The Machine Learning Lifecycle
Learn about the standard process for building sustainable machine learning applications.
There are no standard practices for building and managing machine learning (ML) applications. As a result, machine learning projects are not well organized, lack reproducibility, and are prone to complete failure in the long run. We need a model that helps us maintain quality, sustainability, robustness, and cost management throughout the ML life cycle.
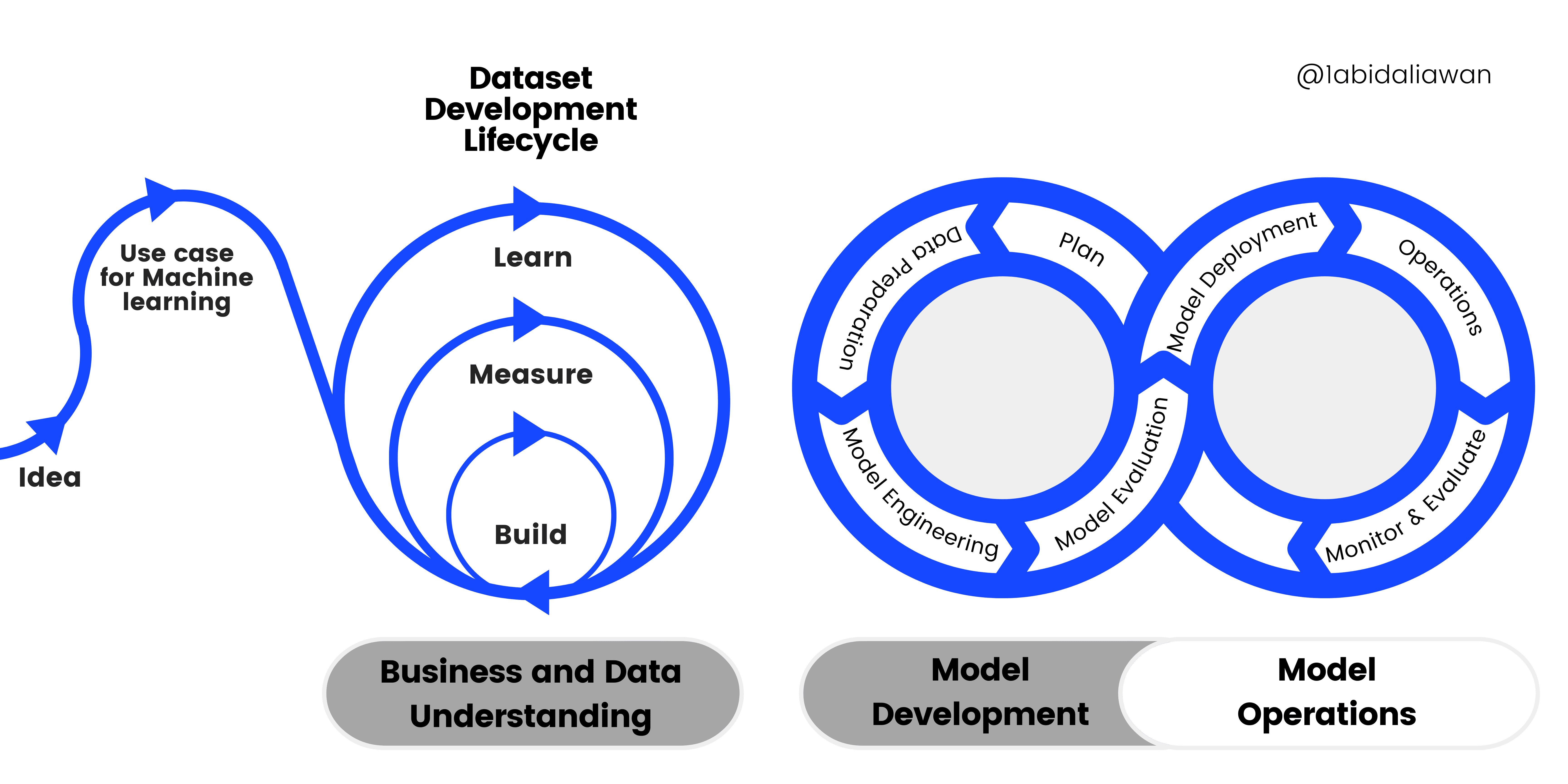
Image by Author | Machine Learning Development Life Cycle Process
The Cross-Industry Standard Process for the development of Machine Learning applications with Quality assurance methodology (CRISP-ML(Q)) is an upgraded version of CRISP-DM to ensure quality ML products.
