 Machine Learning Applied to Big Data, Explained
Machine Learning Applied to Big Data, Explained
 Machine Learning Applied to Big Data, Explained
Machine Learning Applied to Big Data, ExplainedMachine learning with Big Data is, in many ways, different than "regular" machine learning. This informative image is helpful in identifying the steps in machine learning with Big Data, and how they fit together into a process of their own.
Big Data is no longer buzzword terminology or cutting edge, conceptually; rather, it just is. Big Data is not easily or precisely definable, but it is generally easy to identify when you see it.
While successful applications of machine learning cannot rely solely on cramming ever-increasing amounts of Big Data at algorithms and hoping for the best, the ability to leverage large amounts of data for machine learning tasks is a must-have skill for practitioners at this point.
While much of machine learning holds true regardless of data amounts, there are aspects which are the exclusive domain of Big Data modeling, or which apply moreso than they do to smaller data amounts. Data scientist Rubens Zimbres outlines a process for applying machine to Big Data in his original graphic below.
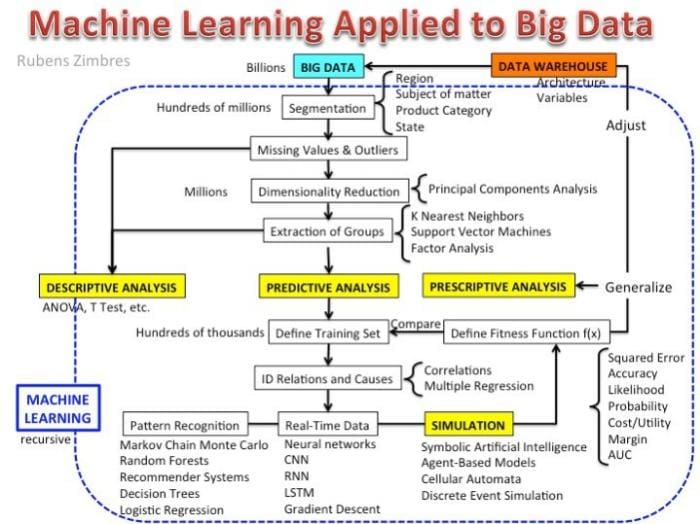
Here is a short description of the image from Zimbres, himself:
The most important part is the one where the data scientist's needs generate a demand for change in data architecture, because this is the part where Big Data projects fail. The orange square. When algorithms are computationally expensive or when infrastructure is not ready for ML algorithms. For instance, lately big banks in Brazil are hiring mainframe specialists to deal with this issue.
The picture is in fact a mind map I did to understand the whole Data Science process.
Zimbres' process includes paths for descriptive, predictive, and prescriptive analysis, as well as simulation. Importantly, the machine learning process is explicitly noted as recursive, which is perhaps especially true of modeling large quantities of data. Zimbres also breaks down the relative number of records at each successive stage of a machine learning task. Likely of greatest importance to newcomers to data science, the sub tasks of the machine learning process are presented alongside task-relevant algorithms.
While Zimbres himself states that there are a few small mistakes with the process graphic (notably, the inclusion of Support Vector Machines in the "Extraction of Groups" section should be replaced with k-means clustering), all in all it represents a relevant high-level roadmap. In particular, it should be useful for newcomers to data science.
Related: