Topic Modeling with Streamlit
What does it take to create and deploy a topic modeling web application quickly? Read this post to see how the author uses Python NLP packages for topic modeling, Streamlit for the web application framework, and Streamlit Sharing for deployment.
By Bryan Patrick Wood, Senior Data Scientist
What does it take to create and deploy a topic modeling web application quickly? I endeavored to find this out using Python NLP packages for topic modeling, Streamlit for the web application framework, and Streamlit Sharing for deployment.
I had been directed to use topic modeling on a project professionally, so I already had direct experience with relevant techniques on a challenging real-world problem. However, I encountered several unexpected difficulties sharing topic modeling results with a non-technical audience.

Shortly after, I was consulted on implementing a topic modeling feature in a product system operating at scale. Here, again, the group I was trying to assist had a hard time understanding exactly what to expect out of topic modeling and keeping the important differences between supervised, semi-supervised, and unsupervised machine learning approaches straight8.
This motivated me to put something together to show, don't tell so to speak. I wanted something tangible for the folks I was dealing with to play around with. This was also a good excuse to use Streamlit and try out Streamlit Sharing. I had been proselytizing Streamlit for a few use-cases professionally when really I had only played around with a few toy examples. Deploying via Streamlit Sharing was new and piqued my curiosity.
Disclaimers
First, the application is still very much a work in progress / prototype. There is functionality stubbed out that is not implemented (e.g., using non-negative matrix factorization1). Code all needs to be refactored out of a sprawling 250 line script too. Focus was on getting enough of the piece parts working well enough to allude to robust capabilities that could be implemented and having enough of a complete application to stimulate discussion. Second, Streamlit had good support for literate programming2. As a result, some narrative is repeated from the application here. As such, if you have already gone to the application you can skim some of what follows.
Topic Modeling
As I would find out, topic modeling can mean different things to different people. The words topic and model are common enough where most people can look at them and formulate an opinion on what the technique must accomplish when successful.
Without additional qualifications, the term topic modeling usually refers to types of statistical models used in the discovery of abstract topics that occur in a collection of documents6. These techniques are almost always fully unsupervised although semi-supervised and supervised variants do exist. Among the most commonly used techniques, and the one that is fully implemented in the application, is Latent Dirichlet Allocation (LDA)7.
At a superficial level, LDA is just a matrix factorization of the words document relationship matrix (viz., below) into a two relationship matrices: words to topics and topics to documents. The theory posits an underlying distribution of words in topics and topics in documents but that is more of interest if one wishes to understand underlying theory which is well exposed elsewhere.
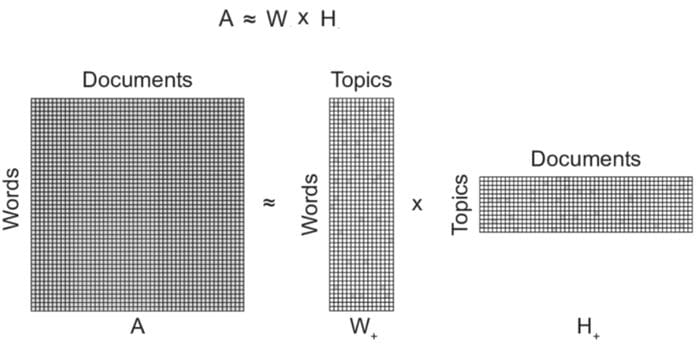
Not going deep into LDA theory here: that is a topic for its own blog post and another time.
I had done a lot of experimentation on the professional project. That experimentation is not directly useful outside its context which I cannot share. I will highlight some snippets of code that may be of use to an aspiring topic modeler.
Preprocessing is vitally important in all machine learning problems. In NLP problems, there tends to be a lot more choices than in other domains. For topic modeling specifically, one usually wants to remove various types of named entities before applying modeling. The following function was used to denoise the text documents
import pandas as pd
import regex
from gensim.utils import simple_preprocess
from nltk.corpus import stopwords
EMAIL_REGEX_STR = '\S*@\S*'
MENTION_REGEX_STR = '@\S*'
HASHTAG_REGEX_STR = '#\S+'
URL_REGEX_STR = r'((http|https)\:\/\/)?[a-zA-Z0-9\.\/\?\:@\-_=#]+\.([a-zA-Z]){2,6}([a-zA-Z0-9\.\&\/\?\:@\-_=#])*'
def denoise_docs(texts_df: pd.DataFrame, text_column: str):
texts = texts_df[text_column].values.tolist()
remove_regex = regex.compile(f'({EMAIL_REGEX_STR}|{MENTION_REGEX_STR}|{HASHTAG_REGEX_STR}|{URL_REGEX_STR})')
texts = [regex.sub(remove_regex, '', text) for text in texts]
docs = [[w for w in simple_preprocess(doc, deacc=True) if w not in stopwords.words('english')] for doc in texts]
return docs
I also experimented with using bigram and trigram phrases through gensim.models.Phrases and gensim.models.phrases.Phraser but did not see a big lift. Using the bigrams and trigrams themselves rather than as a preprocessing step may have been more impactful. The final step in document preprocessing was using spaCy to perform lemmantization.
