Mastering Regular Expressions with Python
This article dives deep into the world of regular expressions with Python, providing a comprehensive guide for anyone looking to master this complex yet powerful tool, with detailed explanations and code examples.

Image created by Author with Midjourney
Introduction
Regular expressions, or regex, are a powerful tool for manipulating text and data. They provide a concise and flexible means to 'match' (specify and recognize) strings of text, such as particular characters, words, or patterns of characters. Regex are used in various programming languages, but in this article, we will focus on using regex with Python.
Python, with its clear, readable syntax, is a great language for learning and applying regex. The Python re module provides support for regex operations in Python. This module contains functions to search, replace, and split text based on specified patterns. By mastering regex in Python, you can efficiently manipulate and analyze text data.
This article will guide you from the basics to the more complex operations with regex in Python, giving you the tools to handle any text processing challenge that comes your way. We'll start with simple character matches, then explore more complex pattern matching, grouping, and lookaround assertions. Let's get started!
Basic Regex Patterns
At its core, regex operates on the principle of pattern matching in a string. The most straightforward form of these patterns are literal matches, where the pattern sought is a direct sequence of characters. But regex patterns can be more nuanced and capable than simple literal matching.
In Python, the re module provides a suite of functions to handle regular expressions. The re.search() function, for example, scans through a given string, looking for any location where a regex pattern matches. Let's illustrate with an example:
import re
# Define a pattern
pattern = "Python"
# Define a text
text = "I love Python!"
# Search for the pattern
match = re.search(pattern, text)
print(match)
This Python code searches the string in the variable text for the pattern defined in the variable pattern. The re.search() function returns a Match object if the pattern is found within the text, or None if it isn't.
The Match object includes information about the match, including the original input string, the regular expression used, and the location of the match. For instance, using match.start() and match.end() will provide the start and end positions of the match in the string.
However, often we don't just look for exact words - we want to match patterns. That's where special characters come into play. For example, the dot (.) matches any character except a newline. Let's see this in action:
# Define a pattern
pattern = "P.th.n"
# Define a text
text = "I love Python and Pithon!"
# Search for the pattern
matches = re.findall(pattern, text)
print(matches)
This code searches the string for any five-letter word that starts with a "P", ends with an "n", and has "th" in the middle. The dot stands for any character, so it matches both "Python" and "Pithon". As you can see, even with just literal characters and the dot, regex provides a powerful tool for pattern matching.
In subsequent sections, we will delve into more complex patterns and powerful features of regex. By understanding these building blocks, you can construct more complex patterns to match nearly any text processing and manipulation task.
Meta Characters
While literal characters form the backbone of regular expressions, meta characters amplify their power by providing flexible pattern definitions. Meta characters are special symbols with unique meanings, shaping how the regex engine matches patterns. Here are some commonly used meta characters and their significance and usage:
- . (dot) - The dot is a wildcard that matches any character except a newline. For instance, the pattern "a.b" can match "acb", "a+b", "a2b", etc.
- ^ (caret) - The caret symbol denotes the start of a string. "^a" would match any string that starts with "a".
- $ (dollar) - Conversely, the dollar sign corresponds to the end of a string. "a$" would match any string ending with "a".
- * (asterisk) - The asterisk denotes zero or more occurrences of the preceding element. For instance, "a*" matches "", "a", "aa", "aaa", etc.
- + (plus) - Similar to the asterisk, the plus sign represents one or more occurrences of the preceding element. "a+" matches "a", "aa", "aaa", etc., but not an empty string.
- ? (question mark) - The question mark indicates zero or one occurrence of the preceding element. It makes the preceding element optional. For example, "a?" matches "" or "a".
- { } (curly braces) - Curly braces quantify the number of occurrences. "{n}" denotes exactly n occurrences, "{n,}" means n or more occurrences, and "{n,m}" represents between n and m occurrences.
- [ ] (square brackets) - Square brackets specify a character set, where any single character enclosed in the brackets can match. For example, "[abc]" matches "a", "b", or "c".
- \ (backslash) - The backslash is used to escape special characters, effectively treating the special character as a literal. "\$" would match a dollar sign in the string instead of denoting the end of the string.
- | (pipe) - The pipe works as a logical OR. Matches the pattern before or the pattern after the pipe. For instance, "a|b" matches "a" or "b".
- ( ) (parentheses) - Parentheses are used for grouping and capturing matches. The regex engine treats everything within parentheses as a single element.
Mastering these meta characters opens up a new level of control over your text processing tasks, allowing you to create more precise and flexible patterns. The true power of regex becomes apparent as you learn to combine these elements into complex expressions. In the following section, we'll explore some of these combinations to showcase the versatility of regular expressions.