The CRISP-ML(Q) has six individual phases:
- Business and Data Understanding
- Data Preparation
- Model Engineering
- Model Evaluation
- Model Deployment
- Monitoring and Maintenance.
These phases require constant iteration and exploration for building better solutions. Even though there is an order in a framework, the output of the later phase can determine whether we have to re-examine the previous phase or not.
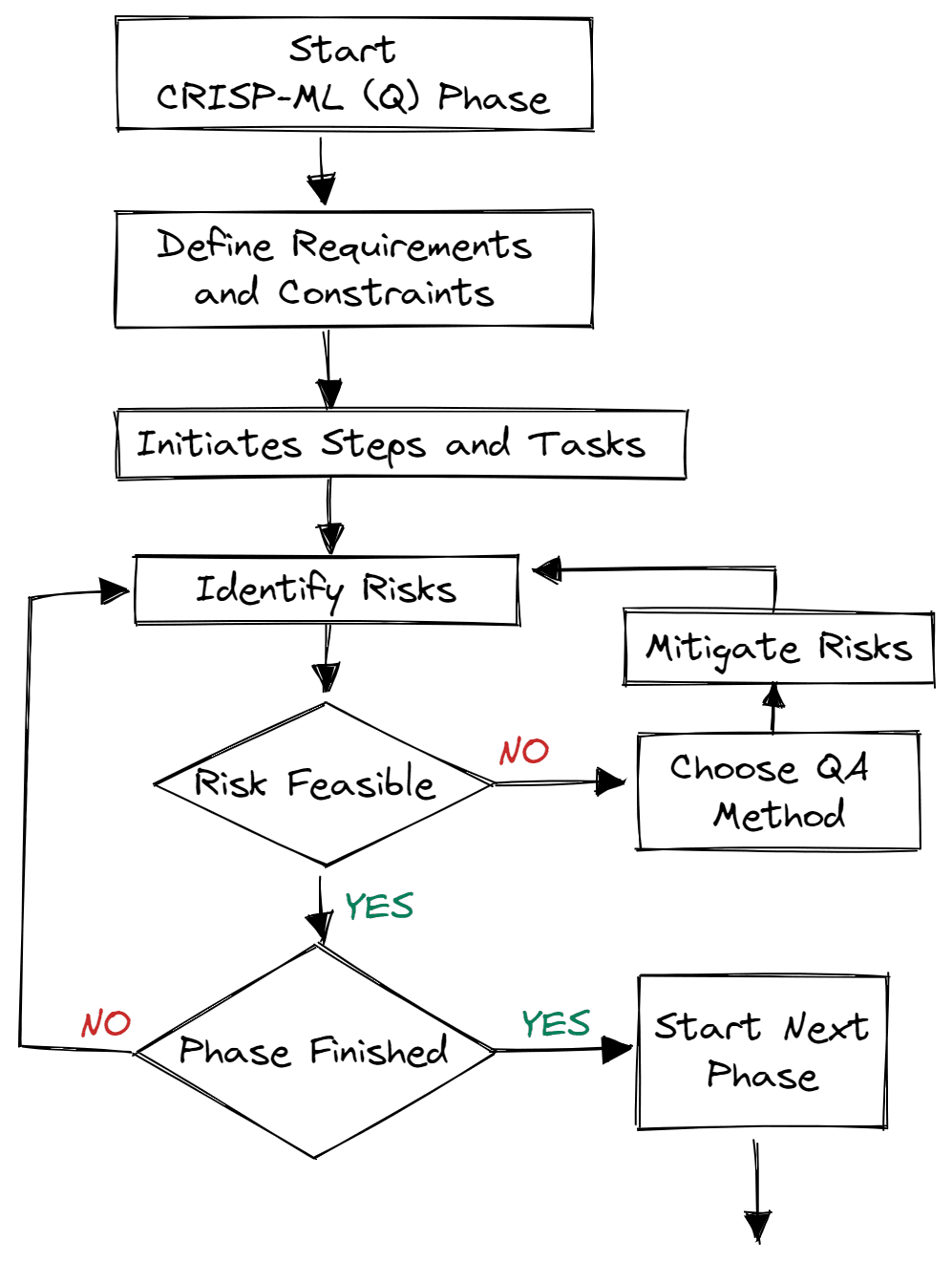
Image by Author | Quality Assurance for Each Phase
The quality assurance methodologies are introduced to each phase of the framework. The methodology comes with requirements and constraints such as performance metrics, data quality requirements, and robustness. It helps mitigate the risk that affects the success of machine learning applications. It can be achieved by constant monitoring and maintaining the overall system.