import pandas as pd
import spacy
def generate_docs(texts_df: pd.DataFrame, text_column: str, ngrams: str = None):
docs = denoise_docs(texts_df, text_column)
# bigram / trigam preprocessing ...
lemmantized_docs = []
nlp = spacy.load('en_core_web_sm', disable=['parser', 'ner'])
for doc in docs:
doc = nlp(' '.join(doc))
lemmantized_docs.append([token.lemma_ for token in doc])
return lemmantized_docs
The modeling code is gensim standard fare
import gensim
from gensim import corpora
def prepare_training_data(docs):
id2word = corpora.Dictionary(docs)
corpus = [id2word.doc2bow(doc) for doc in docs]
return id2word, corpus
def train_model(docs, num_topics: int = 10, per_word_topics: bool = True):
id2word, corpus = prepare_training_data(docs)
model = gensim.models.LdaModel(corpus=corpus, id2word=id2word, num_topics=num_topics, per_word_topics=per_word_topics)
return model
I had intended to add more modeling options but ran out of time. At very least, I will be adding in an option to use NMF in the future. Anecdotally, NMF can produce better topics depending on the dataset being investigated. Adding any method that is not unsupervised will be a much bigger lift.
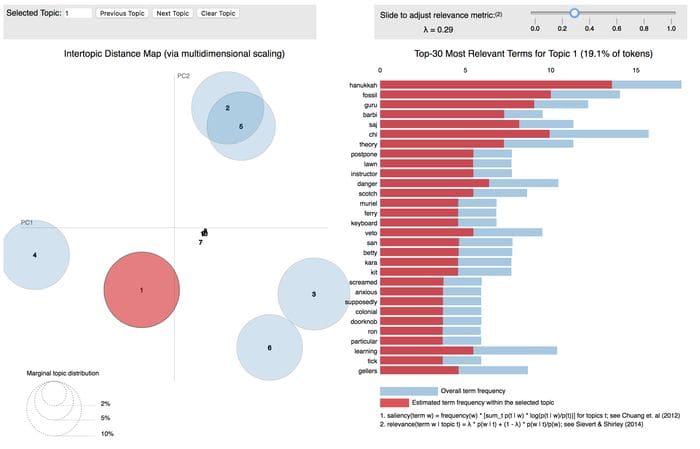
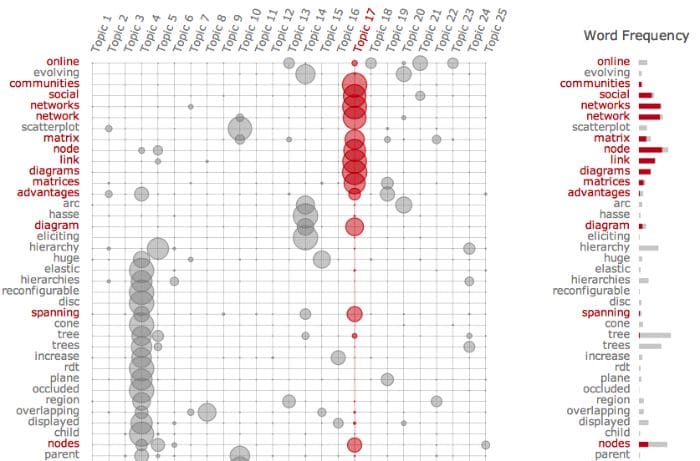
For visualization, I liberally took from Topic modeling visualization – How to present the results of LDA models? specifically for the model result visualizations: it is a good reference for visualizing topic model results.
pyLDAvis9 is also a good topic modeling visualization but did not fit great with embedding in an application. Termite plots10 are another interesting topic modeling visualization available in Python using the textaCy package.
The most involved visualization I had time for was the word clouds and since there was already a Python package to do just that the task was trivial.
from wordcloud import WordCloud
WORDCLOUD_FONT_PATH = r'./data/Inkfree.ttf'
def generate_wordcloud(docs, collocations: bool = False):
wordcloud_text = (' '.join(' '.join(doc) for doc in docs))
wordcloud = WordCloud(font_path=WORDCLOUD_FONT_PATH, width=700, height=600, background_color='white', collocations=collocations).generate(wordcloud_text)
return wordcloud

The settings required a little playing around with to get something that looked decent. Adding additional visualizations is the main place I felt like I ran out of time and will likely revisit.
Streamlit
Streamlit is an open-source Python library that makes it easy to create and share beautiful, custom web apps for machine learning and data science. I will focus on the create here and on the sharing in the sequel although sharing on a trusted local area network is trivial.
