MLOps Best Practices
Many technical challenges must be overcome to achieve successful delivery of machine learning solutions at scale. This article shares best practices we encountered while architecting and applying a model deployment platform within a large organization, including required functionality, the recommendation for a scalable deployment pattern, and techniques for testing and performance tuning models to maximize platform throughput.
By Siddharth (Sid) Kashiramka, (Sr. Manager, Platform, Capital One),
Anshuman Guha, (Principal Data Scientist, Card DS, Capital One),
DeCarlos Taylor, (Director, Card DS, Capital One).
It is now well recognized, across multiple industries, that predictive modeling and machine learning may provide tremendous value for organizations that leverage these techniques as an integral part of their business model. Many organizations spanning both the public and private sectors have adopted a data-driven business strategy where insights derived from either comprehensive data analyses or the application of highly complex machine learning algorithms are used to influence key business or operational decisions. Although there are many organizations leveraging machine learning at scale, and the variety of use cases abound at a high level, the overall machine learning life cycle has a common structure among all organizations irrespective of the specific use case or application. Specifically, for any organization leveraging data science at scale, the machine learning life cycle is defined by four key components: Model Development, Model Deployment, Model Monitoring, and Model Governance (see Figure 1).
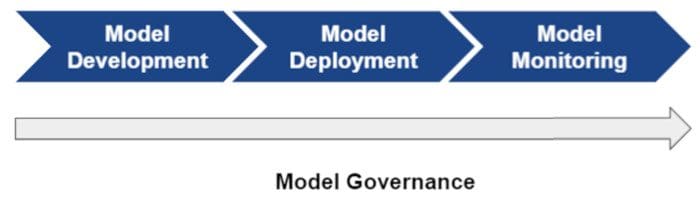
Figure 1 - Four critical steps of the machine learning life cycle.
Most data scientists are well versed in the model development part of the machine learning life cycle and have a high degree of familiarity with complex data queries (e.g., SQL), data wrangling, feature engineering, and algorithm training. Further, the performance model monitoring component of the lifecycle is somewhat germane to a data scientist's function. The performance of models over time in response to changing data distributions or for new application domains can be monitored using relevant statistical metrics of model performance (e.g., mean squared error, precision-recall, etc.) that many data scientists are familiar with. In addition, the model governance requirements, depending on the industry, are generally well defined (although not necessarily well executed!) and are often articulated at great length in organizational policy documents and via general regulatory mandates issued by a governing body.
Although the model development, monitoring, and governance components of the machine learning life cycle are complex and fraught with challenges, the model deployment (or “productionizing”) component of the process is where many organizations seem to have the most trouble. A recent report [1] suggests that 87% percent of data science projects never actually reach production, and several factors, including:
- Lack of necessary deployment expertise in the organization [2].
- The deployment process requires close interplay between multiple stakeholders, including data scientists, software engineers, and platform engineers, which may be challenging to manage effectively.
- There may be a lack of transparency between key stakeholders, and design choices adopted by one group may not be fully compatible with baseline requirements or practices of other key stakeholders.
- Productionizing models at scale may require a resilient, well-architected model deployment platform that enables a variety of machine learning applications and provides any additional supporting functionality.
- Deployment platform service level agreements (e.g., maximum model response time) may be challenging to adhere to without significant software engineering and code optimizations.
This is by no means an exhaustive list of challenges that organizations may face when deploying and productionizing their models. Although there is much to be said regarding each of the items highlighted above, in this article, we focus on the last two things that reference the construction of a well-architected deployment platform and techniques to consider when packaging machine learning models. Based on our experience with management, maintenance, and enhancement of significant model deployment platforms and our extensive experience with packaging and performance tuning productionized machine learning models, we share below some high-level considerations and best practices that we have identified along our journey. We hope that this knowledge share will allow other teams and organizations to reach their machine learning destination more rapidly and avoid pitfalls that may ultimately lead to failure.
Machine Learning Deployment Platform design
Building a model deployment platform that serves your organization's needs begins with defining the overall set of requirements that potential end-users may need [3]. The conditions may span execution, governance, monitoring, or maintenance needs, and a few capabilities that you may need to include as you design a robust platform may consist of:
- Real-time/batch processing - ML platforms can support real-time or batch or both depending on the business requirements. While making a decision, it is essential to factor in your organization's data quality needs and system responsiveness/latency. Batch-driven processes are more tolerant of data quality (DQ) issues because most batch processes have ample time to detect the problems after processing and fixing the issues before executing customer-facing decisions. On the contrary, for real-time scoring, the decisions are made in a matter of seconds. Data quality checks, data pulls from external sources, streaming outputs, etc., may add to the overall model response latency requirements.
