 How I Redesigned over 100 ETL into ELT Data Pipelines
How I Redesigned over 100 ETL into ELT Data PipelinesBy Nicholas Leong, Data Engineer, Writer
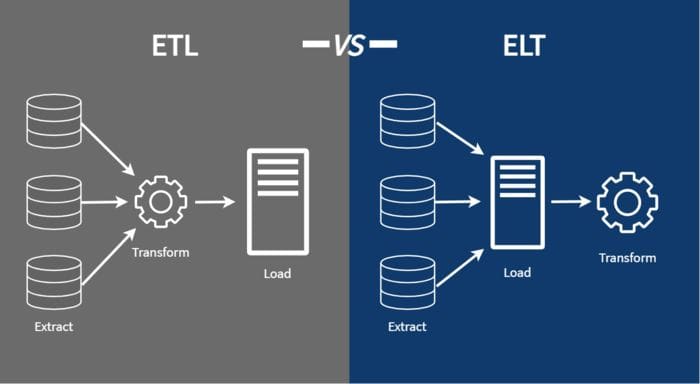
Image by Author
Everyone: What do Data Engineers do?
Me: We build pipelines.
Everyone: You mean like a plumber?
Something like that, but instead of water flowing through pipes, data flows through our pipelines.
Data Scientists build models and Data Analysts communicate data to stakeholders. So, what do we need Data Engineers for?
Little do they know, without Data Engineers, models won’t even exist. There won’t be any data to be communicated. Data Engineers build warehouses and pipelines to allow data to flow through the organization. We connect the dots.
Should You Become a Data Engineer in 2021?
Data Engineer is the fastest-growing job in 2019, growing by 50% YoY, which is higher than the job growth of Data Scientist, amounting to 32% YoY.
Hence, I’m here to shed some light on some of the day-to-day tasks a Data Engineer gets. Data Pipelines is just one of them.
ETL/ELT Pipelines
ETL — Extract, Transform, Load
ELT — Extract, Load, Transform
What do these mean and how are they different from each other?
In the data pipeline world, there is a source and a destination. In the simplest form, the source is where Data Engineers get the data from and the destination is where they want the data to be loaded into.
More often than not, there will need to be some processing of data somewhere in between. This can be due to numerous reasons which include but are not limited to —
- The difference in types of Data Storage
- Purpose of data
- Data governance/quality
Data Engineers label the processing of data as transformations. This is where they perform their magic to transform all kinds of data into the form they intend it to be.
In ETL Data Pipelines, Data Engineers perform transformations before loading data into the destination. If there are relational transformations between tables, these happen within the source itself. In my case, the source was a Postgres Database. Hence, we performed relational joins in the source to obtain the data required, then load it into the destination.
In ELT Data Pipelines, Data Engineers load data into the destination raw. They then perform any relational transformations within the destination itself.
In this article, we will be talking about how I transformed over 100+ ETL Pipelines in my organization into ELT Pipelines, we will also go through the reasons I did it.
How I Did It
Initially, the pipelines were ran using Linux cron jobs. Cron jobs are like your traditional task schedulers, they initialize using the Linux terminal. They are the most basic way of scheduling programs without any functionalities like —
- Setting dependencies
- Setting Dynamic Variables
- Building Connections
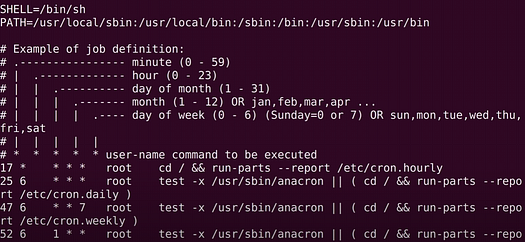
Image by Author
This was the first thing to go as it was causing way too many issues. We needed to scale. To do that, we had to set up a proper Workflow Management System.
We chose Apache Airflow. I wrote all about it here.
Data Engineering — Basics of Apache Airflow — Build Your First Pipeline
Airflow was originally built by the guys at Airbnb, made open source. It is also used by popular companies like Twitter as their Pipeline management system. You can read all about the benefits of Airflow above.
