A Practical Approach To Feature Engineering In Machine Learning
This article discussed the importance of feature learning in machine learning and how it can be implemented in simple, practical steps.

Photo by Pixabay
Feature learning is a vital component of machine learning but is often little talked about, with many guides and blog posts focusing on the latter stages of the ML lifecycle. This supporting step can make machine learning models more accurate and efficient, turning raw data into something more tangible and ready to use. Without it, building a fully-optimized model is impossible.
In this article, we will talk about how feature learning works in machine learning and how it can be implemented in simple, practical steps. In addition, we will also discuss some of the drawbacks of ML, giving a comprehensive overview of this essential process.
What Is Feature Engineering?
Feature engineering is an important machine learning (ML) technique that processes datasets and turns them into a usable set of figures that are relevant to specific tasks.
Source
Features are the data elements that are analyzed, appearing as columns within a dataset. By correcting, sorting, and normalizing these data elements, models can be optimized for better performance. Feature learning modifies these data elements to make them relevant, thus making models more accurate and with quicker response times thanks to fewer variables being used.
The feature engineering process can be broken down as follows:
- Analysis is performed to correct any issues found in the data, such as incomplete fields, inconsistencies, and other anomalies.
- Any variables that do not have any relevance to the model behavior are deleted.
- Duplicate data is dismissed.
- The records are correlated and normalized.
Why Is Feature Engineering So Important In Machine Learning?
Without feature engineering, it would not be possible to design predictive models that are capable of performing their function accurately. Feature learning also reduces the time and computation resources needed, making models more efficient.
The features of the data dictate how the predictive model will work, helping to train each model to achieve the desired results. This means that even data that is not fully applicable to a specific function can be modified to achieve a suitable outcome. Feature learning also significantly reduces the time that is spent conducting data analysis later on.
Feature Engineering: Benefits and Drawbacks
Although feature learning is essential, it does have some limitations, as well as the obvious benefits, which are listed below.
Feature Engineering: Benefits
- Models with engineered features benefit from faster data processing.
- Models are simplified and, therefore, easier to maintain.
- Predictions and estimations are more accurate.
Feature Engineering: Drawbacks
- Feature engineering can be a time-consuming process.
- Deep analysis is required to build an effective feature list. This includes a thorough understanding of the datasets, the model’s processing behaviors, and the business context.
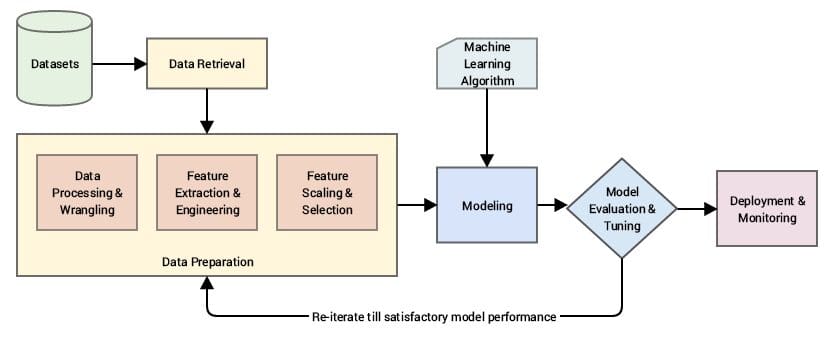
A Practical Approach To Feature Engineering In Machine Learning: Six Steps
Now we have a better understanding of what feature learning can do, as well as its drawbacks, let’s consider a practical approach to the process in 6 key steps.
#1 Data Preparation
The first step in the feature engineering process is to convert the raw data that has been collated from a range of sources into a usable format. Usable ML formats include; .csc; .tfrecords; .json; .xml; and .avro. To prepare the data, it must go through a range of processes such as cleansing, fusion, ingestion, and loading.
#2 Data Analysis
The analysis stage, sometimes referred to as the exploratory stage, is when insights and descriptive statistics are taken from the datasets, which are then presented in visualizations to better understand the data. This is then followed by identifying correlated variables and their properties so they can be cleaned.
#3 Improvement
Once the data has been analyzed and cleansed, it is time to improve it by adding any missing values, normalizing, transforming, and scaling. Data can also be further modified by adding dummy values which are qualitative/ discrete variables that represent categorical data.
#4 Construction
Features can be constructed both manually and automatically using algorithms (tSNE or Principal Component Analysis (PCA), for example). There are an almost inexhaustible number of options when it comes to feature construction. However, the solution will always depend on the problem.
#5 Selection
Feature/ variable/ attribute selection reduces the number of input variables (feature columns) by only choosing the ones that are most relevant to the variable that the model is built to predict. This helps to deliver better processing speeds and reduce computational resource usage.
Feature selection techniques include:
- Filters to remove any irrelevant features.
- Wrappers to train ML models to use several features
- Hybrid models which combine filters and wrappers
Filter-based techniques, for example, rely on statistical tests to determine whether the feature correlates sufficiently with the target variable.
#6 Evaluation and Verification
The evaluation process determines the accuracy of the model in terms of training data using the features selected. If the level of accuracy meets the required standard, then the model can be verified. If not, then the feature selection stage will need to be repeated.
Feature Engineering Use Cases
Now let’s take a look at three common use cases for feature engineering in machine learning.
Additional Insights From The Same Dataset
Many datasets contain arbitrary values, such as date, age, etc., that could be modified into different formats that provide specific information regarding a query. For example, date and duration details can be cross-referenced to determine user behaviors, such as how frequently they visit a website and how much time they spend on there.
Predictive Models
Selecting the correct features can help to build predictive models for a range of industries, one industry that can benefit from such a model is public transport, helping to gauge how many passengers may use a service on a specific day.
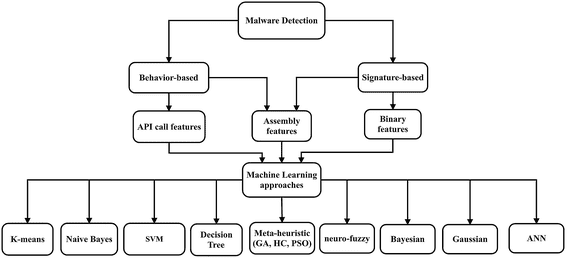
Malware Detection
Manual malware detection is extremely difficult, and most neural networks also have issues in this regard. However, feature engineering can combine manual techniques and neural networks to highlight unusual behaviors.
Source
Feature Engineering In Machine Learning: Conclusion
Feature engineering is an important stage when building machine learning models, and getting this stage right can ensure ML models are more accurate, use less computational resources, and process at higher speeds.
The feature engineering process can be broken down into six stages, from the initial data preparation to verification, choosing only the most relevant data elements for a specific task.
Nahla Davies is a software developer and tech writer. Before devoting her work full time to technical writing, she managed — among other intriguing things — to serve as a lead programmer at an Inc. 5,000 experiential branding organization whose clients include Samsung, Time Warner, Netflix, and Sony.