Stop Hard Coding in a Data Science Project – Use Config Files Instead
How to efficiently interact with config files in Python.
Problem
In your data science project, certain values tend to change frequently, such as file names, selected features, train-test split ratio, and hyperparameters for your model.

It is okay to hard-code these values when writing ad-hoc code for hypothesis testing or demonstration purposes. However, as your code base and team expand, it becomes essential to avoid hard-coding because it can give rise to various issues:
- Maintainability: If values are scattered throughout the codebase, updating them consistently becomes harder. This can lead to errors or inconsistencies when values must be updated.
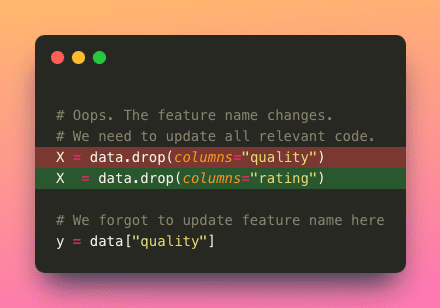
- Reusability: Hardcoding values limits the reusability of code for different scenarios.

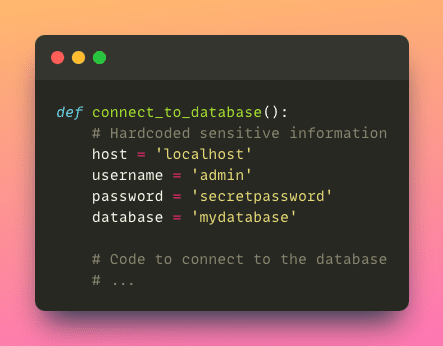
- Security concerns: Hardcoding sensitive information like passwords or API keys directly into the code can be a security risk. If the code is shared or exposed, it could lead to unauthorized access or data breaches.
- Testing and debugging: Hardcoded values can make testing and debugging more challenging. If values are hard-wired into the code, it becomes difficult to simulate different scenarios or test edge cases effectively.

Solution – Configuration Files
Configuration files solve these problems by offering the following benefits:
- Separation of configuration from code: A config file allows you to store parameters separately from the code, which improves code maintainability and readability.
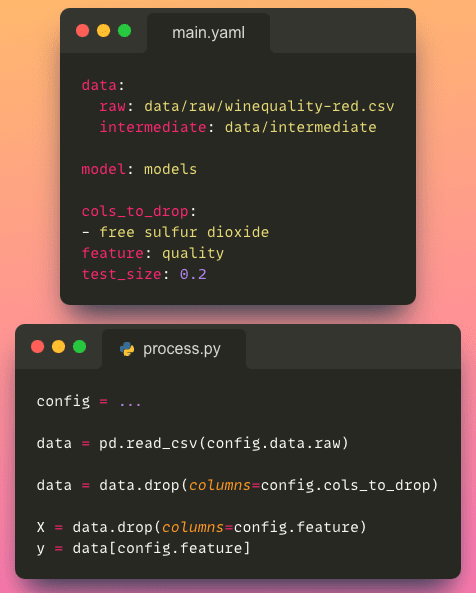
- Flexibility and modifiability: With a config file, you can easily modify project configurations without modifying the code itself. This flexibility allows for quick experimentation, parameter tuning, and adapting the project to different scenarios or environments.
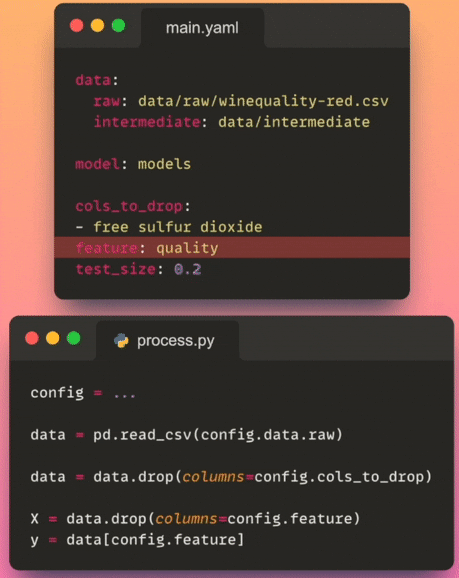
- Version control: Storing the config file in version control allows you to track changes to the configuration over time. This helps maintain a historical record of the project’s configurations and facilitates collaboration among team members.