After that’s sorted out, we had to change the way we are extracting data. The team suggested redesigning our ETL pipelines into ELT pipelines. More on why did we do it later.
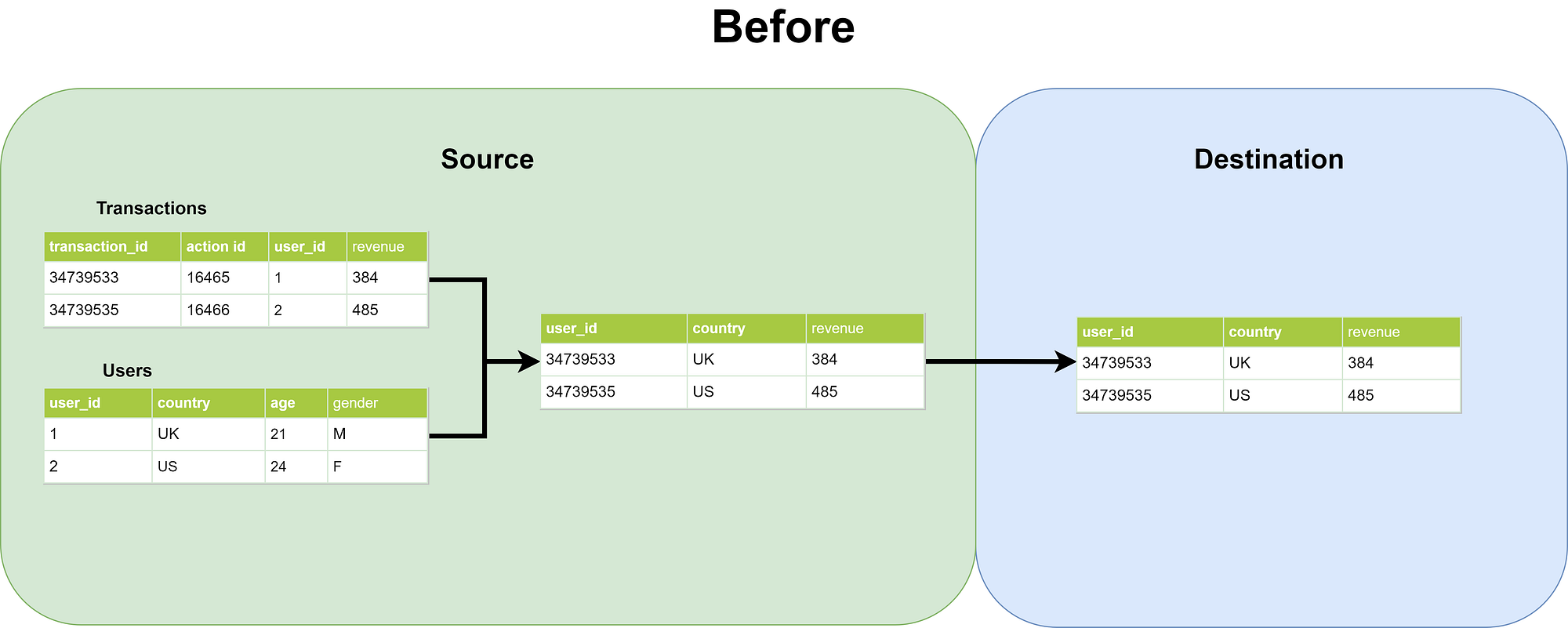
Image by Author
Here’s an example of the pipeline before it was redesigned. The source we were dealing with was a Postgres Database. Hence, to obtain data in the form intended, we had to perform joins in the source database.
Select
a.user_id,
b.country,
a.revenue
from transactions a
left join users b on
a.user_id = b.user_id
This is the query ran in the source database. Of course, I’ve simplified the examples to their dumbest form, the actual queries were over 400 lines of SQL.
The query results were saved in a CSV file and then uploaded to the destination, which is a Google Bigquery database in our case. Here’s how it looked like in Apache Airflow —
This is a simple example of an ETL pipeline. It was working as intended, but the team had realized the benefits of redesigning this into an ELT pipeline. More on that later.