For example: In an e-commerce business, data and concept drift will contribute to model degradation, and if we don’t have a system in place to monitor these changes, the company will take a loss in the shape of losing customers.
Business and Data Understanding
At the start of the development process, we need to identify the scope of the project, success criteria, and feasibility of the ML application. After that, we start the process of data collection and quality verification. This process is long and challenging.
Scope: what we want to achieve by using a machine learning process. Is it to retain customers or reduce the cost of operation by automation.
Success Criteria: we have to define clear and measurable business, machine learning (statistical metric), and economic (KPI) success metrics.
Feasibility: we need to ensure data availability, the applicability of ML application, legal constraints, robustness, scalability, explainability, and resource demand.
Data Collection: gathering the data, versioning it for reproducibility, and ensuring a constant stream of real-life and generated data.
Data Quality Verification: ensuring the quality by maintaining data description, requirements, and verification.
To ensure quality and reproducibility, we need to document the statistical properties of data and the data generating process.
Data Preparation
The second phase is pretty much straightforward. We will be preparing the data for the modeling phase. It includes data selection, data cleaning, feature engineering, data augmentation, and normalization.
- We start with feature selection, data selection, and dealing with unbalanced classes by over-sampling or under-sampling).
- Then, focusing on reducing noise and dealing with missing values. For quality assurance purposes, we will add data unit testing to mitigate faulty values.
- Depending on your model, we perform feature engineering and data augmentations, for example, one-hot encoding and clustering.
- Normalizing and scaling the data. It will mitigate the risk of biased features.
To ensure reproducibility, we create data modeling, transformation, and feature engineering pipelines.
Model Engineering
The constraints and the requirements of the Business and Data Understanding phase will determine the modeling phase. We need to understand business problems and how we are going to develop machine learning models to solve them. We will be focusing on model selection, optimization, and training. We will be ensuring model performance metrics, robustness, scalability, explainability, and optimizing storage and compute resources.
- Research in model architecture and similar business problems
- Defining model performance metrics
- Model selection
- Understanding domain knowledge by incorporating experts.
- Model training
- Model compression and ensembling
To ensure quality and reproducibility, we will store and version model metadata such as model architecture, training and validation data, hyper-parameters, and environment description.
Finally, we will track ML experiments and create ML pipelines to create a repeatable training process.
Model Evaluation
It is the phase where we test and ensure that our model is ready for deployment.
- We will be testing the model performance on a test dataset.
- Assessing model robustness by providing random or false data.
- Improving model explainability to meet regulatory requirements.
- Comparing the result with initial success metrics automatically or by the domain expert.
For quality assurance, every step in the evaluation phase is recorded.
Model Deployment
The model deployment is a phase where we integrate the machine learning model into an existing system. The model can be deployed on a server, browser, software, and edge devices. The prediction from the models can be used in BI dashboards, APIs, web apps, and plugins.
The model deployment processes:
- Defining hardware inference
- Model evaluation in production
- Ensuring user acceptance and usability
- Providing fall back plan and minimizing losses
- Deployment strategy.
Monitoring and Maintenance
The model in production requires constant monitoring and maintenance. We will be monitoring model staleness, hardware performance, and software performance.
