Pythia: A Suite of 16 LLMs for In-Depth Research
Pythia is a suite of 16 large language models by Eleuther AI. It helps understand and analyze autoregressive large language models during training and scaling.

Image by Author
Today large language models and LLM-powered chatbots like ChatGPT and GPT-4 have integrated well into our daily lives.
However, decoder-only autoaggressive transformer models have been used extensively for generative NLP applications long before LLM applications became mainstream. It can be helpful to understand how they evolve during training and how their performance changes as they scale.
Pythia, a project by Eleuther AI is a suite of 16 large language models that provide reproducibility for study, analysis, and further research. This article is an introduction to Pythia.
What Does the Pythia Suite Offer?
As mentioned, Pythia is a suite of 16 large language models— decoder-only autoregressive transformer models—trained on publicly available dataset. The models in the suite have sizes ranging from 70M to 12B parameters.
- The entire suite was trained on the same data in the same order. This facilitates reproducibility of the training process. So we can not only replicate the training pipeline but also analyze the language models and study their behavior in depth.
- It also provides facilities for downloading the training data loaders and more than 154 model checkpoints for each of the 16 language models.
Training Data and Training Process
Now let’s delve into the details of the Pythia LLM suite.
Training Dataset
The Pythia LLM suite was trained on the following datasets:
- Pile dataset with 300B tokens
- Deduplicated Pile dataset with 207B tokens.
There are 8 different model sizes with the smallest and largest models having 70M and 12B parameters, respectively. Other model sizes include 160M, 410M, 1B, 1.4B, 2.8B, and 6.9B.
Each of these models was trained on both the Pile and the deduplicated Pile datasets resulting in a total of 16 models. The following table shows the model sizes and a subset of hyperparameters.
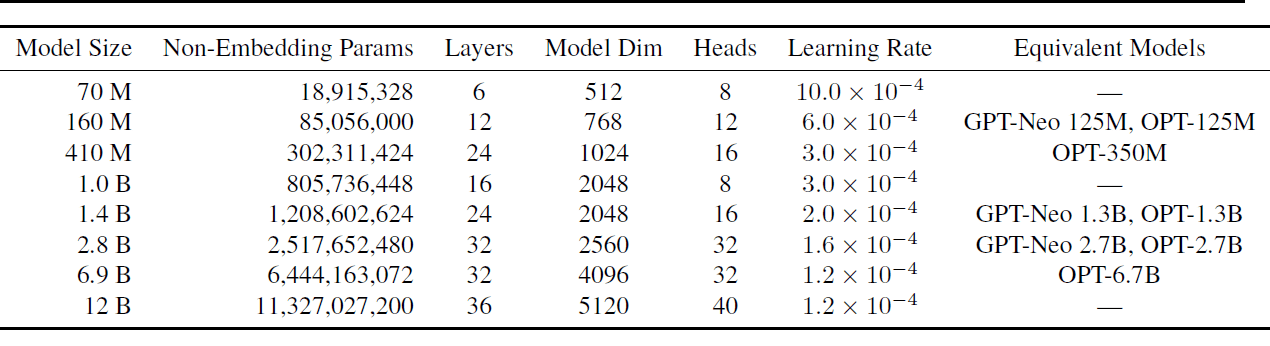
Models and hyperparameters | Image source
For full details of the hyperparameters used, read Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling.
Training Process
Here’s an overview of the architecture and training process:
- All models have fully dense layers and use flash attention.
- For easier interpretability untied embedding matrices are used.
- A batch size of 1024 is used with sequence length of 2048. This large batch size substantially reduces the wall-clock training time.
- The training process also leverages optimization techniques such as data and tensor parallelism
For the training process, the GPT-Neo-X library (includes features from the DeepSpeed library) developed by Eleuther AI is used.
Model Checkpoints
There are 154 checkpoints for each model. There’s one checkpoint every 1000 iterations. In addition, there are checkpoints at log-spaced intervals earlier in the training process: 1, 2, 4, 8, 16, 32, 64, 128, 256, and 512.
How Does Pythia Compare to Other Language Models?
