Windows on Snapdragon Brings Hybrid AI to Apps at the Edge
Let’s take a closer look at Hybrid AI, how you can take advantage of it, and how Snapdragon brings hybrid AI to apps at the edge.
Today, AI is everywhere, and generative AI is being touted as its killer app. We are seeing large language models (LLMs) like ChatGPT, a generative pre-trained transformer, being applied in new and creative ways.
While LLMs were once relegated to powerful cloud servers, round-trip latency can lead to poor user experiences, and the costs to process such large models in the cloud are increasing. For example, the cost of a search query, a common use case for generative AI, is estimated to increase by ten times compared to traditional search methods as models become more complex. Foundational general-purpose LLMs, like GPT-4 and LaMDA, used in such searches, have achieved unprecedented levels of language understanding, generation capabilities, and world knowledge while pushing 100 billion parameters.
Issues like privacy, personalization, latency, and increasing costs have led to the introduction of Hybrid AI, where developers distribute inference between devices and the cloud. A key ingredient for successful Hybrid AI is the modern dedicated AI engine, which can handle large models at the edge. For example, the Snapdragon® 8cx Gen3 Compute Platform powers many devices with Windows on Snapdragon and features the Qualcomm® Hexagon™ NPU for running AI at the edge. Along with tools and SDKs, which provide advanced quantization and compression techniques, developers can add hardware-accelerated inference to their Windows apps for models with billions of parameters. At the same time, the platform’s always-connected capability via 5G and Wi-Fi 6 provides access to cloud-based inference virtually anywhere.
With such tools at one’s disposal, let’s take a closer look at Hybrid AI, and how you can take advantage of it.
Hybrid AI
Hybrid AI leverages the best of local and cloud-based inference so they can work together to deliver more powerful, efficient, and highly optimized AI. It also runs simple (aka light) models locally on the device, while more complex (aka full) models can be run locally and/or offloaded to the cloud.
Developers select different offload options based on model or query complexity (e.g., model size, prompt, and generation length) and acceptable accuracy. Other considerations include privacy or personalization (e.g., keeping data on the device), latency and available bandwidth for obtaining results, and balancing energy consumption versus heat generation.