The main value proposition is taking a data science or machine learning artifact to web application quick for the purpose of sharing with folks that would not be comfortable with something like a Jupyter notebook. On this it delivers. I went from script to web application in a couple hours. That allowed me to share a web application with a group of decision makers that were trying to make heads or tails of what topic modeling even meant. I was very impressed from the provider-end and received feedback of the same from the receiver-end.
Another benefit would be its pure Python nature (i.e., no HTML, CSS, JS, etc.) so no need to require data scientists to learn wonky web technologies they have no interest in learning. A comparison with Plotly Dash probably deserves its own blog post but the Dash approach is very much more in the camp of making React easier to do in Python. It is very much focused on
Probably not a big concern from most folks thinking about using this technology given its target but its worth noting, for those with experience in traditional GUI application frameworks, that Streamlit works more like an immediate mode user interface11. That is, it reruns the script from top to bottom each time a UI action (e.g., button is clicked) is performed. Aggressive caching, via the @cache decorator, allows for efficient execution: only rerun the code you need to on each change. This requires the user to make those decisions, and the arguments to be hashable.
It even supports screencast recording natively! Helps with showing folks how to use what you are sharing.
This video shows the use of st.sidebar context manager: a staple for application documentation, settings, and even navigation.
This next video shows how usage of the new st.beta.expander context manager: it is fantastic especially for adding literate exposition sections that the user will want to collapse after they have read it to regain the screen real estate.
The last thing I'll highlight in the application is the usage of the new st.beta.columns context manager that was used to create a grid of word clouds for the individual topics.

Here is the code
st.subheader('Top N Topic Keywords Wordclouds')
topics = model.show_topics(formatted=False, num_topics=num_topics)
cols = st.beta_columns(3)
colors = random.sample(COLORS, k=len(topics))
for index, topic in enumerate(topics):
wc = WordCloud(font_path=WORDCLOUD_FONT_PATH, width=700, height=600, background_color='white', collocations=collocations, prefer_horizontal=1.0, color_func=lambda *args, **kwargs: colors[index])
with cols[index % 3]:
wc.generate_from_frequencies(dict(topic[1]))
st.image(wc.to_image(), caption=f'Topic #{index}', use_column_width=True)
There is a ton more to dive into here but nothing that cannot be gained from jumping in and trying something yourself.
Streamlit Sharing
The Streamlit Sharing tagline is pretty good: deploy, manage, and share your apps with the world, directly from Streamlit — all for free.
The ease of sharing a machine learning application prototype was delightful. I had originally deployed on an Amazon AWS EC2 instance to meet a deadline (viz., below). Given my background and experience with AWS I would not say it was overly difficult to deploy this way, but I know talented machine learning professionals that might have had trouble here. Moreover, most would not want to spend their time on role access, security settings, setting up DNS records, etc. And yes, their time is most definitely better spent on what they do best.
In order to use this service you need to request and be granted an account. You do that here. You will get a transactional email letting you now that you are in the queue for access, but the invite is not coming just yet. I would suggest, if you think you will want to try this out anytime soon, that you sign up right away.
Once access is granted it is pretty easy to just follow the gif above or the directions here. There are a couple of things that required me iterate on my github repository to get everything working including
- Using setup.py / setup.cfg correctly means you do not need a requirements.txt file, but the service requires one
- It is common for machine learning packages to download data and models
Otherwise it was completely straight-forward and accomplished in just a couple clicks. Official guidance on deployment of Streamlit applications can be found here.
It is also important to note that this is absolutely not a replacement for production deployment. Each user is limited to 3 applications. Individual applications are limited to being run in a shared environment that can get up to 1 CPU, 800 MB of RAM, and 800 MB of dedicated storage.3 So not the right place for your next start-up's web application, but a great value proposition for sharing quick prototypes.
Wrap Up
If you have gotten this far I would like to thank you for taking the time. If on reading this you were interested enough to play around with the application and have feedback I would love to hear it.
The prototype application can be accessed on Streamlit Sharing4 and the code is available on Github5. Intention is to augment and improve what is there time permitting. Plan to get my thought for improvements and expansion into Github issues as I have time to work on them.
- Non-negative Matrix Factorization Wikipedia
- Literate Programming Wikipedia
- Streamlit Sharing Resource Limits
- Streamlit Topic Modeling Application
- Streamlit Topic Modeling Application Github Repository
- Topic Model Wikipedia
- Latent Dirichlet Allocation Wikipedia
- Unsupervised, supervised and semi-supervised learning Cross Validated Question
- pyLDAvis Github
- Termite: Visualization Techniques for Assessing Textual Topic Models
- Immediate mode GUI Wikepedia
Bio: Bryan Patrick Wood (@bpw1621)is a Senior Data Scientist, and is leading a data science team tackling some of the most important challenges facing the nation. Check out his personal website for more.
Original. Reposted with permission.
Related:
- Production-Ready Machine Learning NLP API with FastAPI and spaCy
- Learn Neural Networks for Natural Language Processing Now
- Better data apps with Streamlit’s new layout options