Topic Modeling Approaches: Top2Vec vs BERTopic
This post gives an overview of the strengths and differences of these approaches in extracting topics from text.

Photo by Mikechie Esparagoza
Every day, we are dealing most of the time with unlabeled text and supervised learning algorithms cannot be used at all to extract information from the data. A subfield of natural language can reveal the underlying structure in large amounts of text. This discipline is called Topic Modeling, that is specialized in extracting topics from text.
In this context, conventional approaches, like Latent Dirichlet Allocation and Non-Negative Matrix Factorization, demonstrated to not capture well the relationships between words since they are based on bag-of-word.
For this reason, we are going to focus on two promising approaches, Top2Vec and BERTopic, that address these drawbacks by exploiting pre-trained language models to generate topics. Let’s get started!
Top2Vec
Top2Vec is a model capable of detecting automatically topics from the text by using pre-trained word vectors and creating meaningful embedded topics, documents and word vectors.
In this approach, the procedure to extract topics can be split into different steps:
- Create Semantic Embedding: jointly embedded document and word vectors are created. The idea is that similar documents should be closer in the embedding space, while dissimilar documents should be distant between them.
- Reduce the dimensionality of the document embedding: The application of the dimensionality reduction approach is important to preserve most of the variability of the embedding of documents while reducing the high dimensional space. Moreover, it allows to identification of dense areas, in which each point represents a document vector. UMAP is the typical dimensionality reduction approach chosen in this step because it’s able to preserve the local and global structure of the high-dimensional data.
- Identify clusters of documents: HDBScan, a density-based clustering approach, is applied to find dense areas of similar documents. Each document is assigned as noise if it’s not in a dense cluster, or a label if it belongs to a dense area.
- Calculate centroids in the original embedding space: The centroid is computed by considering the high dimensional space, instead of the reduced embedding space. The classic strategy consists in calculating the arithmetic mean of all the document vectors belonging to a dense area, obtained in the previous step with HDBSCAN. In this way, a topic vector is generated for each cluster.
- Find words for each topic vector: the nearest word vectors to the document vector are semantically the most representative.
Example of Top2Vec
In this tutorial, we are going to analyze the negative reviews of McDonald's from a dataset available on data.world. Identifying the topics from these reviews can be valuable for the multinational to improve the products and the organisation of this fast food chain in the USA locations provided by the data.
import pandas as pd
from top2vec import Top2Vec
file_path = "McDonalds-Yelp-Sentiment-DFE.csv"
df = pd.read_csv(
file_path,
usecols=["_unit_id", "city", "review"],
encoding="unicode_escape",
)
df.head()
docs_bad = df["review"].values.tolist()

In a single line of code, we are going to perform all the steps of the top2vec explained previously.
topic_model = Top2Vec(
docs_bad,
embedding_model="universal-sentence-encoder",
speed="deep-learn",
tokenizer=tok,
ngram_vocab=True,
ngram_vocab_args={"connector_words": "phrases.ENGLISH_CONNECTOR_WORDS"},
)
The main arguments of Top2Vec are:
- docs_bad: is a list of strings.
- universal-sentence-encoder: is the chosen pre-trained embedding model.
- deep-learn: is a parameter that determines the quality of the produced document vector.
