The Significance of Data Quality in Making a Successful Machine Learning Model
Good quality data becomes imperative and a basic building block of an ML pipeline. The ML model can only be as good as its training data.

Source: Business photo created by frimufilms - www.freepik.com
Introduction
AI has been a buzzword for quite some time now and is highly ubiquitous. The AI-enabled applications have extensively increased in the market. We have also been ‘blessed’ with powerful infrastructure and advanced algorithms. However, that does not make the journey of taking your ML project to production any easy.

Source: Chat bot vector created by roserodionova - www.freepik.com
The issue in data quality is not new, it has gained attention since the onset of machine learning (ML) applications.
The machine learns the statistical associations from the historical data and is as good as the data it is trained on. Hence, good quality data becomes imperative and a basic building block of an ML pipeline. The ML model can only be as good as its training data.
Data-centric vs Algorithm-centric
Let me share two scenarios with you - Let's assume you have done initial exploratory data analysis and are very excited to see the model performance. But to your disappointment (which happens every now and then in a data scientist’s life :)), the model’s results are not good enough to be acceptable by the business. In this case, considering the repetitive nature of the data science world, what would be your next steps:
- Analyze the wrong predictions and associate them with their input data to investigate possible anomalies and previously ignored data patterns.
- Or, you would take a forward-looking approach and simply advance to more complex algorithms.
Simply put, the typical practice of resorting to more advanced ML algorithms to gain more accuracy will not yield much good if the data does not provide a good signal to the machine. This is very well articulated in Andrew Ng’s lecture on “MLOps: From Model-centric to Data-centric AI”.
Data Quality Assessment
The machine learning algorithms need training data in a single view i.e. a flat structure. As most organizations maintain multiple sources of data, the data preparation by combining multiple data sources to bring all necessary attributes in a single flat file is a time and resource (domain expertise) expensive process.
The data gets exposed to multiple sources of error at this step and requires strict peer review to ensure that the domain-established logic has been communicated, understood, programmed, and implemented well.
Since data warehouses integrate data from multiple sources, quality issues related to data acquisition, cleaning, transformations, linking, and integration become critical.
A very popular notion among most the data scientists is that the data preparation, cleaning, and transformation take up the majority of the model building time – and it is an absolute truth. Hence, it is advised not to rush through the data to feed into the model and perform extensive data quality checks. Though the number and type of checks one can perform on the data can be very subjective, we will discuss some of the key factors to be checked in the data while preparing data quality score and assessing the goodness of data:
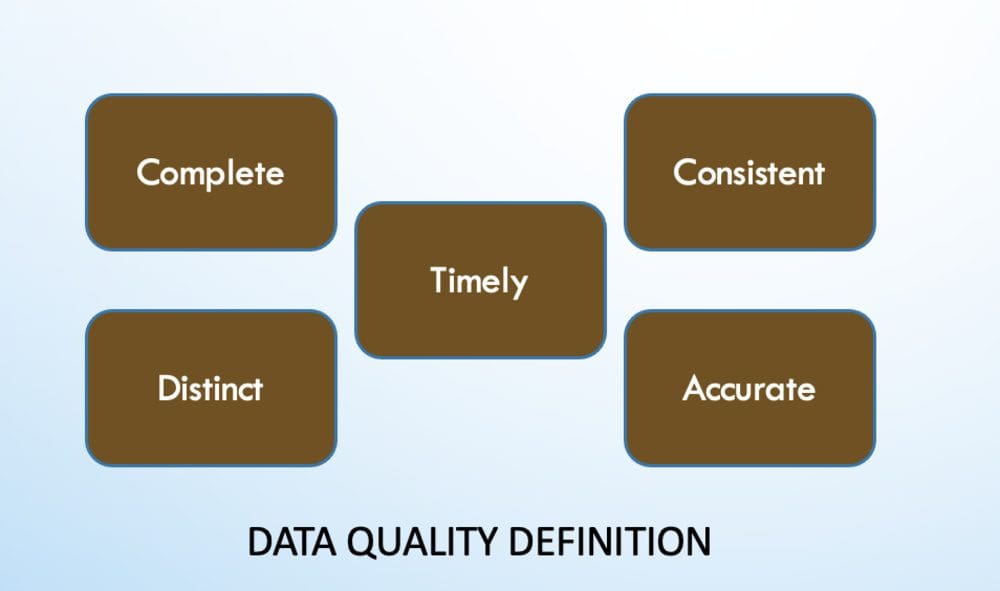
Techniques to maintain data quality:
- missing data imputation
- outlier detection
- data transformations
- dimensionality reduction
- cross-validation
- bootstrapping
Quality, Quality, Quality
Let’s check how we can improve the data quality:
-
- All labelers are not the same: Data is gathered from multiple sources. Multiple vendors have different approaches to collecting and labeling data with a different understanding of the end-use of the data. Within the same vendor for data labeling, there are myriad ways data inconsistency can crop up as the supervisor gets requirements and shares the guidelines to different team members, all of whom can label based on their understanding.