Character Sets
Character sets in regex are powerful tools that allow you to specify a group of characters you'd like to match. By placing characters inside square brackets "[]", you create a character set. For example, "[abc]" matches "a", "b", or "c".
But character sets offer more than just specifying individual characters - they provide the flexibility to define ranges of characters and special groups. Let's take a look:
Character ranges: You can specify a range of characters using the dash ("-"). For example, "[a-z]" matches any lowercase alphabetic character. You can even define multiple ranges within a single set, like "[a-zA-Z0-9]" which matches any alphanumeric character.
Special groups: Some predefined character sets represent commonly used groups of characters. These are convenient shorthands:
- \d: Matches any decimal digit; equivalent to [0-9]
- \D: Matches any non-digit character; equivalent to [^0-9]
- \w: Matches any alphanumeric word character (letter, number, underscore); equivalent to [a-zA-Z0-9_]
- \W: Matches any non-word character; equivalent to [^a-zA-Z0-9_]
- \s: Matches any whitespace character (spaces, tabs, line breaks)
- \S: Matches any non-whitespace character
Negated character sets: By placing a caret "^" as the first character inside the brackets, you create a negated set, which matches any character not in the set. For example, "[^abc]" matches any character except "a", "b", or "c".
Let's see some of this in action:
import re
# Create a pattern for a phone number
pattern = "\d{3}-\d{3}-\d{4}"
# Define a text
text = "My phone number is 123-456-7890."
# Search for the pattern
match = re.search(pattern, text)
print(match)
This code searches for a pattern of a U.S. phone number in the text. The pattern "\d{3}-\d{3}-\d{4}" matches any three digits, followed by a hyphen, followed by any three digits, another hyphen, and finally any four digits. It successfully matches "123-456-7890" in the text.
Character sets and the associated special sequences offer a significant boost to your pattern matching capabilities, providing a flexible and efficient way to specify the characters you wish to match. By grasping these elements, you're well on your way to harnessing the full potential of regular expressions.
Some Common Patterns
While regex may seem daunting, you'll find that many tasks require only simple patterns. Here are five common ones:
Emails
Extracting emails is a common task that can be done with regex. The following pattern matches most common email formats:
# Define a pattern
pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,7}\b'
# Search for the pattern
match = re.findall(pattern, text)
print(match)
Phone Numbers
Phone numbers can vary in format, but here's a pattern that matches North American phone numbers:
# Define a pattern
pattern = r'\b\d{3}[-.\s]?\d{3}[-.\s]?\d{4}\b'
# Search for the pattern
...
IP Addresses
To match an IP address, we need four numbers (0-255) separated by periods:
# Define a pattern
pattern = r'\b(?:\d{1,3}\.){3}\d{1,3}\b'
# Search for the pattern
...
Web URLs
Web URLs follow a consistent format that can be matched with this pattern:
# Define a pattern
pattern = r'https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+'
# Search for the pattern
...
HTML Tags
HTML tags can be matched with the following pattern. Be careful, as this won't catch attributes within the tags:
# Define a pattern
pattern = r'<[^>]+>'
# Search for the pattern
...