Hybrid AI offers flexibility through three general distribution approaches:
- Device-centric: Models which provide sufficient inference performance on data collected at the device are run locally. If the performance is insufficient (e.g., when the end user is not satisfied with the inference results), an on-device neural network or arbiter may decide to offload inference to the cloud instead.
- Device-sensing: Light models run on the device to handle simpler inference cases (e.g., automatic speech recognition (ASR)). The output predictions from those on-device models are then sent to the cloud and used as input to full models. The models then perform additional, complex inference (e.g., generative AI from the detected speech data) and transmit results back to the device.
- Joint processing: Since LLMs are memory bound, hardware often sits idle waiting as data is loaded. When several LLMs are needed to generate tokens for words, it can be beneficial to speculatively run LLMs in parallel and offload accuracy checks to an LLM in the cloud.
A Stack for the Edge
A powerful engine and development stack are required to take advantage of the NPU in an edge platform. This is where the Qualcomm® AI Stack, shown in Figure 1, comes in.
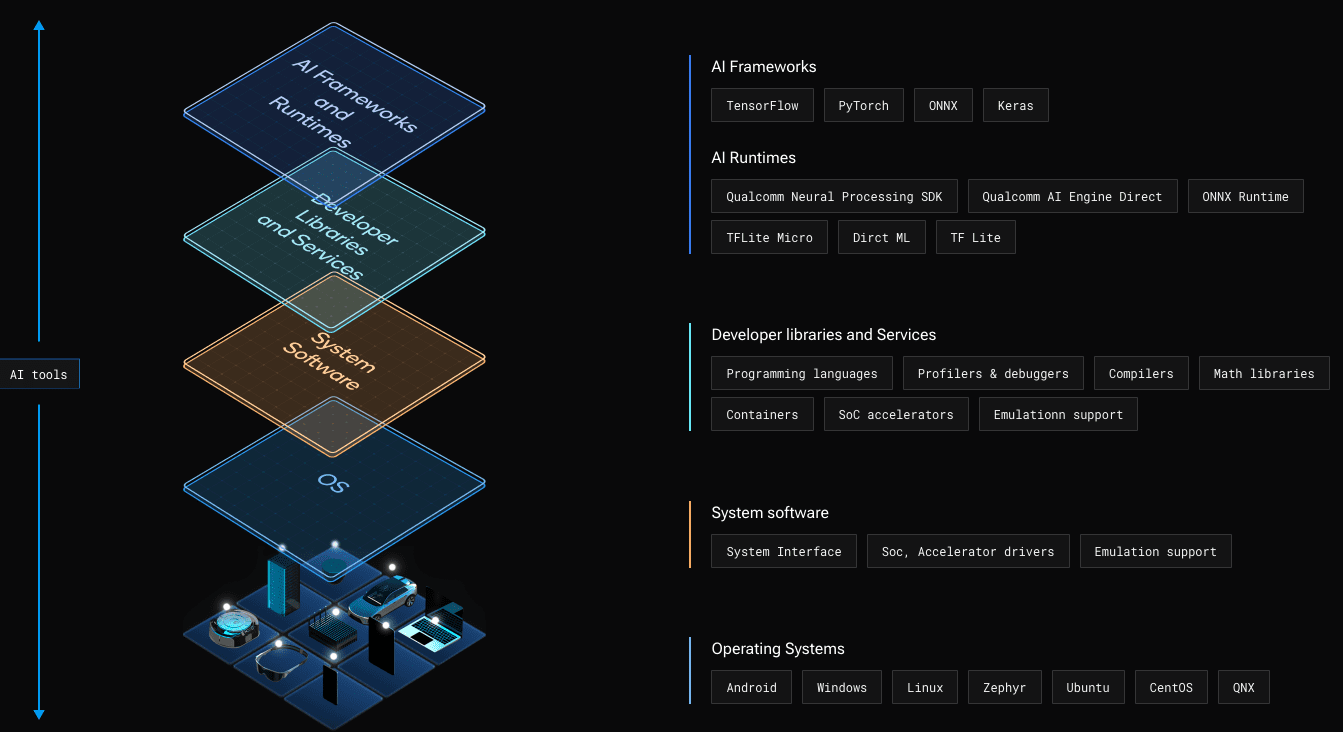
Figure 1 – The Qualcomm® AI Stack provides hardware and software components for AI at the edge across all Snapdragon platforms.
The Qualcomm AI Stack is supported across a range of platforms from Qualcomm Technologies, Inc., including Snapdragon Compute Platforms which power Windows on Snapdragon devices and Snapdragon Mobile Platforms which power many of today’s smartphones.
At the stack’s highest level are popular AI frameworks (e.g., TensorFlow) for generating models. Developers can then choose from a couple of options to integrate those models into their Windows on Snapdragon apps. Note: TFLite and TFLite Micro are not supported for Windows on Snapdragon.
The Qualcomm® Neural Processing SDK for AI provides a high-level, end-to-end solution comprising a pipeline to convert models into a Hexagon specific (DLC) format and a runtime to execute them as shown in Figure 2.
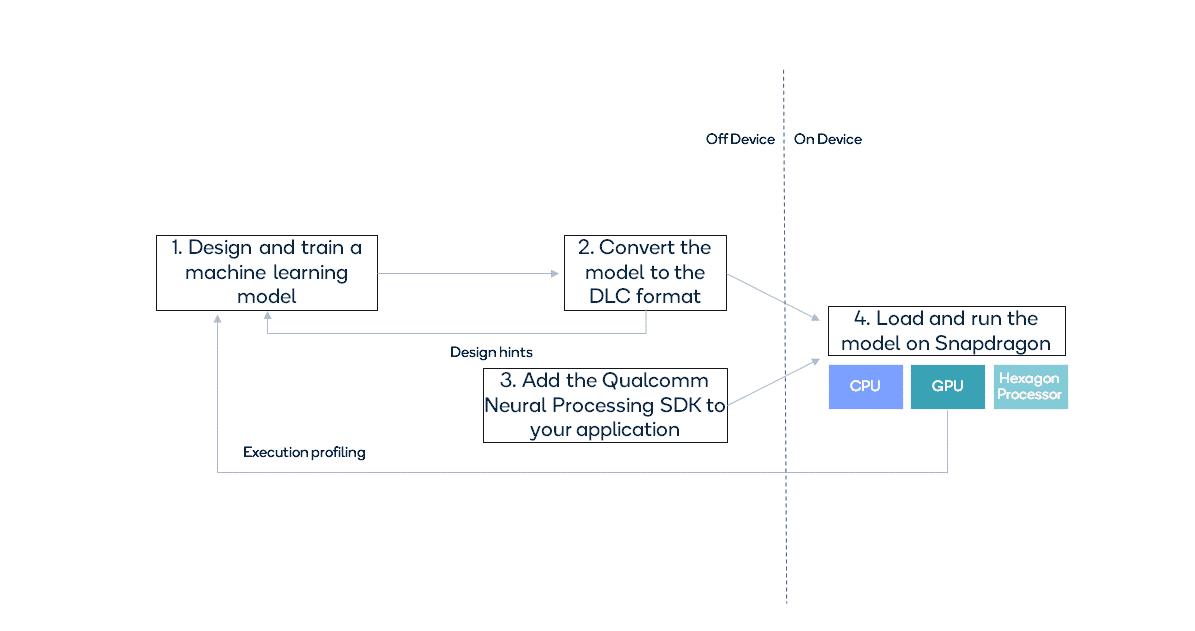
Figure 2 – Overview of using the Qualcomm® Neural Processing SDK for AI.
