How to Improve Machine Learning Algorithms? Lessons from Andrew Ng, part 2
The second chapter of ML lessons from Ng’s experience. This one will only be talking about Human Level Performance & Avoidable Bias.
Welcome to the second chapter of ML lessons from Ng’s experience. This will be a short one and we will only be talking about Human Level Performance & Avoidable Bias. If you did not read the first chapter, here’s the link. Let’s get started! Oh and one more thing, this series is entirely based on a recent course by Andrew Ng on Coursera.
Comparing to Human Level Performance
In the last few years, a lot more machine learning teams have been talking about comparing the machine learning systems to human level performance. Why so?
- Because of advances in deep learning, the algorithms are suddenly working much better and have become much more feasible in a lot of application areas for machine learning
- Also, the workflow of designing and building a machine learning system is more efficient when you’re trying to do something that humans can also do
Over time, as you keep training your algorithm, it improves rapidly until it passes human level performance. Post which, it improves slowly. Although in no case can it surpass some theoretical limit called Bayes Optimal Error, the best possible error. In other words, any function’s mapping from x to y can not surpass a certain level of accuracy.
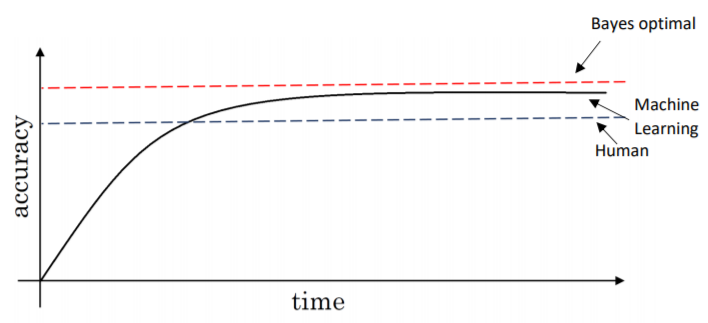
Usually, human and Bayes error are quite close, especially for natural perception problems, and there is little scope for improvement after surpassing human-level performance and thus, learning slows down considerably.
So long as your algorithm is doing worse than humans, following methods can be used to improve performance:
- Get labelled data from humans
- Gain insights from manual error analysis, e.g. understand why a human got this right
- Better analysis of Bias/Variance

Avoidable Bias
We want our algorithm to do well on training set but not too well (leading to overfitting). By knowing what the human-level performance is, it is possible to tell when a training set is performing well, too well or not well.
Example: Classification.
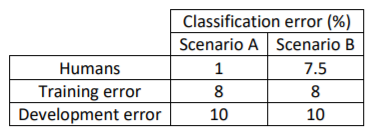
By taking human-level performance as proxy for Bayes error (say for image recognition), we can know if we need to focus on bias or variance avoidance tactics to improve our system’s performance.
Difference (Training Error, Human-Level Performance) = Avoidable Bias
Difference (Development Error, Training Error) = Variance
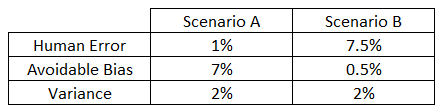
Scenario A:
The algorithm isn’t fitting well the training set since the target is around 1% and the bias is 7%. Use bias reduction techniques such as training a bigger neural network, or running the training set longer, or train better optimization algorithms (e.g. Adam’s), or change the NN architecture (use CNN, RNN etc.)
Scenario B:
The focus here should be to reduce the variance since the variance is 2% as compared to the avoidable bias which is just 0.5%. Use variance reduction techniques such as regularization, or have a bigger training set, tune the hyperparameters accordingly etc.
Note 1: The definition of human-level error depends on the purpose of the analysis. Take example of a medical image classification in which the input is a radiology image and the output is a diagnosis classification decision. A typical human has x% error, a doctor has (x-y) % error and a team of doctors have (x-y-z) % error. When taking proxy for Bayes error, you must take (x-y-z) as the error %.
Note 2: There are other problems where machine learning significantly surpasses human-level performance, especially with structured data. For example, Online Advertising, Recommendation Systems, Forecasting Systems, etc.
That’s all for this one. Thanks for reading! Let’s talk about error analysis, data mismatch, multi-tasking etc. in the next one.
If you have any questions/suggestions, feel free to reach out with your comments or connect with me on LinkedIn/Twitter
Original. Reposted with permission.
Related