- Deployment and productionization: When deploying a data science project to a production environment, a config file enables easy customization of settings specific to the production environment without the need for code modifications. This separation of configuration from code simplifies the deployment process.
Introduction to Hydra
Among the numerous Python libraries available for creating configuration files, Hydra stands out as my preferred configuration management tool because of its impressive set of features, including:
- Convenient parameter access
- Command-line configuration override
- Composition of configurations from multiple sources
- Execution of multiple jobs with different configurations
Let’s dig deeper into each of these features.
Feel free to play and fork the source code of this article here:
Convenient parameter access
Suppose all configuration files are stored under the conf folder and all Python scripts are stored under the src folder.
.
├── conf/
│ └── main.yaml
└── src/
├── __init__.py
├── process.py
└── train_model.py
And the main.yaml file looks like this:

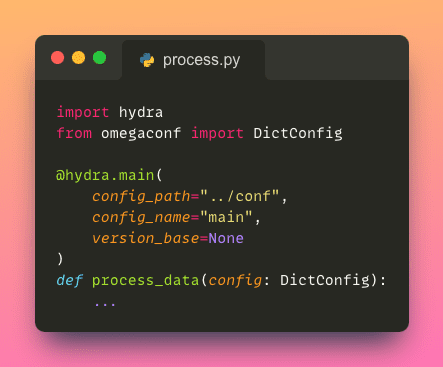
Accessing a configuration file within a Python script is as simple as applying a single decorator to your Python function.
To access a specific parameter from the configuration file, we can use the dot notation (.e.g., config.process.cols_to_drop), which is a cleaner and more intuitive way compared to using brackets (e.g., config['process']['cols_to_drop']).
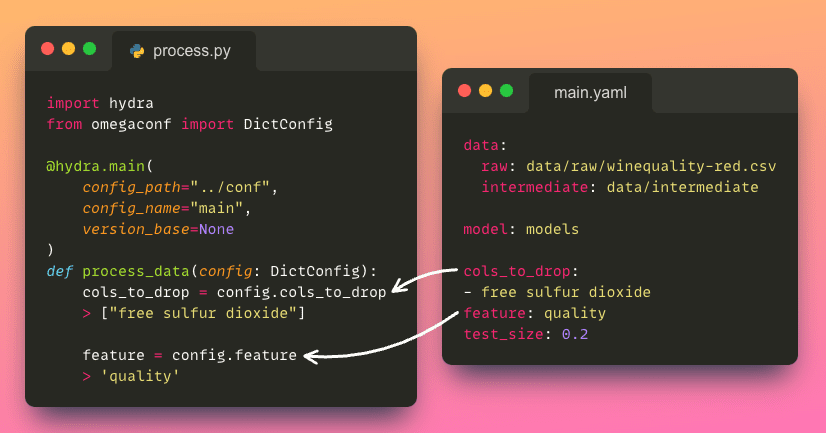
This straightforward approach allows you to effortlessly retrieve the desired parameters.
Command-line configuration override
Let’s say you are experimenting with different test_size. It is time-consuming to repeatedly open your configuration file and modify the test_size value.

Luckily, Hydra makes it easy to directly overwrite configuration from the command line. This flexibility allows for quick adjustments and fine-tuning without modifying the underlying configuration files.

Composition of configurations from multiple sources
Imagine you want to experiment with various combinations of data processing methods and model hyperparameters. While you could manually edit the configuration file each time you run a new experiment, this approach can be time-consuming.

Hydra enables the composition of configurations from multiple sources with config groups. To create a config group for data processing, create a directory called process to hold a file for each processing method:
.
└── conf/
├── process/
│ ├── process1.yaml
│ └── process2.yaml
└── main.yaml

If you want to use the process1.yaml file by default, add it to Hydra’s default list.

Follow the same procedures to create a config group for training hyperparameters:
.
└── conf/
├── process/
│ ├── process1.yaml
│ └── process2.yaml
├── train/
│ ├── train1.yaml
│ └── train2.yaml
└── main.yaml

Set train1 as the default config file:

Now running the application will use the parameters in process1.yaml file and model1.yaml file by default:

This capability is particularly useful when different configuration files need to be combined seamlessly.
Multi-run
Suppose you want to conduct experiments with multiple processing methods, applying each configuration one by one can be a time-consuming task.

Luckily, Hydra allows you to run the same application with different configurations simultaneously.
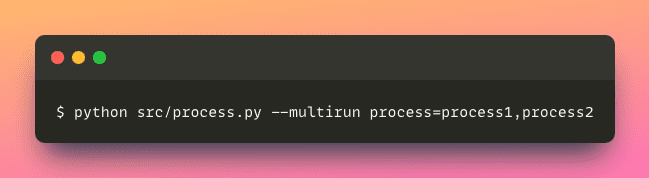
This approach streamlines the process of running an application with various parameters, ultimately saving valuable time and effort.
Conclusion
Congratulations! You have just learned about the importance of using configuration files and how to create ones using Hydra. I hope this article will give you the knowledge needed to create your own configuration files.
Khuyen Tran is a prolific data science writer, and has written an impressive collection of useful data science topics along with code and articles. Khuyne is currently looking for a machine learning engineer role, a data scientist role, or a developer advocate role in Bay Area after May 2022, so please reach out if you are looking for someone with her set of skills.
Original. Reposted with permission.