The Qualcomm Neural Processing SDK for AI is built on the Qualcomm AI Engine Direct SDK. The Qualcomm AI Engine Direct SDK provides lower-level APIs to run inference on specific accelerators via individual backend libraries. This SDK is becoming the preferred method for working with the Qualcomm AI Engine.
The diagram below (Figure 3) shows how models from different frameworks can be used with the Qualcomm AI Engine Direct SDK.
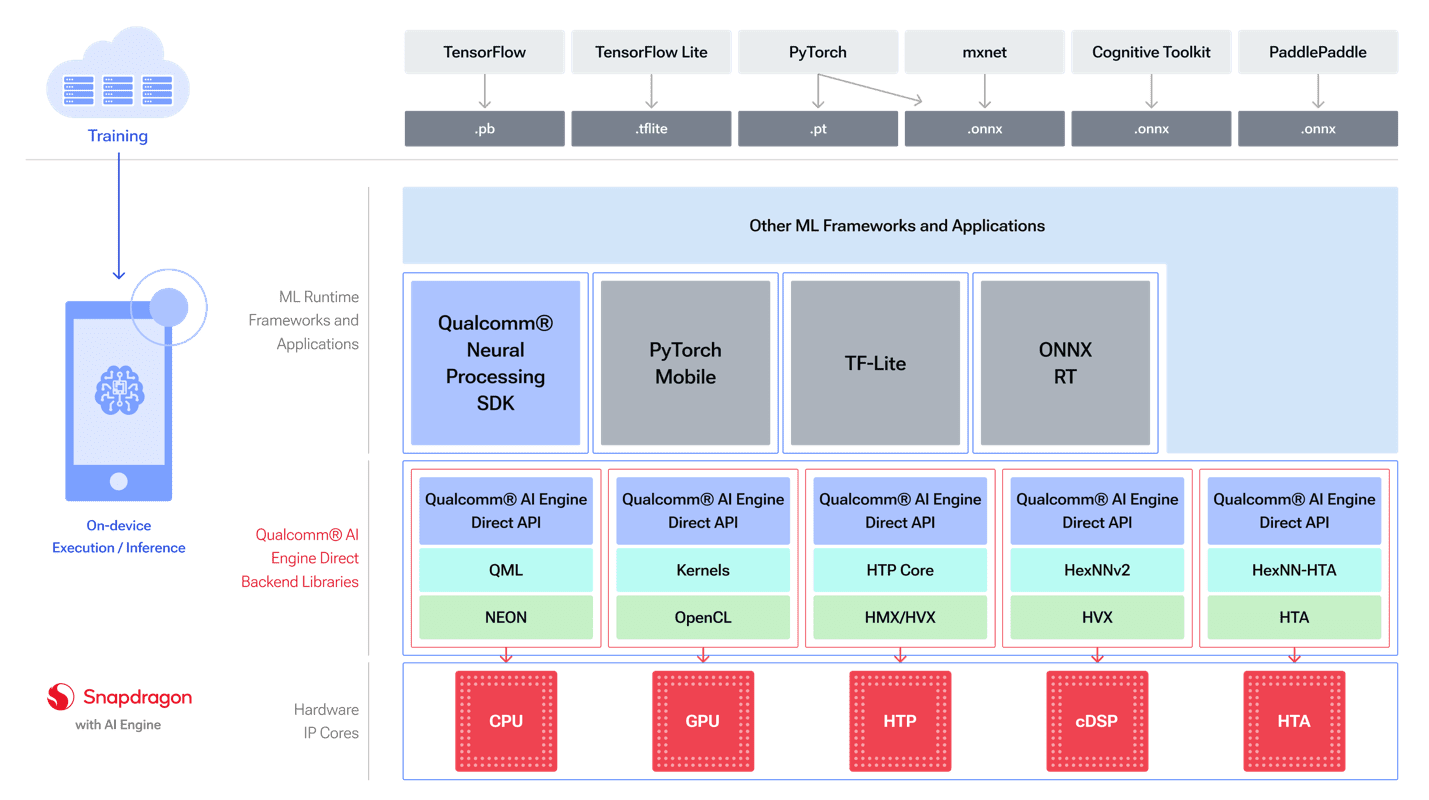
Figure 3 – Overview of the Qualcomm AI Stack, including its runtime framework support and backend libraries.
The backend libraries abstract away the different hardware cores, providing the option to run models on the most appropriate core available in different variations of Hexagon NPU (HTP for the Snapdragon 8cx Gen3).