- A quality check on the vendor side, validation of adherence to the shared guidelines at the consumer side will help bring homogenous labeling.
- Distinct Record: Identifying the group of attributes that uniquely identify a single record is very important and needs validation from a domain expert. Removing duplicates on this group leaves you with distinct records necessary for model training. This group acts as a key to performing multiple aggregate and transformations operations on the dataset like calculating rolling mean, backfilling null values, missing value imputation (details on this in next point), etc.
- What to do with the missing data? Systematic missingness of data leads to the origin of a biased dataset and calls for deeper investigation. Also, removing the observations from the data with more null/missing values can lead to the elimination of data representing certain groups of people (e.g. gender, or race). Hence, misrepresented data will produce biased results and is not only flawed at the model output level but is also against the fairness principles of ethical and responsible use of AI. Another way you may find the missing attributes is “at random”. Blindly removing a certain important attribute due to a high missingness quotient can harm the model by reducing its predictive power.
- The most common way to impute missing values is by mean values at a particular dimension level. For example, the average number of conversions from the Delhi to Bengaluru route can be used to impute the missing value of the conversions for the route on a given day. To add on to a similar note, one may calculate the average of all high-running routes like Delhi to Mumbai, Delhi to Kolkata, Delhi to Chennai for imputing missing conversions value.
- All labelers are not the same: Data is gathered from multiple sources. Multiple vendors have different approaches to collecting and labeling data with a different understanding of the end-use of the data. Within the same vendor for data labeling, there are myriad ways data inconsistency can crop up as the supervisor gets requirements and shares the guidelines to different team members, all of whom can label based on their understanding.
- Flattened Structure: Most organizations do not have a centralized data warehouse and encounter a lack of structured data as one of the key problems in preparing the machine learning model for decision-making. For example, cybersecurity solutions need data from multiple resources like network, cloud, and endpoint to be normalized into one single view to training the algorithm on previously seen attacks/threats.
Benefits of Good Quality Data
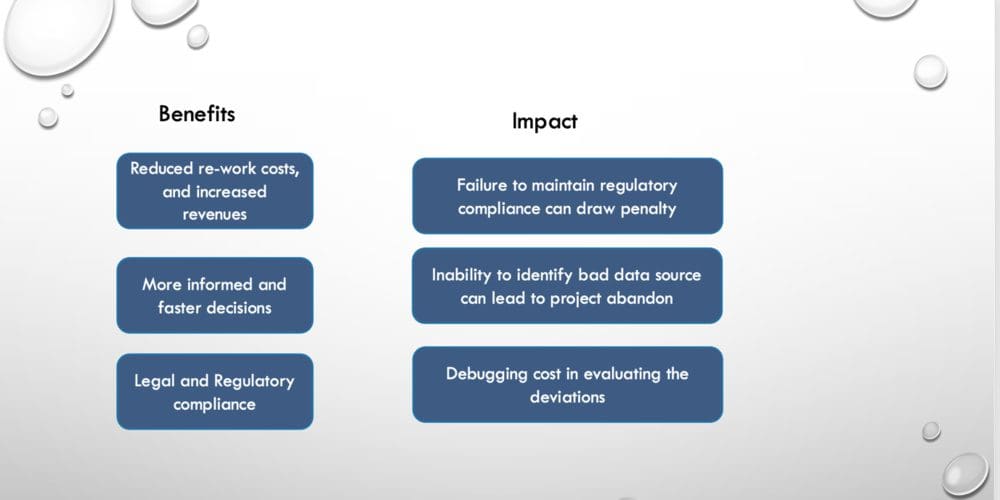
Understand Your Data at Scale
Now, that we have discussed some key areas where data quality can degrade, let's see how you can use TensorFlow data validation to understand your data at scale:
- TFDV gives descriptive analysis and shows the statistical distribution of the data - mean, min, max, standard deviation, etc.
