Scalable Select of Random Rows in SQL
Performance boosts are achieved by selecting random rows or the sampling technique. Let’s learn how to select random rows in SQL.
By Pavel Tiunov, Statsbot

If you’re new to the big data world and also migrating from tools like Google Analytics or Mixpanel for your web analytics, you probably noticed performance differences. Google Analytics can show you predefined reports in seconds, while the same query for the same data in your data warehouse can take several minutes or even more. Such performance boosts are achieved by selecting random rows or the sampling technique. Let’s learn how to select random rows in SQL.
Sample and Population
Before we start to work on sampling implementation, it is worth mentioning some sampling fundamentals. Sampling is based on a subset selection of individuals from some population to describe this population’s properties. So if you have some event data, you can select a subset of unique users and their events to calculate metrics that describe all users’ behavior. On the other hand, if you select a subset of events, it won’t describe the behavior of the population precisely.
Given this fact, we assume all data sets to which sampling is applied have unique user identifiers. Moreover, if you have both anonymous user identifiers and authorized user identifiers, we assume using the last one as it delivers more accurate results.
Selecting Random Rows in SQL
There’re plenty of different methods you can use to select a subset of users. We’ll consider only two of those as the most obvious and simple to implement: simple random sampling and systematic sampling.
Simple random sampling can be implemented as giving a unique number to each user in a range from 0 to N-1 and then selecting X random numbers from 0 to N-1. N denotes the total number of users here and X is the sample size. Although this method is very simple for understanding, it’s a little bit tricky to implement in an SQL environment, mostly because random number generator outputs don’t scale very well when sample sizes are equal to billions. Also it isn’t very clear as to how to get evenly distributed samples over time.
Bearing this in mind, we’ll use systematic sampling which can overcome these obstacles from an SQL implementation perspective. Simple systematic sampling may be implemented as selecting one user from each M users at a specified interval. In this case, sample size will be equal to N / M. Selecting one user out of M while preserving uniform distribution across sample buckets is the main challenge of this approach. Let’s see how this can be implemented in SQL.
Sequence Generated User Identifiers
You’re lucky if your user IDs are integers generated as a strict sequence without gaps like those generated by AUTO_INCREMENT primary key fields. In this case, you can implement systematic sampling as simple as:
select * from events where ABS(MOD(user_id, 10)) = 7
This SQL query and all SQL queries below are in Standard BigQuery SQL. In this example, we’re selecting one user out of 10, which is a 10% sample. 7 is the random number of the sampling bucket and it can be any number from 0 to 9. We use MOD operation to create sampling buckets which stand for the remainder of a division by 10 in this particular case. It’s really simple to show that if user_idis a strict integer sequence, then user counts are uniformly distributed across all sampling buckets when user count is high enough.
To estimate the event count, for example, you can write something like:
select count(*) * 10 as events_count from events where ABS(MOD(user_id, 10)) = 7
Please note the multiplication by 10 in this query. Given the fact that we use a 10% sample, all estimated additive measures should be scaled by 1/10% in order to match real values.
One can question how precise this sampling approach is for a specific dataset. You can estimate it by checking how uniform the distribution is within sampling buckets. To do that you can query something like:
select ABS(MOD(user_id, 10)), count(distinct user_id) from events GROUP BY 1
Let’s consider some example results of this query:
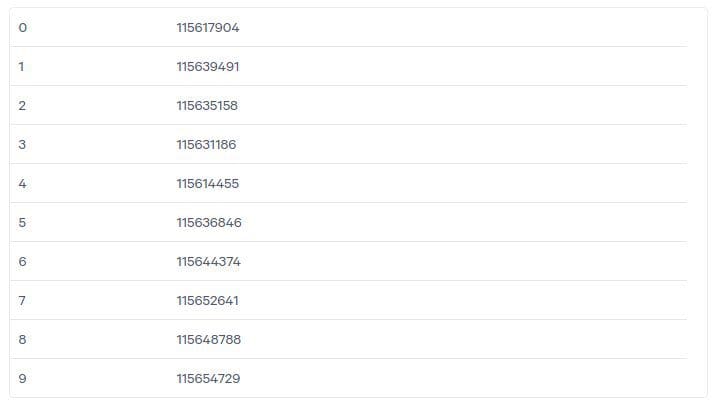
We can calculate the mean and confidence interval for an alpha coefficient equal to 0.01 for these sampling bucket sizes. The confidence interval will be equal to 0.01% of the sampling bucket average size. This means that with 99% probability the sampling bucket sizes differ not more than 0.01%. Different metrics calculated with these sampling buckets couple with this statistic but don’t inherit it. So, in order to calculate precision for event count estimation, you can calculate the event count for each sample as:
select ABS(MOD(user_id, 10)), count(*) * 10 from events GROUP BY 1
Then calculate absolute and relative confidence intervals for these event counts as in the case of user count to get event count estimate precision.
String Identifiers and Other User Identifiers
In the case that you have string user identifiers or integers, but not a strict sequence instead of integer sequence identifiers, you need a way to distribute all user IDs between different sampling buckets in a uniform manner. This can be done by hash functions. Not all hash functions can get you uniform distribution under different circumstances. You can check smhasher test suite results to check how good a particular hash function is at this.
For example, in BigQuery you can use the FARM_FINGERPRINT hash function to prepare a sample for select:
select * from events where ABS(MOD(FARM_FINGERPRINT(string_user_id), 10)) = 7
FARM_FINGERPRINT can be replaced with any suitable hash function, such as xxhash64 in Presto or even the combination of md5 and strtol in Redshift.
As in the case of sequence-generated user identifiers you can check uniformity statistics as:
select ABS(MOD(FARM_FINGERPRINT(string_user_id), 10)), count(distinct string_user_id) from events GROUP BY 1
Common Pitfalls
Most often, sampling can reduce your SQL query execution time by more than 5-10 times without being harmful in terms of precision, but there are still cases where you should be cautious. This mostly belongs to a sampling bias problem because of sample size. It can occur when dispersion of metrics you’re interested in between samples is too high even if the sample size is big enough.
For example, you can be interested in some rare event count such as an enterprise demo request being some B2C site with a huge amount of traffic. If the enterprise demo request count is about 100 events per month and your monthly active users is about 1M, then sampling can lead you in a situation where the enterprise demo request count estimate with a 10% sample produces significant errors. Generally speaking, sampling random rows in SQL should be avoided in this case or more sophisticated methods should be used instead.
As always don’t hesitate to leave your comments or contact our team to get help.
Original. Reposted with permission.
Related:
- Calculating Customer Lifetime Value: SQL Example
- SQL Window Functions Tutorial for Business Analysis
- A Guide for Customer Retention Analysis with SQL