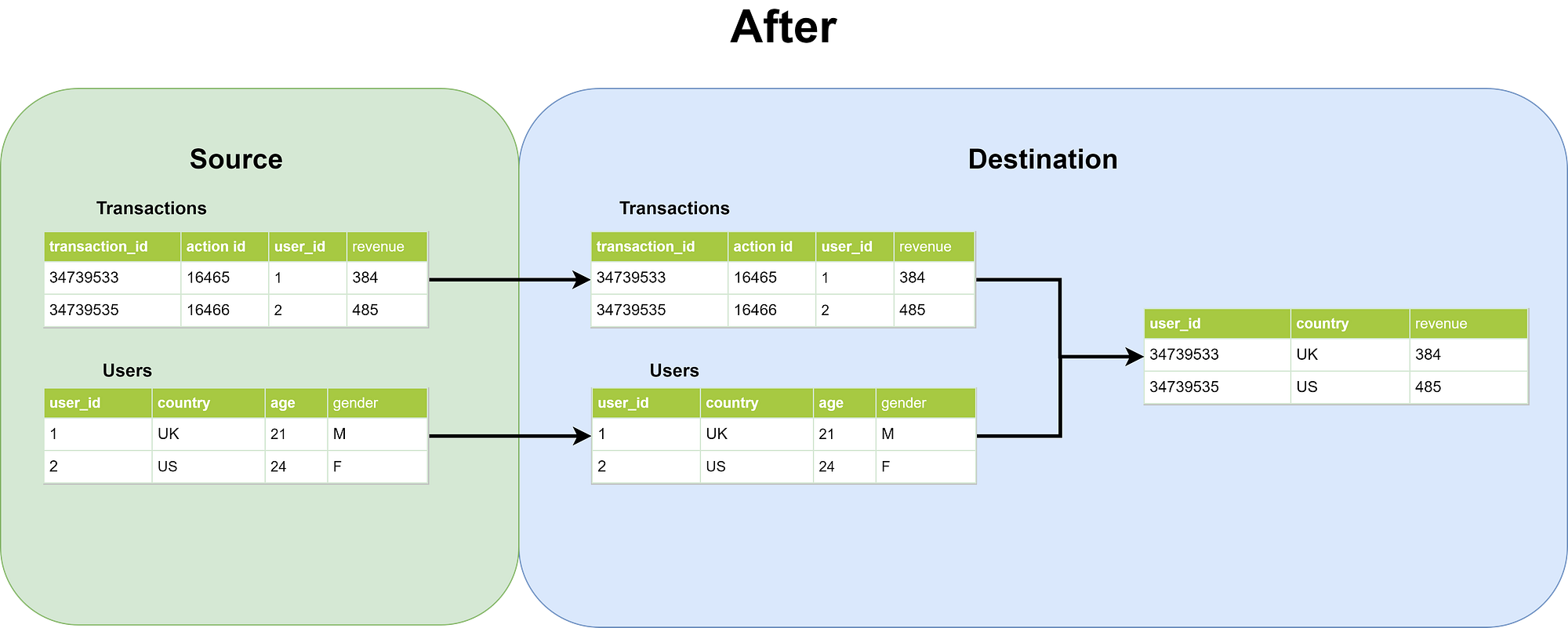
Image by Author
Here’s an example of the pipeline after it was redesigned. Observed how the tables are brought into the destination as it is. After all the tables have been successfully extracted, we perform relational transformations in the destination.
--transactions
Select
*
from transactions --
Select
*
from users
This is the query ran in the source database. Most of the extractions are using ‘Select *’ statements without any joins. For appending jobs, we include where conditions to properly segregate the data.
Similarly, the query results were saved in a CSV file and then uploaded into the Google Bigquery database. We then made a separate dag for transformation jobs by setting dependencies within Apache Airflow. This is to ensure that all the extraction jobs have been completed before running transformation jobs.
We set dependencies using Airflow Sensors. You can read about them here.