- Understanding the data schema is very critical - the features, their values, and data types
- Once you have understood your baseline data distribution, it is important to keep a tab on anomalous behavior. TFDV highlights out of domain value thereby guiding to detect of the error.
- It shows the drift between train and test data by overlying their distributions.
TensorFlow’s documentation has illustrated how to use TFDV to analyze the data and improve its quality. I would highly recommend trying using the TFDV code available in colab on your dataset.
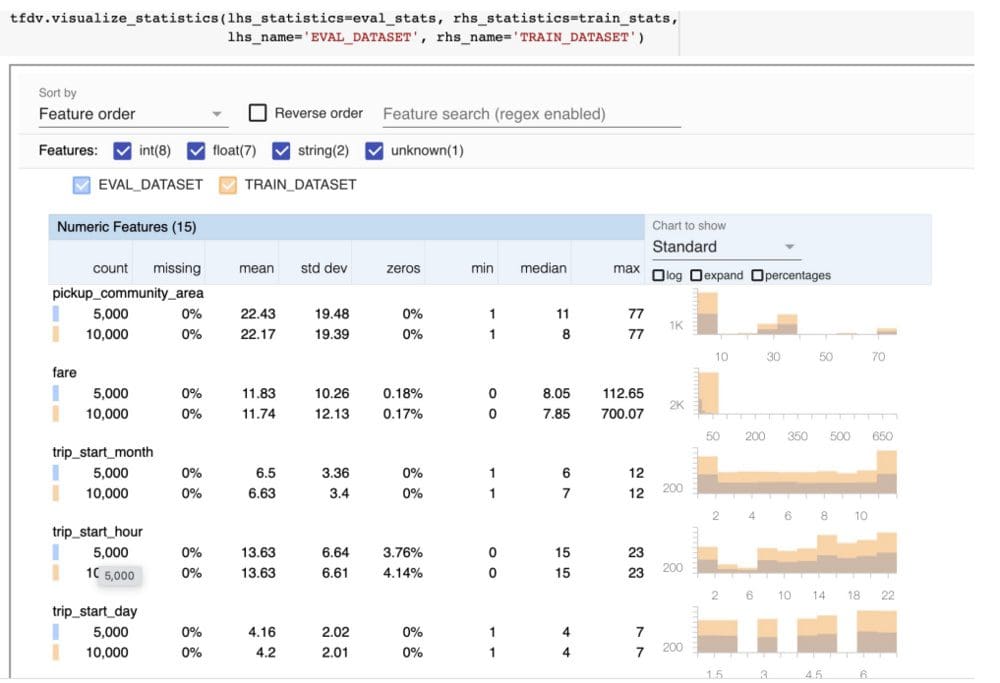
Statistical analysis of numerical and categorical data on taxi data is shown below:
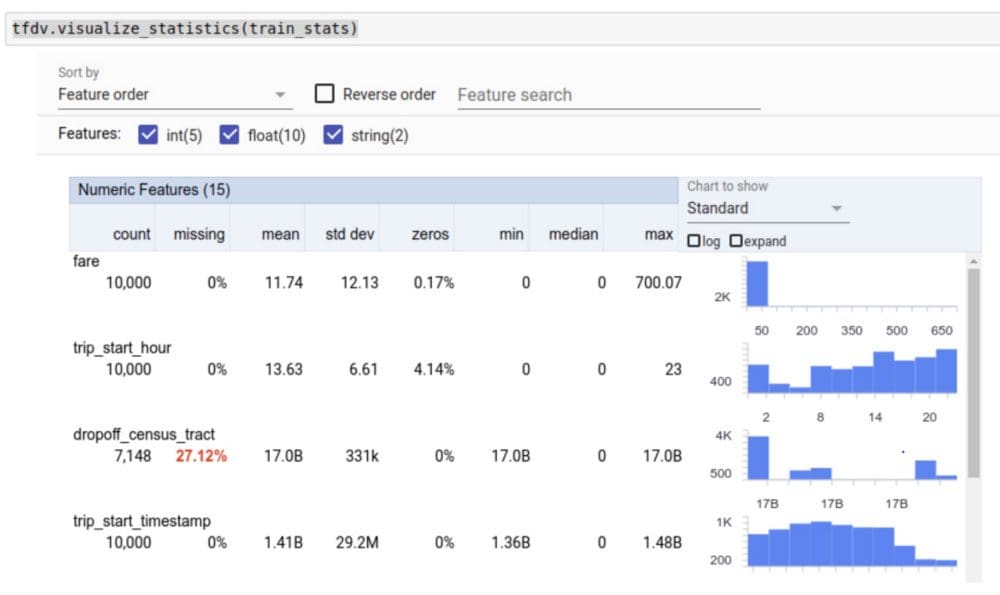
The total count, % of records with missing value along visualization on the right helps in better understanding of the data.
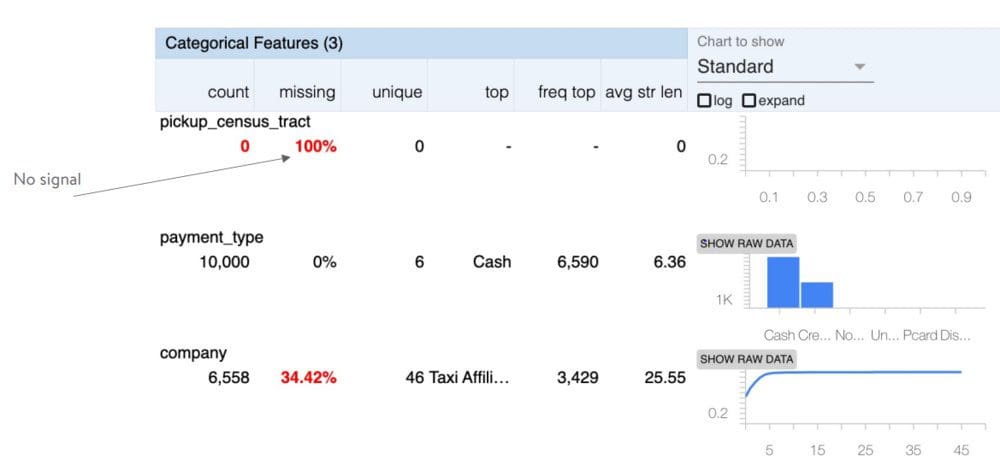
The pickup_census_tract is having all records with missing values and hence contains no signal for the ML algorithm to learn more. It can be filtered out based on this EDA.
Data Drift: It is the most crucial part of the deployed model pipeline and can happen between training and test data over time, or between multiple days of training data as well.
ML algorithms perform under the assumption that train and test data have similar characteristics, violation of this assumption will lead to model performance degradation.
Google has shared the code in this Colab notebook.
Looking forward to hearing some of your best practices of maintaining and working with quality data.
References
Get started with Tensorflow Data Validation
Vidhi Chugh is an award-winning AI/ML innovation leader and an AI Ethicist. She works at the intersection of data science, product, and research to deliver business value and insights. She is an advocate for data-centric science and a leading expert in data governance with a vision to build trustworthy AI solutions.