 The Main Approaches to Natural Language Processing Tasks
The Main Approaches to Natural Language Processing Tasks
 The Main Approaches to Natural Language Processing Tasks
The Main Approaches to Natural Language Processing TasksLet's have a look at the main approaches to NLP tasks that we have at our disposal. We will then have a look at the concrete NLP tasks we can tackle with said approaches.

Source: Top 5 Semantic Technology Trends to Look for in 2017 (ontotext).
We have previously discussed a number of introductory topics in natural language processing (NLP), and I had planned at this point to move forward with covering some some useful, practical applications. It then came to my attention that I had overlooked a couple of important introductory discussions which were likely needed prior to moving ahead. The first of those topics is will be covered here, more of a general discussion on the approaches to natural language processing tasks which are common today. This also brings up the question: specifically, what types of NLP tasks are there?
The other fundamental topic which has been pointed out to me as being overlooked will be covered next week, and that will be address the common question of "how do we represent text for machine learning systems?"
But first, back to today's topic. Let's have a look at the main approaches to NLP tasks that we have at our disposal. We will then have a look at the concrete NLP tasks we can tackle with said approaches.
Approaches to NLP Tasks
While not cut and dry, there are 3 main groups of approaches to solving NLP tasks.
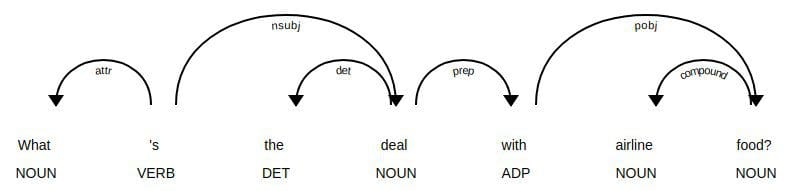
Fig 1. Dependency parse tree using spaCy.
1. Rule-based
Rule-based approaches are the oldest approaches to NLP. Why are they still used, you might ask? It's because they are tried and true, and have been proven to work well. Rules applied to text can offer a lot of insight: think of what you can learn about arbitrary text by finding what words are nouns, or what verbs end in -ing, or whether a pattern recognizable as Python code can be identified. Regular expressions and context free grammars are textbook examples of rule-based approaches to NLP.
Rule-based approaches:
- tend to focus on pattern-matching or parsing
- can often be thought of as "fill in the blanks" methods
- are low precision, high recall, meaning they can have high performance in specific use cases, but often suffer performance degradation when generalized
2. "Traditional" Machine Learning
"Traditional" machine learning approaches include probabilistic modeling, likelihood maximization, and linear classifiers. Notably, these are not neural network models (see those below).
Traditional machine learning approaches are characterized by:
- training data - in this case, a corpus with markup
- feature engineering - word type, surrounding words, capitalized, plural, etc.
- training a model on parameters, followed by fitting on test data (typical of machine learning systems in general)
- inference (applying model to test data) characterized by finding most probable words, next word, best category, etc.
- "semantic slot filling"
3. Neural Networks
This is similar to "traditional" machine learning, but with a few differences:
- feature engineering is generally skipped, as networks will "learn" important features (this is generally one of the claimed big benefits of using neural networks for NLP)
- instead, streams of raw parameters ("words" -- actually vector representations of words) without engineered features, are fed into neural networks
- very large training corpus
Specific neural networks of use in NLP include recurrent neural networks (RNNs) and convolutional neural networks (CNNs).
Why use "traditional" machine learning (or rule-based) approaches for NLP?
- still good for sequence labeling (using probabilistic modeling)
- some ideas in neural networks are very similar to earlier methods (word2vec similar in concept to distributional semantic methods)
- use methods from traditional approaches to improve neural network approaches (for example, word alignments and attention mechanisms are similar)
Why deep learning over "traditional" machine learning?
- SOTA in many applications (for example, machine translation)
- a lot of research (majority?) in NLP happening here now
Importantly, both neural network and non-neural network approaches can be useful for contemporary NLP in their own right; they can also can be used or studied in tandem for maximum potential benefit
What are NLP Tasks?
We have the approaches, but what about the tasks themselves?
There are no hard lines between these task types; however, many are fairly well-defined at this point. A given macro NLP task may include a variety of sub-tasks.
We first outlined the main approaches, since the technologies are often focused on for beginners, but it's good to have a concrete idea of what types of NLP tasks there are. Below are the main categories of NLP tasks.
1. Text Classification Tasks
- Representation: bag of words (does not preserve word order)
- Goal: predict tags, categories, sentiment
- Application: filtering spam emails, classifying documents based on dominant content
2. Word Sequence Tasks
- Representation: sequences (preserves word order)
- Goal: language modeling - predict next/previous word(s), text generation
- Application: translation, chatbots, sequence tagging (predict POS tags for each word in sequence), named entity recognition
3. Text Meaning Tasks
- Representation: word vectors, the mapping of words to vectors (n-dimensional numeric vectors) aka embeddings
- Goal: how do we represent meaning?
- Application: finding similar words (similar vectors), sentence embeddings (as opposed to word embeddings), topic modeling, search, question answering

Fig 2. Named entity recognition (NER) using spaCy (text excerpt taken from here).
4. Sequence to Sequence Tasks
- Many tasks in NLP can be framed as such
- Examples are machine translation, summarization, simplification, Q&A systems
- Such systems are characterized by encoders and decoders, which work in complement to find a hidden representation of text, and to use that hidden representation
5. Dialog Systems
- 2 main categories of dialog systems, categorized by their scope of use
- Goal-oriented dialog systems focus on being useful in a particular, restricted domain; more precision, less generalizable
- Conversational dialog systems are concerned with being helpful or entertaining in a much more general context; less precision, more generalization
Whether it be in dialog systems or the practical difference between rule-based and more complex approaches to solving NLP tasks, note the trade-off between precision and generalizability; you generally sacrifice in one area for an increase in the other.
After covering text data representation in the next article, we will move on to some more advanced NLP topics, as well as some practical exploration of useful NLP tasks.
References:
- From Languages to Information, Stanford
- Natural Language Processing, National Research University Higher School of Economics (Coursera)
- Neural Network Methods for Natural Language Processing, Yoav Goldberg
Related:
- A General Approach to Preprocessing Text Data
- A Framework for Approaching Textual Data Science Tasks
- Text Data Preprocessing: A Walkthrough in Python