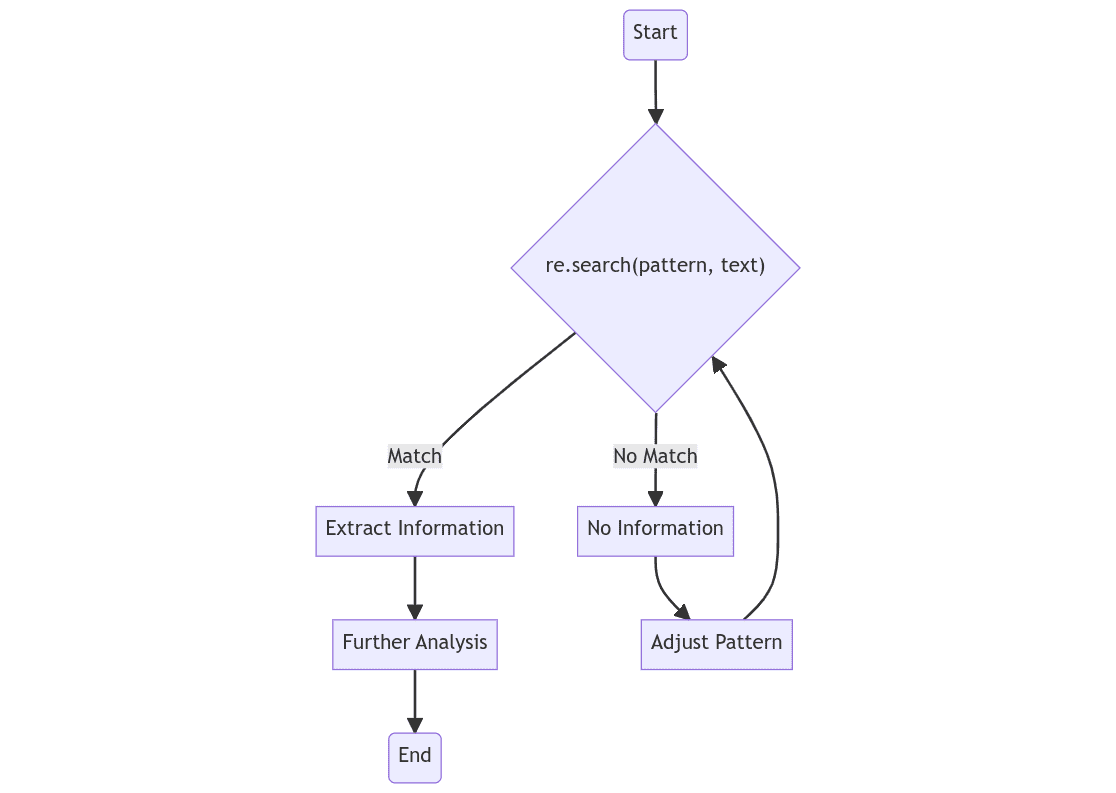
A Python regular expression matching workflow
Tips & Suggestions
Here are some practical tips and best practices to help you use regex effectively.
- Start Simple: Start with simple patterns and gradually add complexity. Trying to solve a complex problem in one go can be overwhelming.
- Test Incrementally: After each change, test your regex. This makes it easier to locate and fix problems.
- Use Raw Strings: In Python, use raw strings for regex patterns (i.e., r"text"). This ensures that Python interprets the string literally, preventing conflicts with Python's escape sequences.
- Be Specific: The more specific your regex, the less likely it will accidentally match unwanted text. For example, instead of .*, consider using .+? to match text in a non-greedy way.
- Use Online Tools: Online regex testers can help you build and test your regex. These tools can show real-time matches, groups, and provide explanations for your regex. Some popular ones are regex101 and regextester.
- Readability Over Brevity: While regex allows for very compact code, it can quickly become hard to read. Prioritize readability over brevity. Use whitespace and comments when necessary.
Remember, mastering regex is a journey, and is very much an exercise in assembling building blocks. With practice and perseverance, you'll be able to tackle any text manipulation task.
Conclusion
Regular expressions, or regex, is indeed a powerful tool in Python's arsenal. Its complexity might be intimidating at first glance, but once you delve into its intricacies, you start realizing its true potential. It provides an unmatched robustness and versatility for handling, parsing, and manipulating text data, making it an essential utility in numerous fields such as data science, natural language processing, web scraping, and many more.
One of the primary strengths of regex lies in its ability to perform intricate pattern matching and extraction operations on massive volumes of text with minimal code. Think of it as a sophisticated search engine that can locate not only precise strings of text but also patterns, ranges, and specific sequences. This enables it to identify and extract key pieces of information from raw, unstructured text data, which is a common necessity in tasks like information retrieval, data cleaning, and sentiment analysis.
Furthermore, the learning curve of regex, while seemingly steep, shouldn't deter the enthusiastic learner. Yes, regex has its own unique syntax and special characters that may seem cryptic at first. However, with some dedicated learning and practice, you will soon appreciate its logical structure and elegance. The efficiency and time saved in processing text data with regex far outweigh the initial learning investment. Thus, mastery over regex, albeit challenging, provides invaluable rewards that make it a critical skill for any data scientist, programmer, or anyone dealing with text data in their work.
The concepts and examples we've discussed here are just the tip of the iceberg. There are many more regex concepts to explore, such as quantifiers, groups, lookaround assertions, and more. So continue practicing, experimenting, and mastering regex with Python. Happy coding pattern matching!
Matthew Mayo (@mattmayo13) is a Data Scientist and the Editor-in-Chief of KDnuggets, the seminal online Data Science and Machine Learning resource. His interests lie in natural language processing, algorithm design and optimization, unsupervised learning, neural networks, and automated approaches to machine learning. Matthew holds a Master's degree in computer science and a graduate diploma in data mining. He can be reached at editor1 at kdnuggets[dot]com.