topic_model.get_num_topics() #3
topic_words, word_scores, topic_nums = topic_model.get_topics(3)
for topic in topic_nums:
topic_model.generate_topic_wordcloud(topic)
The most

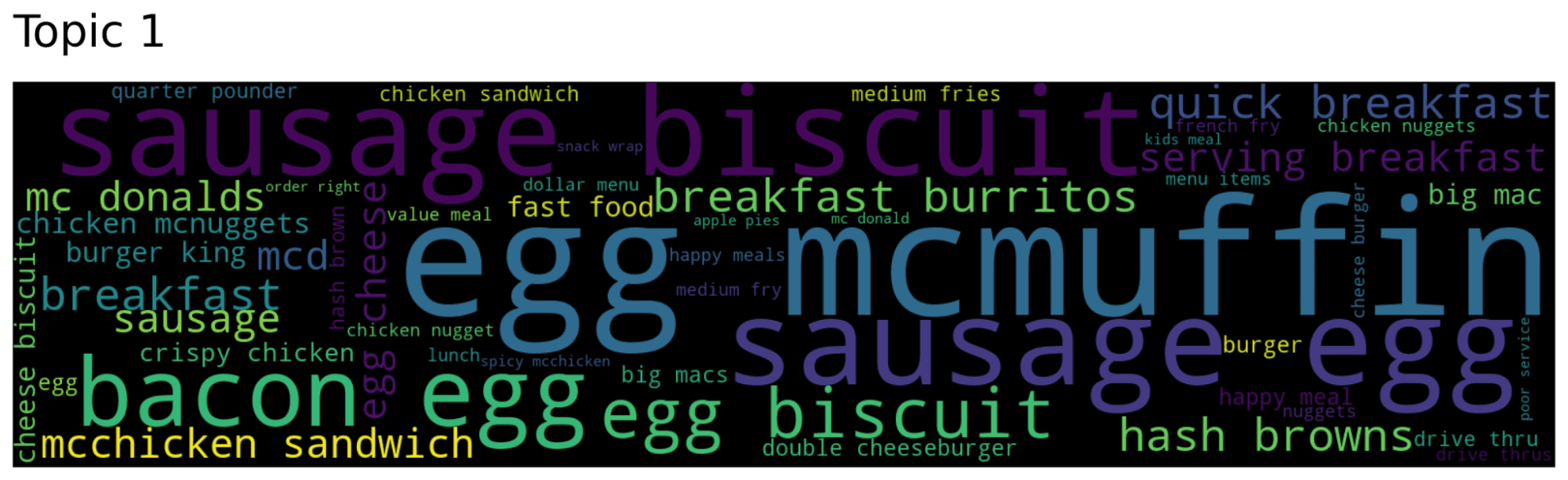

From the word clouds, we can deduce that the topic 0 is about general complaints about the service in McDonald, like “slow service”, “horrible service” and “order wrong”, while the topic 1 and 2 refer respectively to breakfast food (McMuffin, biscuit, egg) and coffee (iced coffee and cup coffee).
Now, we try to search documents using two keywords, wrong and slow:
(
documents,
document_scores,
document_ids,
) = topic_model.search_documents_by_keywords(
keywords=["wrong", "slow"], num_docs=5
)
for doc, score, doc_id in zip(documents, document_scores, document_ids):
print(f"Document: {doc_id}, Score: {score}")
print("-----------")
print(doc)
print("-----------")
print()
Output:
Document: 707, Score: 0.5517634093633295
-----------
horrible.... that is all. do not go there.
-----------
Document: 930, Score: 0.4242547340973836
-----------
no drive through :-/
-----------
Document: 185, Score: 0.39162203345993046
-----------
the drive through line is terrible. they are painfully slow.
-----------
Document: 181, Score: 0.3775083338082392
-----------
awful service and extremely slow. go elsewhere.
-----------
Document: 846, Score: 0.35400602635951994
-----------
they have bad service and very rude
-----------
BERTopic
"BERTopic is a topic modeling technique that leverages transformers and c-TF-IDF to create dense clusters allowing for easily interpretable topics whilst keeping important words in the topic descriptions."
As the name suggests, BERTopic utilises powerful transformer models to identify the topics present in the text. Another characteristic of this topic modeling algorithm is the use of a variant of TF-IDF, called class-based variation of TF-IDF.
Like Top2Vec, it doesn’t need to know the number of topics, but it automatically extracts the topics.
Moreover, similarly to Top2Vec, it is an algorithm that involves different phases. The first three steps are the same: creation of embedding documents, dimensionality reduction with UMAP and clustering with HDBScan.
The successive phases begin to diverge from Top2Vec. After finding the dense areas with HDBSCAN, each topic is tokenized into a bag-of-words representation, which takes into account if the word appears in the document or not. After the documents belonging to a cluster are considered a unique document and TF-IDF is applied. So, for each topic, we identify the most relevant words, that should have the highest c-TF-IDF.
Example of BERTopic
We repeat the analysis on the same dataset.
