OpenAI Releases Two Transformer Models that Magically Link Language and Computer Vision
OpenAI has released two new transformer architectures that combine image and language tasks in an fun and almost magical way. Read more about them here.

I recently started a new newsletter focus on AI education andalready has over 50,000 subscribers. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:

Transformers have been widely considered one of the biggest breakthroughs in the last decade of machine learning and OpenAI has been at the center of it. OpenAI’s GPT-3 is, arguably, one of the most famous and controversial machine learning model ever produced. Trained in billions of parameters, GPT-3 is actively used by hundreds of companies to automate different language tasks such as question-answering, text generation and others. With that level of success, it’s only natural that OpenAI continues exploring different flavors of GPT-3 and transformer models. We saw a flavor of that a few days when OpenAI released two new transformer architectures that combine image and language tasks in an fun and almost magical way.
Wait, did I just say that transformers are being used in computer vision tasks? Correct! Even tough natural language understanding(NLU) remains the biggest battleground for transformer models, there have been incredible progress adapting those architectures to computer vision domains. OpenAI’s debut in this area comes in the form of two models:
- CLIP: Uses transformers to effectively learn visual concepts from language supervision.
- DALL·E: Uses transformers to generate images from text captions.
CLIP
With CLIP, OpenAI tries to address some of the most notable challenges of computer vision models. First of all, building training datasets for computer vision is very challenging an expensive. While language models can be trained in widely available datasets like Wikipedia, there is nothing like that for computer vision. Secondly, most computer vision models are highly specialized on a single task and can rarely adapt to a new task.
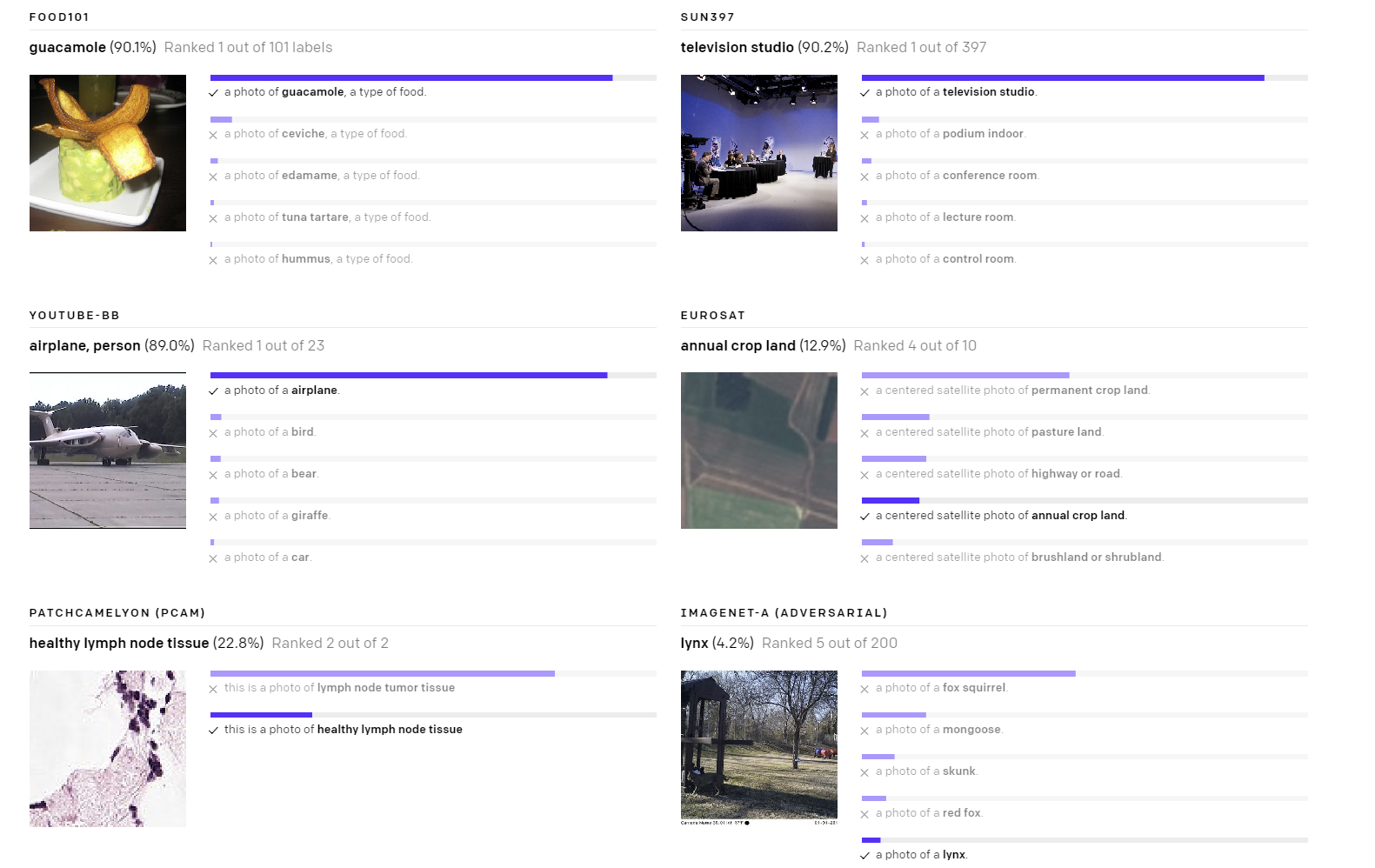
CLIP is a transformer architecture trained on an image dataset using language supervision. CLIP uses an image encoder and a text decoder to predict which images are paired with a given text in a dataset. That behavior is then used to train a zero-shot classifier that can be adapted to several image classification tasks.