Data Engineering — How to Set Dependencies Between Data Pipelines in Apache Airflow
Why I Did it

Photo by Markus Winkler on Unsplash
Now that you understand how I did it, we move onto the why — Why exactly did we re-wrote all our ETL into ELT pipelines?
Cost
Running with our old Pipeline had cost our team resources, specifically time, effort, and money.
To understand the cost aspect of things, you have to understand that our source database (Postgres) was an ancient machine set up back in 2008. It was hosted on-prem. It was also running an old version of Postgres which makes things even complicated.
It wasn’t until recent years when the organization realize the need for a centralized data warehouse for Data Scientists and Analysts. This is when they started to build the old pipelines on cron jobs. As the number of jobs increase, it had drained resources on the machine.
The SQL joins written by the previous Data Analysts were also all over the place. There were over 20 joins in a single query in some pipelines, and we were approaching 100+ pipelines. Our tasks began running during midnight, it usually finished about 1–2 p.m., which amounted to about 12+ hours, which is absolutely unacceptable.
For those of you who don’t know, SQL joins are one of the most resource-intensive commands to run. It’ll increase the query’s runtime exponentially as the number of joins increases.

Image by Author
Since we were moving onto Google Cloud, the team understood that Google Bigquery is lightning fast in computing SQL queries. You can read all about it here.
How fast is BigQuery? | Google Cloud Blog
Hence, the whole point is to only run simple ‘Select *’ statements in the source and perform all the joins on Google Cloud.
This had more than doubled the efficiency and speed of our Data Pipelines.
Scalability
Photo by Quinten de Graaf on Unsplash
As businesses scale, so do their tools and technologies.
By moving onto Google Cloud, we can easily scale our machines and pipelines without worrying much.
Google Cloud utilizes Cloud Monitoring which is a tool that collects metrics, events, and metadata of your Google Cloud Technologies like Google Cloud Composer, Dataflow, Bigquery, and many more. You can monitor all sorts of data points which includes but are not limited to —
- Cost of Virtual Machines
- The cost of each query ran in Google Bigquery
- The size of each query ran in Google Bigquery
- Duration of Data Pipelines
This had made monitoring a breeze for us. Hence, by performing all transformations on Google Bigquery, we are able to accurately monitor our query size, duration, and cost as we scale.
Even as we increase our machine sizes, data warehouses, data pipelines, etc, we completely understand the costs and benefits that come with it and have full control of turning it on and off if needed.
This had and will save us from a lot of headaches.
Conclusion
Photo by Fernando Brasil on Unsplash
If you’ve read until this point, you must really have a thing for data.
You should!
We’ve already made ETLs and ELTs. Who knows what kind of pipelines we will be building in the future?
In this article, we talked about —
- What are ELT/ETL Data Pipelines?
- How I redesigned ETL to ELT Pipelines
- Why I did it
As usual, I end with a quote.
Data is the new science. Big Data holds the answers
—Pet Gelsinger
Subscribe to my newsletter to stay in touch.
You can also support me by signing up for a medium membership through my link. You will be able to read an unlimited amount of stories from me and other incredible writers!
I am working on more stories, writings, and guides in the data industry. You can absolutely expect more posts like this. In the meantime, feel free to check out my other articles to temporarily fill your hunger for data.
Thanks for reading! If you want to get in touch with me, feel free to reach me at nickmydata@gmail.com or my LinkedIn Profile. You can also view the code for previous write-ups in my Github.
Bio: Nicholas Leong is a data engineer, currently working in an online classifieds tech company. In his years of experience, Nicholas has fully designed batch and streaming pipelines, improved data warehousing solutions, and performed machine learning projects for the organization. During his free time, Nicholas likes to work on his own projects to improve his skills. He also write about his work, projects, and experiences to share them with the world. Visit my site to check out my work!
Original. Reposted with permission.
Related:
- Prefect: How to Write and Schedule Your First ETL Pipeline with Python
- Design Patterns for Machine Learning Pipelines
- ETL and ELT: A Guide and Market Analysis