Misconceptions About Semantic Segmentation Annotation
Semantic segmentation is a computer vision problem that entails putting related elements of an image into the same class. Read on to discover more, including the difficulties associated with annotation.
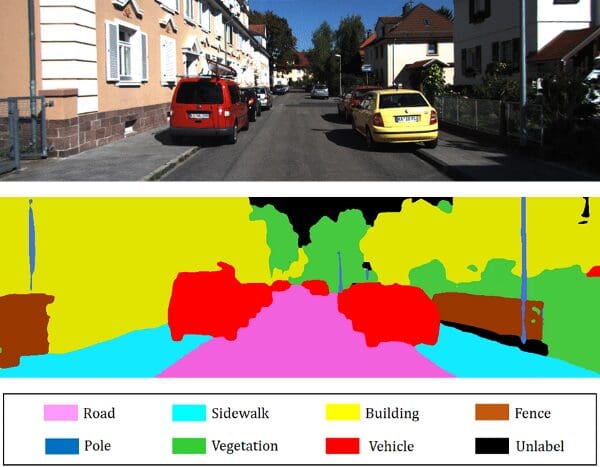
Semantic segmentation is a computer vision problem that entails putting related elements of an image into the same class.
Three steps are involved in semantic segmentation:
Classifying: Identifying and classifying a certain object in a picture.
Localization: Finding the item and putting a bounding box around.
Segmentation: A process of grouping pixels in a localized picture using a segmentation mask.
There are several subtypes of semantic segmentation, but they all arise from selecting a pair of parameters from two categories: the data’s dimensionality and the granularity of the output annotations.
Dimensionality
The number of dimensions in the data source is referred to as this. A normal camera picture is an example of a 2D object because it only has two dimensions: height and breadth. 3D data is a variation of 2D data with the addition of a ‘depth’ component. Lidar and Radar scans are two kinds of sensor data. A 4D representation, commonly known as a movie, is created when several subsequent 3D objects are layered along the time axis.
We utilize a different form of semantic segmentation depending on the dimensionality of the data to create segmentation masks. In the case of 2D segmentation, one of two methods is used: pixel-based or polygon-based colouring. Because pixels are the smallest atomic component in this model, each one is given to one of the annotation classes. This leads to a point-based segmentation in 3D, where each 3D point is labelled. A segmentation mesh can be extracted from a single object if enough points are provided.
Granularity
The amount of precision of the resulting annotations is referred to as granularity. Class-based and instance-aware segmentation are the two most common types. The segmentation mask for a particular class in the first example encompasses all areas that indicate a member of the class. In the second scenario, a distinct segmentation mask is constructed for each unique item of the chosen class, allowing different instances to be distinguished ( like separating two different cars for example ).
In machine learning, which sort of semantic segmentation is more useful?
In order to get the most out of semantic segmentation, the instance-aware subtype should be used. Here are a few of the causes behind this.
The format is quite adaptable
With your data segmented, you can train and experiment with a variety of machine learning models, including classification, detection, and localization, picture creation, foreground/background separation, handwriting recognition, content alteration, and many others. As a result, it’s employed in a variety of industries, including autonomous driving, fashion, film creation and post-production, agriculture, and so on.
Precision unrivalled
Segmentation masks are the most exact since they only cover the position of the real item. Bounding boxes, on the other hand, frequently incorporate or connect with neighbouring territories. This is caused to non-rigid things being within or on top of other non-rigid objects.
One annotation with two annotations
Despite the fact that segmentation masks are more exact, bounding boxes are still used in many procedures. Fortunately, the surrounding bounding box can always be estimated using a segmentation mask. That’s how you cover all of your bases!
Despite these benefits, there are significant drawbacks to using semantic segmentation as your annotation type of choice.
Part 1 is the most difficult
1. It’s difficult and time-consuming to annotate by hand
Making semantic masks by hand is a time-consuming and difficult task. When confronted with irregular forms or locations where the boundary between items is not immediately discernible, the labeller must accurately follow the outlines of each object (see pictures below). Annotating a single frame without specialized tools is prone to mistakes, inconsistencies, and can take more than 30 minutes.
2. Fully automated methods are incapable of delivering high-quality results
Wouldn’t it be great if we could just train a neural network to do semantic segmentation once and then have all of our annotations without having to do anything?
The reason for this is a misalignment between our perceptions of quality and how accuracy is assessed. The contour of an item is used to generate a segmentation mask, and the quality is determined by the percentage of the region that was properly detected.
3. It takes a long time to fix mistakes
Mistakes may be expensive in each of the aforementioned ways. Correcting an imperfect segmentation mask necessitates the correction of N additional masks, where N is the number of neighbouring masks (we’ll return to this later). It takes as long to adjust the mask as it does to create it from start. As a result, human adjustment of a completely automated segmentation’s output is likewise not possible. The only method to prevent this issue is to use specialized annotation software and labellers who are adequately educated.
4. Semantic segmentation annotation costs
As you may have seen, segmentation mask creation necessitates the use of specific annotators, equipment, and automation. This raises the price dramatically, frequently by several folds above the cost of annotating basic bounding boxes, and quickly depletes the budget.
Gaurav Sharma has worked in the fields of artificial intelligence and machine learning for over six years. Gaurav is a freelance technical writer working for Cogito Tech LLC, Anolytics.ai and other reputed data labelling companies that provide training data to AI business.