Figure 4 shows how developers work with the Qualcomm AI Engine Direct SDK.
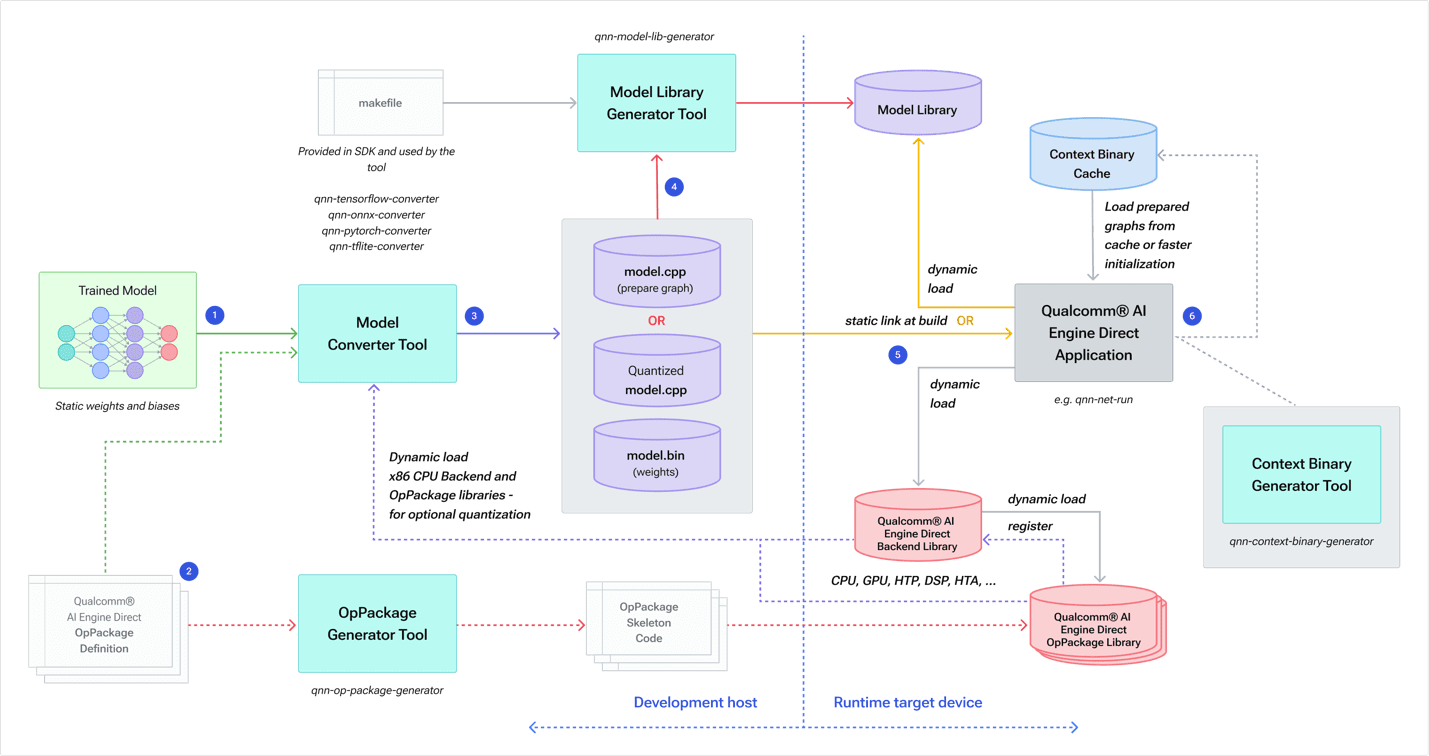
Figure 4 – Workflow to convert a model into a Qualcomm AI Engine Direct representation for optimal execution on Hexagon NPU.
A model is trained and then passed to a framework-specific model conversion tool, along with any optional Op Packages containing definitions of custom operations. The conversion tool generates two components:
- model.cpp containing Qualcomm AI Engine Direct API calls to construct the network graph
- model.bin (binary) file containing the network weights and biases (32-bit floats by default)
Note: Developers have the option to generate these as quantized data.
The SDK’s generator tool then builds a runtime model library while any Op Packages are generated as code to run on the target.
You can find implementations of the Qualcomm AI Stack for several other Snapdragon platforms spanning verticals such as mobile, IoT, and automotive. This means you can develop your AI models once, and run them across those different platforms.
Learn More
Whether your Windows on Snapdragon app runs AI solely at the edge or as part of a hybrid setup, be sure to check out the Qualcomm AI Stack page to learn more.
Snapdragon and Qualcomm branded products are products of Qualcomm Technologies, Inc. and/or its subsidiaries.