 Machine Learning vs Statistics
Machine Learning vs Statistics
 Machine Learning vs Statistics
Machine Learning vs StatisticsMachine learning is all about predictions, supervised learning, and unsupervised learning, while statistics is about sample, population, and hypotheses. But are they actually that different?
Aatash Shah, CEO of Edvancer Eduventures.

Many people have this doubt, what’s the difference between statistics and machine learning? Is there something like machine learning vs. statistics?
From a traditional data analytics standpoint, the answer to the above question is simple.
- Machine Learning is an algorithm that can learn from data without relying on rules-based programming.
- Statistical modeling is a formalization of relationships between variables in the data in the form of mathematical equations.
Machine learning is all about predictions, supervised learning, unsupervised learning, etc.
Statistics is about sample, population, hypothesis, etc.
Two different critters, right? Well, let’s see if they are actually that different!
Both machine learning and statistics have the same objective
According to Larry Wasserman:
They are both concerned with the same question: how do we learn from data?
In his blog, he states how the same concepts have different names in the two fields:
| Statistics | Machine Learning |
|---|---|
| Estimation | Learning |
| Classifier | Hypothesis |
| Data Point | Example/ Instance |
| Regression | Supervised Learning |
| Classification | Supervised Learning |
| Covariate | Feature |
| Response | Label |
Robert Tibshirani, a statistician and machine learning expert at Stanford, calls machine learning “glorified statistics."
Nowadays, both machine learning and statistics techniques are used in pattern recognition, knowledge discovery and data mining. The two fields are converging more and more even though the below figure may show them as almost exclusive.
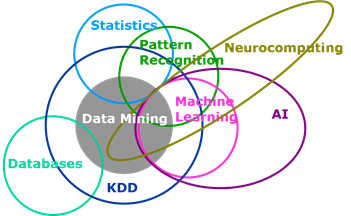
Source: SAS Institute - A Venn diagram that shows how machine learning and statistics are related
Both machine learning and statistics share the same goal: Learning from data. Both these methods focus on drawing knowledge or insights from the data. But, their methods are affected by their inherent cultural differences.
They’re related, sure. But their parents are different.
Machine learning is a subfield of computer science and artificial intelligence. It deals with building systems that can learn from data, instead of explicitly programmed instructions.
A statistical model, on the other hand, is a subfield of mathematics.
Machine learning is comparatively a new field.
Cheap computing power and availability of large amounts of data allowed data scientists to train computers to learn by analyzing data. But, statistical modeling existed long before computers were invented.
Methodological differences between machine learning and statistics
The difference between the two is that machine learning emphasizes optimization and performance over inference which is what statistics is concerned about.
This is how a statistician and machine learning practitioner will describe the outcome of the same model:
- ML professional: “The model is 85% accurate in predicting Y, given a, b and c.”
- Statistician: “The model is 85% accurate in predicting Y, given a, b and c; and I am 90% certain that you will obtain the same result.”
Machine learning requires no prior assumptions about the underlying relationships between the variables. You just have to throw in all the data you have, and the algorithm processes the data and discovers patterns, using which you can make predictions on the new data set. Machine learning treats an algorithm like a black box, as long it works. It is generally applied to high dimensional data sets, the more data you have, the more accurate your prediction is.
In contrast, statisticians must understand how the data was collected, statistical properties of the estimator (p-value, unbiased estimators), the underlying distribution of the population they are studying and the kinds of properties you would expect if you did the experiment many times. You need to know precisely what you are doing and come up with parameters that will provide the predictive power. Statistical modeling techniques are usually applied to low dimensional data sets.
Conclusion
It may seem like machine learning and statistical modeling are two different branches of predictive modeling. The difference between the two has reduced significantly over the past decade. Both the branches have learned from each other a lot and will continue to come closer together in the future.
But, understanding the association and knowing their differences enables machine learners and statisticians to expand their knowledge and even apply methods outside their domain of expertise. This is the notion of “data science” itself, which aims to bridge the gap. Collaboration and communication between these two fascinating data-driven disciplines allows us to make better decisions that will ultimately positively affect the way we live.
You can learn some machine learning techniques which are based on statistics in our Certified Business Analytics Professional course.
Bio: Aatash Shah is the co-founder and CEO of Edvancer Eduventures. He has over 6 years of experience in the investment banking industry before starting Edvancer.
Original. Reposted with permission.
Related: