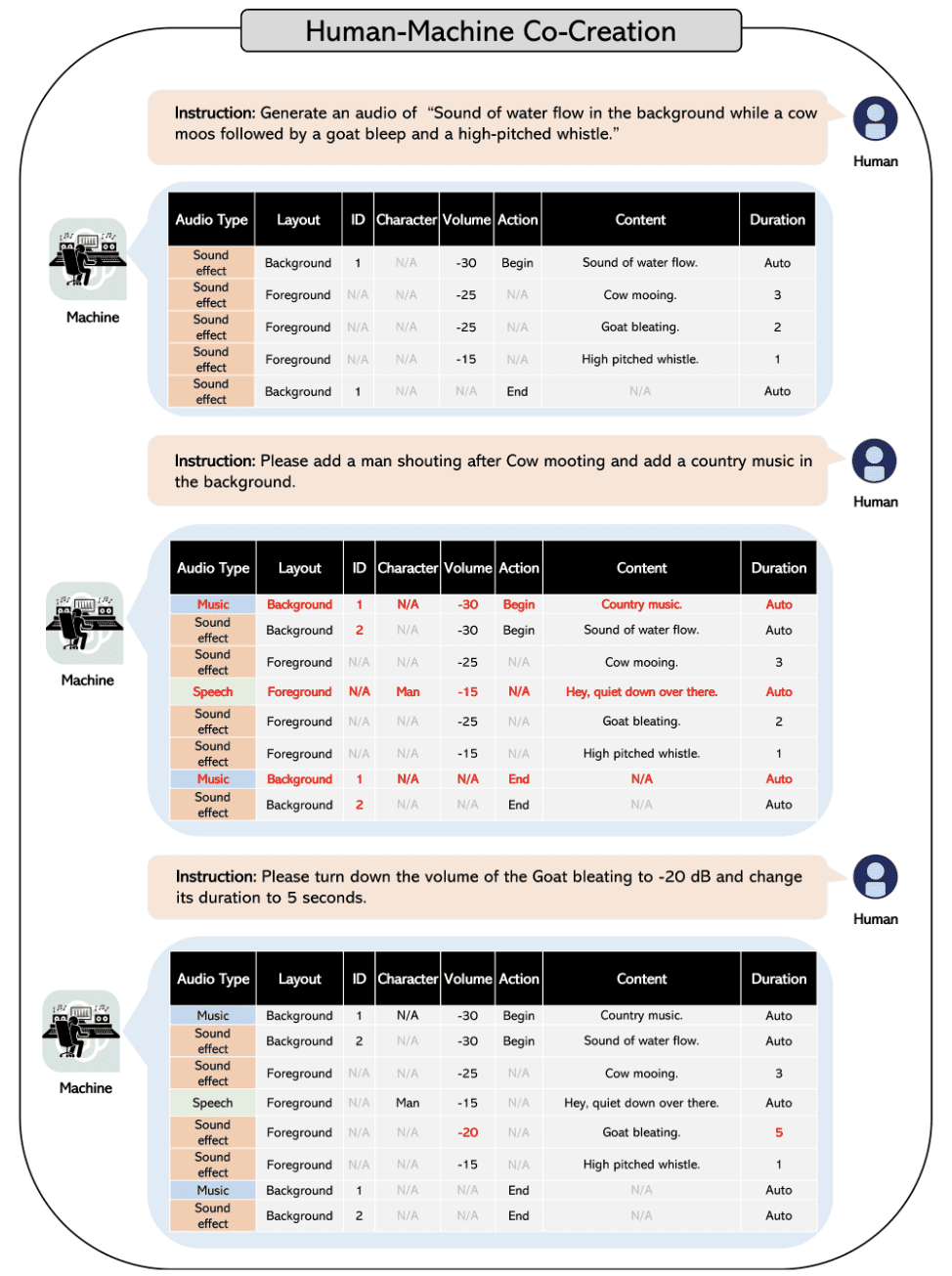
Image from Paper
Conclusion
The audio generation model can be a game-changer for the entertainment industry. The process has the ability to generate engaging narratives and stories, that can be utilized for educational and entertainment purposes, automating tedious voice-over and video generation processes.
For a detailed understanding, overview the paper here. The code will soon be available on GitHub.
Muhammad Arham is a Deep Learning Engineer working in Computer Vision and Natural Language Processing. He has worked on the deployment and optimizations of several generative AI applications that reached the global top charts at Vyro.AI. He is interested in building and optimizing machine learning models for intelligent systems and believes in continual improvement.