Introducing TPU v4: Googles Cutting Edge Supercomputer for Large Language Models
TPU v4: Google's fifth domain-specific architecture and third supercomputer for machine learning models.
Image by Editor
Machine learning and artificial intelligence seem to be growing at a rapid rate that some of us can even keep up with. As these machine-learning models get better at what they do, they will require better infrastructure and hardware support to keep them going. The advancement of machine learning has a direct lead to scaling computing performance. So let’s learn more about TPU v4.
What is TPU v4?
TPU stands for Tensor Processing Unit and they were designed for machine learning and deep learning applications. TPU was invented by Google and was constructed in a way that it has the ability to be able to handle the high computational needs of machine learning and artificial intelligence.
When Google designed the TPU, they created it as a domain-specific architecture, which means they designed it as a matrix processor, instead of it being a general-purpose processor so that it specializes in neural network workloads. This solves Google's issue of memory access problem which slows down GPUs and CPUs, causing them to use more processing power.
So there’s been TPU v2, v3, and now v4. So what’s v2 all about?
The TPU v2 chip contains two TensorCores, four MXUs, a vector unit, and a scalar unit. See the image below:
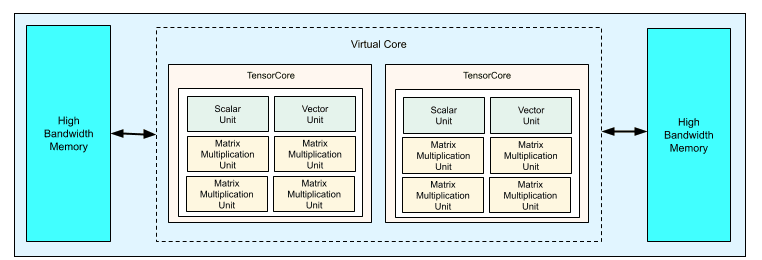
Image by Google
Optical Circuit Switches (OCSes)
TPU v4 is the first supercomputer to deploy reconfigurable optical circuit switches. Optical circuit switches (OCS) are considered to be more effective. They reduce congestion found in previous networks because they are transmitted as they occur. OCS improves scalability, availability, modularity, deployment, security, power, performance, and more.
OCSes and other optical components in TPU v4 make up less than 5% of TPU v4’s system cost and less than 5% of system power.
SparseCores
TPU v4 also is the first supercomputer with hardware support for embedding. Neural networks train well on dense vectors, and embeddings are the most effective way to transform categorical feature values into dense vectors. TPU v4 include third-generation SparseCores, which are dataflow processes that accelerate machine learning models that are reliant on embedding.
For example, the embedding function can translate a word in English, which would be considered a large categorical space into a smaller dense space of a 100-vector representation of each word. Embedding is a key element to Deep Learning Recommendation Models (DLRMs), which are part of our everyday lives and are used in advertising, search ranking, YouTube, and more.
The image below shows the performance of recommendation models on CPUs, TPU v3, TPU v4 (using SparseCore), and TPU v4 with embeddings in CPU memory (not using SparseCore). As you can see the TPU v4 SparseCore is 3X faster than TPU v3 on recommendation models, and 5–30X faster than systems using CPUs.
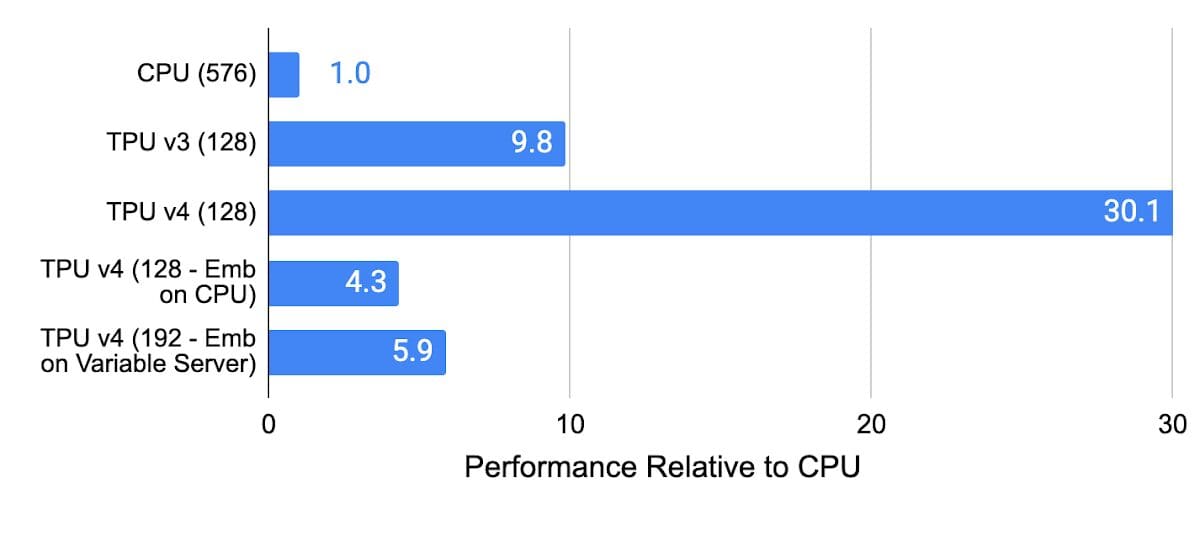
Image by Google
Performance
TPU v4 outperforms TPU v3 by 2.1x and has an improved performance/Watt by 2.7x. TPU v4 is 4x larger at 4096 chips, making it 10x faster. The implementation and flexibility of OCS are also major help for large language models.