We are going to extract the topics from the reviews using BERTopic:
model_path_bad = 'model/bert_bad'
topic_model_bad = train_bert(docs_bad,model_path_bad)
freq_df = topic_model_bad.get_topic_info()
print("Number of topics: {}".format( len(freq_df)))
freq_df['Percentage'] = round(freq_df['Count']/freq_df['Count'].sum() * 100,2)
freq_df = freq_df.iloc[:,[0,1,3,2]]
freq_df.head()
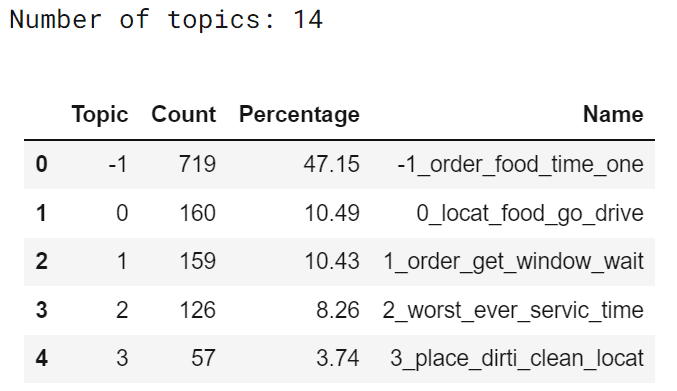
The table returned by the model provides information about the 14 topics extracted. Topic corresponds to the topic identifier, except for all the outliers that are ignored that are labeled as -1.
Now, we are going to pass to the most interesting part regarding the visualization of our topics into interactive graphs, such as the visualization of the most relevant terms for each topic, the intertopic distance map, the two-dimensional representation of the embedding space and the topic hierarchy.
Let’s begin to show the bar charts for the top ten topics. For each topic, we can observe the most important words, sorted in decreasing order based on the c-TF-IDF score. The more a word is relevant, the more the score is higher.
The first topic contains generic words, like location and food, topic 1 order and wait, topic 2 worst and service, topic 3 place and dirty, ad so on.
After visualizing the bar charts, it’s time to take a look at the intertopic distance map. We reduce the dimensionality of c-TF-IDF score into a two-dimensional space to visualize the topics in a plot. At the bottom, there is a slider that allows selecting the topic that will be coloured in red. We can notice that the topics are grouped in two different clusters, one with generic thematics like food, chicken and location, and one with different negative aspects, such as worst service, dirty, place and cold.
The next graph permits to see the relationship between the reviews and the topics. In particular, it can be useful to understand why a review is assigned to a specific topic and is aligned with the most relevant words found. For example, we can focus on the red cluster, corresponding to topic 2 with some words about the worst service. The documents within this dense area seem quite negative, like “Terrible customer service and even worse food”.
Differences between TopVec and BERTopic
At first sight, these approaches have many aspects in common, like finding automatically the number of topics, no necessity of pre-processing in most of cases, the application of UMAP to reduce the dimensionality of document embeddings and, then, HDBSCAN is used for modelling these reduced document embeddings, but they are fundamentally different when looking at the way they assign the topics to the documents.
Top2Vec creates topic representations by finding words located close to a cluster’s centroid.
Differently from Top2Vec, BERTopic doesn’t take into account the cluster’s centroid, but it considered all the documents in a cluster as a unique document and extracts topic representations using a class-based variation of TF-IDF.
| Top2Vec | BERTopic |
| The strategy to extract topics based on cluster’s centroids. | The strategy to extract topics based on c-TF-IDF. |
| It doesn’t support Dynamic Topic Modeling. | It supports Dynamic Topic Modeling. |
| It builds word clouds for each topic and provides searching tools for topics, documents and words. | It allows for building Interactive visualization plots, allowing to interpretation of the extracted topics. |
Endnotes
The Topic Modeling is a growing field of Natural Language Processing and there are numerous possible applications, like reviews, audio and social media posts. As it has been shown, this article provides an overviews of Topi2Vec and BERTopic, that are two promising approaches, that can help you to identify topics with few lines of code and interpret the results through data visualizations. If you have questions about these techniques or you have other suggestions about other approaches to detect topics, write it in the comments.
Eugenia Anello is currently a research fellow at the Department of Information Engineering of the University of Padova, Italy. Her research project is focused on Continual Learning combined with Anomaly Detection.