- Model registry/inventory - While building the platform, lay out the plan for the legacy/older versions of the model (ex. do they get decommissioned or are there regulatory requirements to have these models for a certain amount of time, etc.). Having a consistent and automated path for putting all models to production and knowing how often the models are updated will help reduce significant technical debt from the legacy models.
- Model governance and risk management - In a regulated environment, the ability to audit the system is essential. Unfortunately, model governance may sometimes get overlooked as one of the critical capabilities. It is, however, necessary to build controls for robust tracking and management throughout the model's entire life cycle in the ML system. A few considerations here include collecting and persisting detailed model metadata, documenting data lineage, establishing controls, and versioning files and models.
- Concurrent model execution - Understand the demand/volume of models being called and if the model needs to execute concurrently. In most cases, more than one model is running in the background. ML platform should ensure it can scale to the growing demand while simultaneously keeping execution latency to a minimum.
- Model monitoring - For models to be effective and valuable, they need to be monitored throughout their entire life cycle, from the time they are put into production until they are retired. Effective ML models create value by reducing the risk of putting biased models in production settings but also help with raising the data science team productivity by identifying bottlenecks faster.
Enabling all of this functionality is time-consuming (sometimes even multiple years of effort) and requires complex designs and infrastructure setup. Your platform architecture should help achieve this functionality in your organization. The architecture you finalize should be supported by solid engineering best practices. For ML systems specifically, the few most relevant best practices are:
- Reproducibility - the output of each component must be replicable for any version in time
- Scalability - the system should be able to adapt to dynamic changes to volume with minimal response time.
- Automation - eliminate manual steps wherever possible to reduce error chances.
Deploying Models to the Platform
Another critical design choice for the platform is the tools and techniques used for model deployment [4]. A common standard for model deployments is using containers that are essentially a fully packaged and portable computing environment for a given application. (For more details on containerization, see link [5]). From a platform perspective, containerized models offer several benefits [6], including:
- Flexibility and portability due to the abstraction of the container from the host OS
- Better manageability due to the ability to deploy new versions of models without interfering with the ones in production
- Greater efficiency and faster model deployment
Although the use of model containers provides several benefits, several technical challenges arise when packaging and deploying containerized models. Ensuring that the containerized model returns correct output scores is critical, especially in highly regulated industries where model scoring errors may lead to negative consequences for the organization or its customer base. Therefore, it is essential to have a robust test harness that includes testing the containerized model on input data (perhaps simulated) spanning multiple scenarios, including in-range, out-of-range, missing, and edge-case values.
Another critical consideration for containerized model deployment is the overall response time ("latency") of the packaged model. High latency models can lead to a number of negative consequences, including increased platform costs (mainly when a cloud service provider hosts the platform) or lost opportunity if potential customers do not complete their applications or transactions due to slow response of the platform as high latency models execute in the background. Therefore, containerized models' performance tuning to reduce response latency is a crucial part of the deployment process.
Latency Improvement with cProfiler
Depending on the application or baseline thresholds imposed by the organization, model containers may be required to return an output within 200-300 milliseconds (or less!). In our experience, significant code optimization is often required to meet this requirement. Traditionally, the code optimization process involves individual timing blocks of code, identifying the rate-limiting functions, and then performance tuning those code blocks. A popular open-source tool available for this process is cProfiler [7] that tracks how frequently various methods and procedures are called and monitors the overall execution time. As an example, consider the call graph represented in Figure 2 below. This call graph suggests that function ‘plustwo’ is called 10X times and consumes 88%+ of the scoring time. So, any modifications that either reduce the number of function calls to this rate-limiting step or optimizations within the ‘plustwo’ function that reduce its runtime will lessen the overall scoring time for the model.