The performance and availability of TPU v4 supercomputers are being heavily considered to improve large language models such as LaMDA, MUM, and PaLM. PaLM, the 540B-parameter model was trained on TPU v4 for over 50 days and had a remarkable 57.8% hardware floating point performance.
TPU v4 also has multidimensional model-partitioning techniques that enable low-latency, high-throughput inference for large language models.
Energy Efficiency
With more laws and regulations being put in place for companies globally to do better to improve their overall energy efficiency, TPU v4 is doing a decent job. TPU v4s inside Google Cloud use ~2-6x less energy and produce ~20x less CO2e than contemporary DSAs in typical on-premise data centres.
Machine Learning Workloads Changes
So now you know a bit more about TPU v4, you might be wondering how fast machine learning workloads actually change with TPU v4.
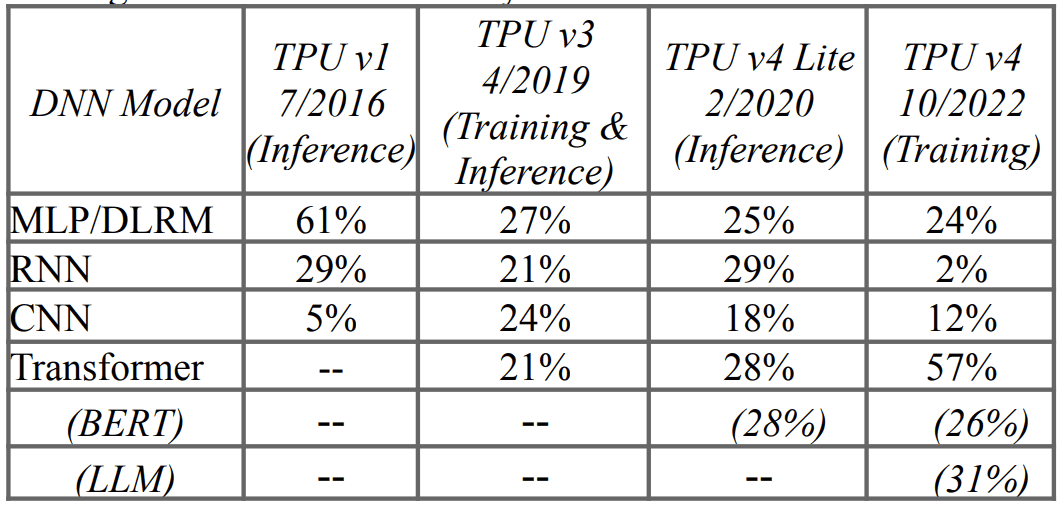
The below table shows the workload by deep neural network model type and the % TPUs used. Over 90% of training at Google is on TPUs, and this table shows the fast change in production workloads at Google.
There is a drop in recurrent neural networks (RNN), as this is because RNNs process the input all at once rather than sequentially, in comparison to transforms which are known for natural language translation and text summarization.
To learn more about TPU v4 capabilities, read the research paper TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings.
Wrapping it up
Last year, TPU v4 supercomputers were available to AI researchers and developers at Google Cloud’s ML cluster in Oklahoma. The author of this paper claims that the TPU v4 is faster and uses less power than Nvidia A100. However, they have not been able to compare the TPU v4 to the newer Nvidia H100 GPUs due to their limited availability and its 4nm architecture, whereas TPU v4 has a 7nm architecture.
What do you think TPU v4 is capable of, its limitations, and is it better than Nvidia A100 GPU?
Nisha Arya is a Data Scientist, Freelance Technical Writer and Community Manager at KDnuggets. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways Artificial Intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.