Continuous monitoring is the first part of the process, and if the performance drops below the threshold take an automatic decision to retrain the model on new data. Furthermore, the maintenance part is not limited to just model re-training. It involves decision-making to acquire new data, update hardware and software, and improve the ML process depending on the business use case.
In short, it is continuous integration, training, and deployment of ML models.
Conclusions
Training and validating models is a small part of ML application. There are several processes involved to convert the initial idea into reality. In this post, we have learned about CRISP-ML(Q) and how it emphasizes risk assessment and quality assurance.
We start by defining the business objective, collecting and cleaning the data, building the model, validating it on a test dataset, and deploying it to production.
The key component of this framework is continuous monitoring and maintenance. We will monitor data, software, and hardware metrics to determine whether to re-train the model or upgrade the system.
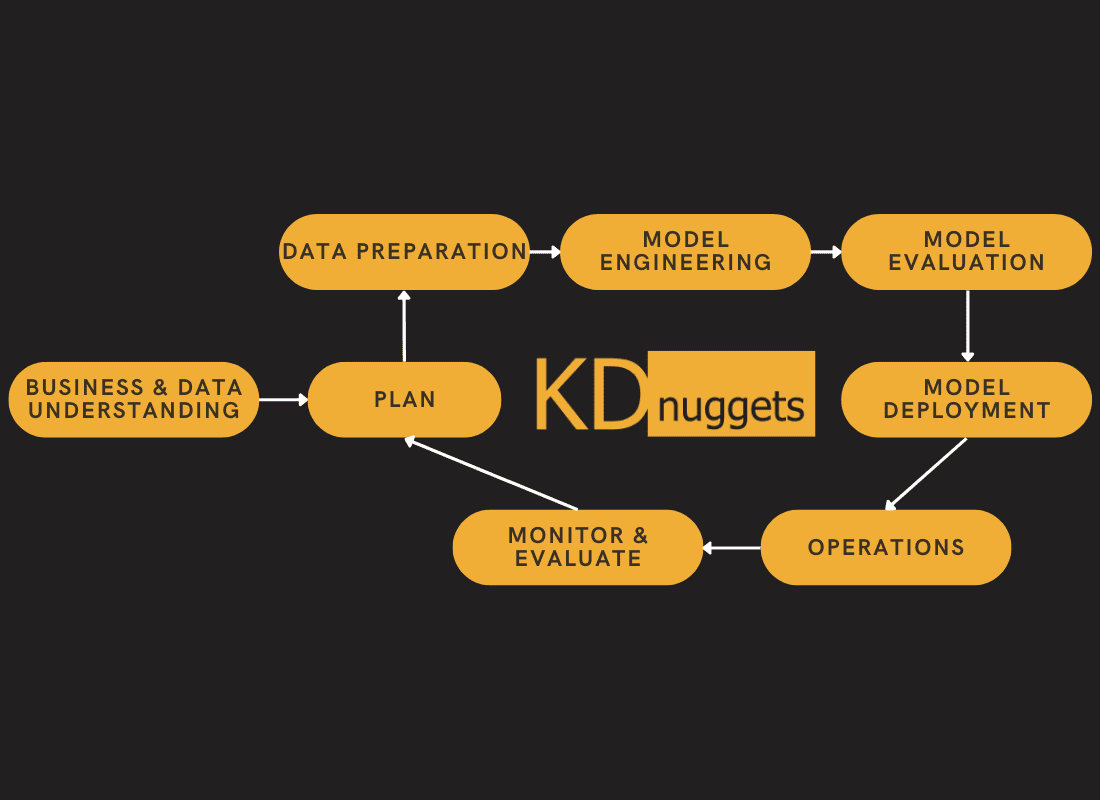
Image by Author
If you are new to machine learning operations and want to learn more about it, read the review of the free MLOps course by DataTalks.Club. You will get hands-on experience in all 6 phases and learn about the real-life implementation of CRISP-ML.
Reference
- Towards CRISP-ML(Q): A Machine Learning Process Model with Quality Assurance Methodology (arxiv.org)
- CRISP-ML(Q) (ml-ops.org)
- Article Review: Towards CRISP-ML(Q)
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in Technology Management and a bachelor's degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.