Segment Anything Model: Foundation Model for Image Segmentation
Understanding Meta AI Latest Universal Segmentation Model.
Segmentation, the process of identifying image pixels that belong to objects, is at the core of computer vision. This process is used in applications from scientific imaging to photo editing, and technical experts must possess both highly skilled abilities and access to AI infrastructure with large quantities of annotated data for accurate modeling.
Meta AI recently unveiled its Segment Anything project? which is ?an image segmentation dataset and model with the Segment Anything Model (SAM) and the SA-1B mask dataset?—?the largest ever segmentation dataset support further research in foundation models for computer vision. They made SA-1B available for research use while the SAM is licensed under Apache 2.0 open license for anyone to try SAM with your images using this demo!

Segment Anything Model / Image by Meta AI
Toward Generalizing the Segmentation Task
Before, segmentation problems were approached using two classes of approaches:
- Interactive segmentation in which the users guide the segmentation task by iteratively refining a mask.
- Automatic segmentation allowed selective object categories like cats or chairs to be segmented automatically but it required large numbers of annotated objects for training (i.e. thousands or even tens of thousands of examples of segmented cats) along with computing resources and technical expertise to train a segmentation model neither approach provided a general, fully automatic solution to segmentation.
SAM uses both interactive and automatic segmentation in one model. The proposed interface enables flexible usage, making a wide range of segmentation tasks possible by engineering the appropriate prompt (such as clicks, boxes, or text).
SAM was developed using an expansive, high-quality dataset containing more than one billion masks collected as part of this project, giving it the capability of generalizing to new types of objects and images beyond those observed during training. As a result, practitioners no longer need to collect their segmentation data and tailor a model specifically to their use case.
These capabilities enable SAM to generalize both across tasks and domains something no other image segmentation software has done before.
SAM Capabilities & Use Cases
SAM comes with powerful capabilities that make the segmentation task more effective:
- Variety of input prompts: Prompts that direct segmentation allow users to easily perform different segmentation tasks without additional training requirements. You can apply segmentation using interactive points and boxes, automatically segment everything in an image, and generate multiple valid masks for ambiguous prompts. In the figure below we can see the segmentation is done for certain objects using an input text prompt.

Bounding box using text prompt.
- Integration with other systems: SAM can accept input prompts from other systems, such as in the future taking the user's gaze from an AR/VR headset and selecting objects.
- Extensible outputs: The output masks can serve as inputs to other AI systems. For instance, object masks can be tracked in videos, enabled imaging editing applications, lifted into 3D space, or even used creatively such as collating
- Zero-shot generalization: SAM has developed an understanding of objects which allows him to quickly adapt to unfamiliar ones without additional training.
- Multiple mask generation: SAM can produce multiple valid masks when faced with uncertainty regarding an object being segmented, providing crucial assistance when solving segmentation in real-world settings.
- Real-time mask generation: SAM can generate a segmentation mask for any prompt in real time after precomputing the image embedding, enabling real-time interaction with the model.
Understanding SAM: How Does It Work?
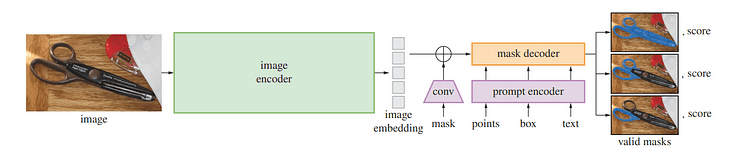
Overview of SAM model / Image by Segment Anything
One of the recent advances in natural language processing and computer vision has been foundation models that enable zero-shot and few-shot learning for new datasets and tasks through “prompting”. Meta AI researchers trained SAM to return a valid segmentation mask for any prompt, such as foreground/background points, rough boxes/masks or masks, freeform text, or any information indicating the target object within an image.
A valid mask simply means that even when the prompt could refer to multiple objects (for instance: one point on a shirt may represent both itself or someone wearing it), its output should provide a reasonable mask for one object only?—?thus pre-training the model and solving general downstream segmentation tasks via prompting.
The researchers observed that pretraining tasks and interactive data collection imposed specific constraints on model design. Most significantly, real-time simulation must run efficiently on a CPU in a web browser to allow annotators to use SAM interactively in real-time for efficient annotation. Although runtime constraints resulted in tradeoffs between quality and runtime constraints, simple designs produced satisfactory results in practice.
Underneath SAM’s hood, an image encoder generates a one-time embedding for images while a lightweight encoder converts any prompt into an embedding vector in real-time. These information sources are then combined by a lightweight decoder that predicts segmentation masks based on image embeddings computed with SAM, so SAM can produce segments in just 50 milliseconds for any given prompt in a web browser.
Building SA-1B: Segmenting 1 Billion Masks
Building and training the model requires access to an enormous and diverse pool of data that did not exist at the start of training. Today’s segmentation dataset release is by far the largest to date. Annotators used SAM interactively annotate images before updating SAM with this new data?—?repeating this cycle many times to continuously refine both the model and dataset.
SAM makes collecting segmentation masks faster than ever, taking only 14 seconds per mask annotated interactively; that process is only two times slower than annotating bounding boxes which take only 7 seconds using fast annotation interfaces. Comparable large-scale segmentation data collection efforts include COCO fully manual polygon-based mask annotation which takes about 10 hours; SAM model-assisted annotation efforts were even faster; its annotation time per mask annotated was 6.5x faster versus 2x slower in terms of data annotation time than previous model assisted large scale data annotations efforts!
Interactively annotating masks is insufficient to generate the SA-1B dataset; thus a data engine was developed. This data engine contains three “gears”, starting with assisted annotators before moving onto fully automated annotation combined with assisted annotation to increase the diversity of collected masks and finally fully automatic mask creation for the dataset to scale.
SA-1B’s final dataset features more than 1.1 billion segmentation masks collected on over 11 million licensed and privacy-preserving images, making up 4 times as many masks than any existing segmentation dataset, according to human evaluation studies. As verified by these human assessments, these masks exhibit high quality and diversity compared with previous manually annotated datasets with much smaller sample sizes.
Images for SA-1B were obtained via an image provider from multiple countries that represented different geographic regions and income levels. While certain geographic regions remain underrepresented, SA-1B provides greater representation due to its larger number of images and overall better coverage across all regions.
Researchers conducted tests aimed at uncovering any biases in the model across gender presentation, skin tone perception, the age range of people as well as the perceived age of persons presented, finding that the SAM model performed similarly across various groups. They hope this will make the resulting work more equitable when applied in real-world use cases.
While SA-1B enabled the research output, it can also enable other researchers to train foundation models for image segmentation. Furthermore, this data may become the foundation for new datasets with additional annotations.
Future Work & Summary
Meta AI researchers hope that by sharing their research and dataset, they can accelerate the research in image segmentation and image and video understanding. Since this segmentation model can perform this function as part of larger systems.
In this article, we covered what is SAM and its capability and use cases. After that, we went through how it works, and how it was trained so as to give an overview of the model. Finally, we conclude the article with the future vision and work. If you would like to know more about SAM make sure to read the paper and try the demo.
References
- Introducing Segment Anything: Working toward the first foundation model for image segmentation
- SA-1B Dataset
- Segment Anything
Youssef Rafaat is a computer vision researcher & data scientist. His research focuses on developing real-time computer vision algorithms for healthcare applications. He also worked as a data scientist for more than 3 years in the marketing, finance, and healthcare domain.