N-gram Language Modeling in Natural Language Processing
N-gram is a sequence of n words in the modeling of NLP. How can this technique be useful in language modeling?
Introduction
Language modeling is used to determine the probability of the word’s sequence. This modeling has a large number of applications i.e. recognition of speech, filtering of spam, etc. [1].
Natural Language Processing (NLP)
Natural language processing (NLP) is the convergence of artificial intelligence (AI) and linguistics. It is used to make the computers understand the words or statements that are written in human languages. NLP has been developed for making the work and communication with the computer easy and satisfying. As all the computer users cannot be well known by the specific languages of machines so NLP works better with the users who cannot have time for learning the new languages of machines. We can define language as a set of rules or symbols. Symbols are combined to convey the information. They are tyrannized by the set of rules. NLP is classified into two portions that are natural language understanding and natural language generation which evolves the tasks for understanding and generating the text. The classifications of NLP are shown in Figure 1 [2].
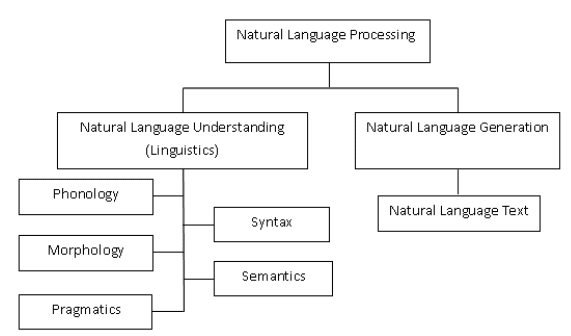
Figure 1 Classifications of NLP
Methods of the Language Modeling
Language modelings are classified as follows:
Statistical language modelings: In this modeling, there is the development of probabilistic models. This probabilistic model predicts the next word in a sequence. For example N-gram language modeling. This modeling can be used for disambiguating the input. They can be used for selecting a probable solution. This modeling depends on the theory of probability. Probability is to predict how likely something will occur.
Neural language modelings: Neural language modeling gives better results than the classical methods both for the standalone models and when the models are incorporated into the larger models on the challenging tasks i.e. speech recognitions and machine translations. One method of performing neural language modeling is by word embedding [1].
N-gram Modelling in NLP
N-gram is a sequence of the N-words in the modeling of NLP. Consider an example of the statement for modeling. “I love reading history books and watching documentaries”. In one-gram or unigram, there is a one-word sequence. As for the above statement, in one gram it can be “I”, “love”, “history”, “books”, “and”, “watching”, “documentaries”. In two-gram or the bi-gram, there is the two-word sequence i.e. “I love”, “love reading”, or “history books”. In the three-gram or the tri-gram, there are the three words sequences i.e. “I love reading”, “history books,” or “and watching documentaries” [3]. The illustration of the N-gram modeling i.e. for N=1,2,3 is given below in Figure 2 [5].
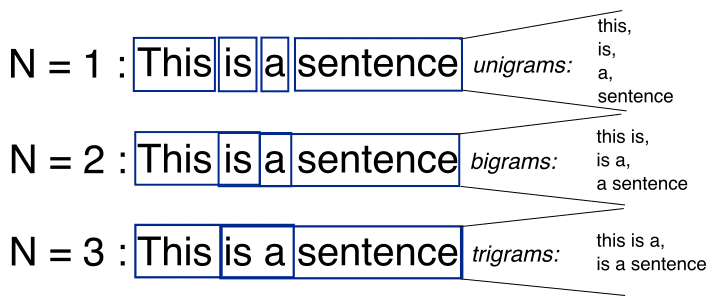
Figure 2 Uni-gram, Bi-gram, and Tri-gram Model
For N-1 words, the N-gram modeling predicts most occurred words that can follow the sequences. The model is the probabilistic language model which is trained on the collection of the text. This model is useful in applications i.e. speech recognition, and machine translations. A simple model has some limitations that can be improved by smoothing, interpolations, and back off. So, the N-gram language model is about finding probability distributions over the sequences of the word. Consider the sentences i.e. "There was heavy rain" and "There was heavy flood". By using experience, it can be said that the first statement is good. The N-gram language model tells that the "heavy rain" occurs more frequently than the "heavy flood". So, the first statement is more likely to occur and it will be then selected by this model. In the one-gram model, the model usually relies on that which word occurs often without pondering the previous words. In 2-gram, only the previous word is considered for predicting the current word. In 3-gram, two previous words are considered. In the N-gram language model the following probabilities are calculated:
P (“There was heavy rain”) = P (“There”, “was”, “heavy”, “rain”) = P (“There”) P (“was” |“There”) P (“heavy”| “There was”) P (“rain” |“There was heavy”).
As it is not practical to calculate the conditional probability but by using the “Markov Assumptions”, this is approximated to the bi-gram model as [4]:
P (“There was heavy rain”) ~ P (“There”) P (“was” |“'There”) P (“heavy” |“was”) P (“rain” |“heavy”)
Applications of the N-gram Model in NLP
In speech recognition, the input can be noisy. This noise can make a wrong speech to the text conversion. The N-gram language model corrects the noise by using probability knowledge. Likewise, this model is used in machine translations for producing more natural statements in target and specified languages. For spelling error corrections, the dictionary is useless sometimes. For instance, "in about fifteen minutes" 'minuets' is a valid word according to the dictionary but it is incorrect in the phrase. The N-gram language model can rectify this type of error.
The N-gram language model is generally at the word levels. It is also used at the character levels for doing the stemming i.e. for separating the root words from a suffix. By looking at the N-gram model, the languages can be classified or differentiated between the US and UK spellings. Many applications get benefit from the N-gram model including tagging of part of the speech, natural language generations, word similarities, and sentiments extraction. [4].
Limitations of N-gram Model in NLP
The N-gram language model has also some limitations. There is a problem with the out of vocabulary words. These words are during the testing but not in the training. One solution is to use the fixed vocabulary and then convert out vocabulary words in the training to pseudowords. When implemented in the sentiment analysis, the bi-gram model outperformed the uni-gram model but the number of the features is then doubled. So, the scaling of the N-gram model to the larger data sets or moving to the higher-order needs better feature selection approaches. The N-gram model captures the long-distance context poorly. It has been shown after every 6-grams, the gain of performance is limited.
References
- (N-Gram Language Modelling with NLTK, 30 May, 2021)
- (Diksha Khurana, Aditya Koli, Kiran Khatter, Sukhdev Singh, August 2017)
- (Mohdsanadzakirizvi, August 8, 2019)
- (N-Gram Model, March 29)
- (N-Gram)
Neeraj Agarwal is a founder of Algoscale, a data consulting company covering data engineering, applied AI, data science, and product engineering. He has over 9 years of experience in the field and has helped a wide range of organizations from start-ups to Fortune 100 companies ingest and store enormous amounts of raw data in order to translate it into actionable insights for better decision-making and faster business value.