The Pythia LLM suite was evaluated against the available language modeling benchmarks including OpenAI’s LAMBADA variant. It was found that the performance of Pythia is comparable to the OPT and BLOOM language models.
Advantages and Limitations
The key advantage of Pythia LLM suite is the reproducibility. The dataset is publicly available, pre-tokenized data loaders, and 154 model checkpoints are also publicly available. The full list of hyperparameters has been released, too. This makes replicating the model training and analysis simpler.
In [1], the authors explain their rationale for choosing an English language dataset over a multilingual text corpus. But having reproducible training pipelines for multilingual large language models can be helpful. Especially in encouraging more research and study of the dynamics of multilingual large language models.
An Overview of Case Studies
The research also presents interesting case studies leveraging the reproducibility of the training process of large language models in the Pythia suite.
Gender Bias
All large language models are prone to bias and misinformation. The study focuses on mitigating gender bias by modifying the pretraining data such that a fixed percentage has pronouns of a specific gender. This pretraining is also reproducible.
Memorization
Memorization in large language models is also another area that has been widely studied. The sequence memorization is modeled as a Poisson point process. The study aims at understanding if the location of the specific sequence in the training dataset influences memorization. It was observed that the location does not affect memorization.
Effect of Pretraining Term Frequencies
For language models with 2.8B parameters and greater, the occurrence of task-specific terms in the pre-training corpus was found to improve the model’s performance on tasks such as question answering.
There is also a correlation between the model size and the performance on more involved tasks such as arithmetic and mathematical reasoning.
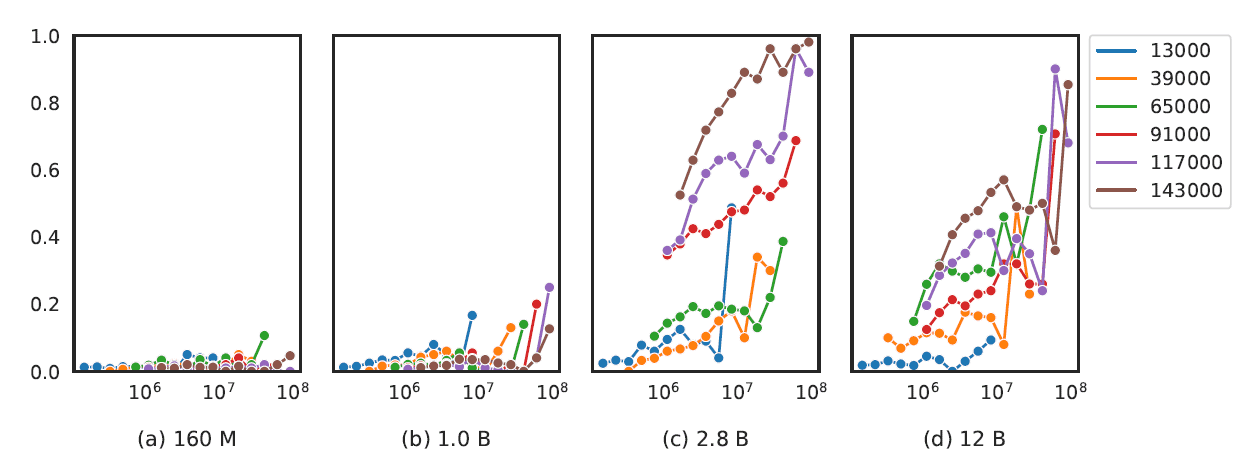
Performance on arithmetic addition task | Image source
Summary and Next Steps
Let’s sum up the key points in our discussion.
- Pythia by Eleuther AI is a suite of 16 LLMs trained on publicly available Pile and deduplicated Pile datasets.
- The size of the LLMs range from 70M to 12B parameters.
- The training data and model checkpoints are open-source and it is possible to reconstruct the exact training data loaders. So the LLM suite can be helpful in understanding the training dynamics of large language models better.
As a next step, you can explore the Pythia suite of models and model checkpoints on Hugging Face Hub.
Reference
[1] Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling, arXiv, 2023
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more.