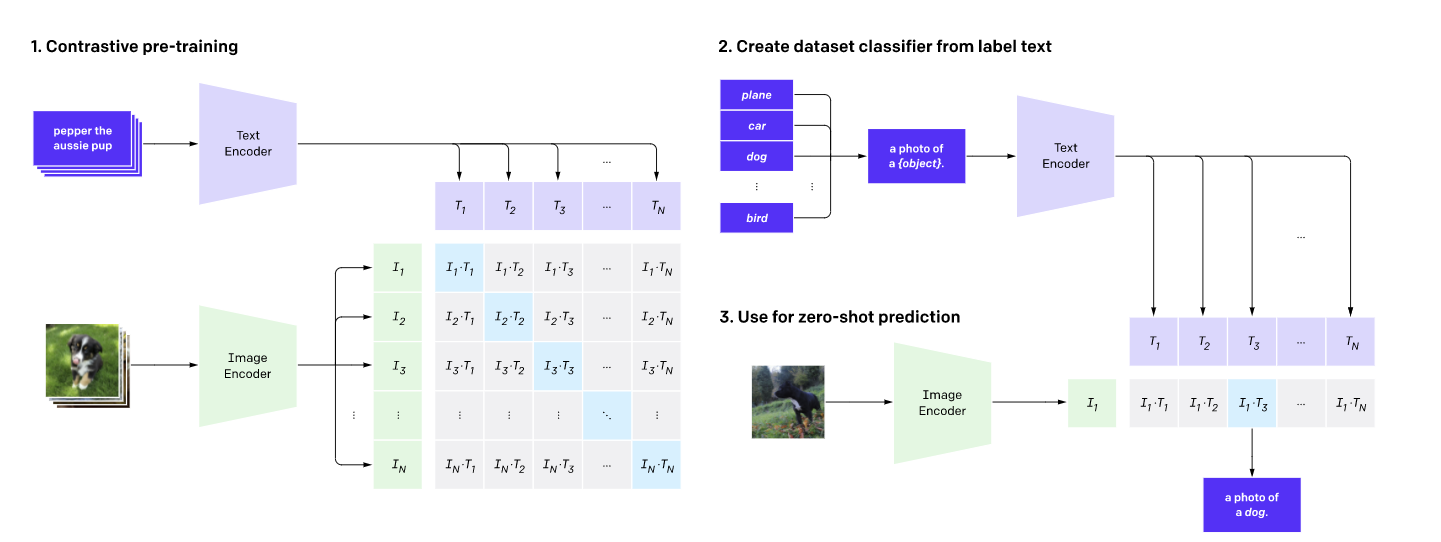
The result of a model that can learn complex visual concepts while maintaining a an efficient performance. The zero-shot approach allow CLIP to be adapted to different datasets without major changes.
DALL·E
OpenAI’s DALL·E is a GPT-3 based model that can generate images from text descriptions. The concept is to combine transformers and generative models to adapt to complex image generation scenarios.
DALL·E receives both text and images as an input dataset containing around 1280 tokens(256 for the text and 1024 for the image). The model is based on a simple decoder architecture trained to using maximum likelihood to generate all of the tokens, one after another. DALL·E also includes an attention mask that allows to relate text and images.
The use of transformer architectures results in a generative model that can generate images from highly complex sentences . Take a look at some of the examples below.
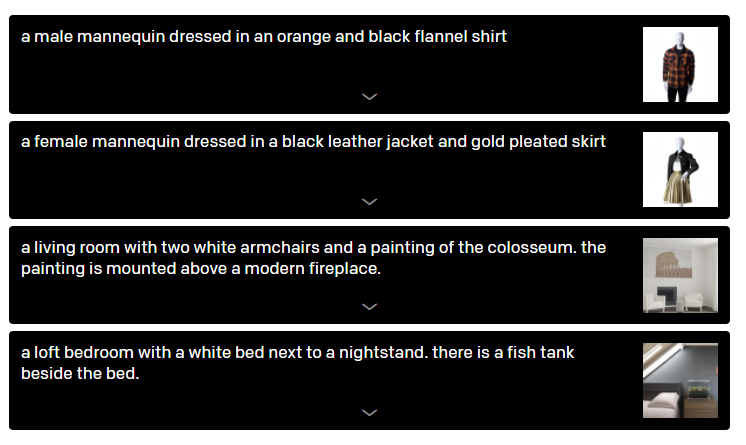
Both DALL·E and CLIP represent major advancements in multi-task transformer models and certainly important milestones for the computer vision space. We are likely to see major implementations of these models soon.
Original. Reposted with permission.
Related:
- How to Incorporate Tabular Data with HuggingFace Transformers
- Compute Goes Brrr: Revisiting Sutton’s Bitter Lesson for AI
- Must-read NLP and Deep Learning articles for Data Scientists