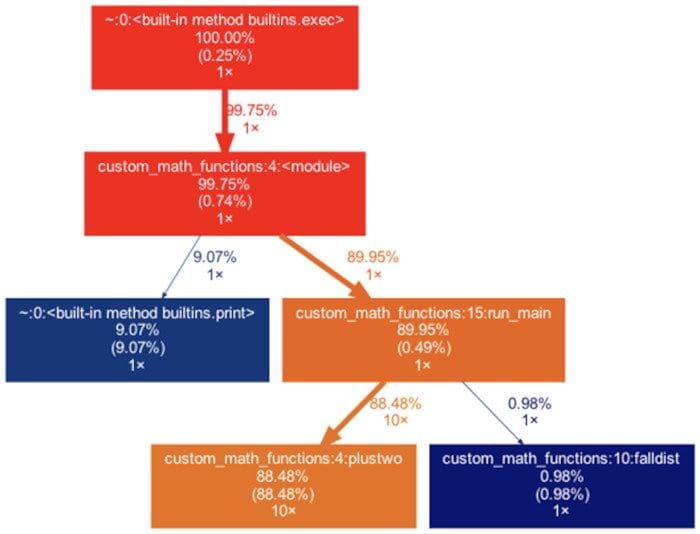
Figure 2 - Code Performance Analysis with Cprofiler.
Load Testing
For many organizations, machine learning models may eventually be deployed to customer-facing platforms, e.g., retail websites powered by recommender systems or financial services websites where models are used to decide applicants in real-time. The number of requests that the platform must process can be highly variable, and organizations may experience periods of low activity (few calls to the model container) followed by periods of extremely high load where the platform, and models, may be required to process a massive volume of requests resulting from high customer demand. Therefore, testing of the model container's robustness (and accuracy!) under high load is also a key consideration. A valuable tool for this type of testing is Locust [8], an open-source load testing tool that is distributed and scalable, has a web-based user interface, and can accommodate test scenarios written in Python.

Figure 3 - Full latency test with Locust.
A sample output of Locust is presented in Figure 3 that resulted from a test scenario where ten requests per second were streamed to a model for a period of 10 minutes. The output shows the total number of requests and also reports the response time for several percentiles. In this example, the 95th and 99th percentile have latencies of 170 and 270 milliseconds, respectively, depending on the platform thresholds, may or may not be accepted and may indicate that additional performance optimizations may be required.
Conclusion
To summarize, below are the key takeaways from this paper:
- Build your ML system/platform taking into consideration the requirements from all your stakeholders, including model compliance teams, businesses, and the end customer.
- Align on the architecture approach for the ML systems that unlock required capabilities in your organization.
- Select the appropriate tools for model deployment; model containerization is the most common method of deploying ML models.
- Perform thorough model validation tests on the deployment containers and packages.
- Independent code base replicating the entire data processing and deployment scoring pipeline can serve as a ground truth.
- Well-documented quality control measures for upstream and downstream processes, contingency plans during production issues, and logging can be helpful.
References
[1] VB Staff. “Why do 87% of data science projects never make it into production?” venturebeat.com https://venturebeat.com/2019/07/19/why-do-87-of-data-science-projects-never-make-it-into-production/ (accessed July 05, 2021)
[2] Chris. “Machine Learning Is Getting Easier. Software Engineering Is Still Hard” towardsdatascience.com https://towardsdatascience.com/machine-learning-is-getting-easier-software-engineering-is-still-hard-d4e8320bc046 (accessed July 05, 2021)
[3] Mckinsey Podcast. “Companies adopting AI across the organization are investing as much in people and processes as in technology.” mckinsey.com https://www.mckinsey.com/business-functions/mckinsey-digital/our-insights/getting-to-scale-with-artificial-intelligence (accessed July 05, 2021)
[4] Assaf Pinhasi. “Deploying Machine Learning models to production — Inference service architecture patterns” medium.com
https://medium.com/data-for-ai/deploying-machine-learning-models-to-production-inference-service-architecture-patterns-bc8051f70080 (accessed July 05, 2021)
[5] Citrix. “What is containerization and how does it work?” citrix.com
https://www.citrix.com/solutions/application-delivery-controller/what-is-containerization.html (accessed July 05, 2021)
[6] Christopher. G.S.“How to Deploy Machine Learning Models” christopherergs.com
https://christophergs.com/machine%20learning/2019/03/17/how-to-deploy-machine-learning-models/ (accessed July 05, 2021)
[7] https://docs.python.org/3/library/profile.html
Related: