The Importance of Reproducibility in Machine Learning
And how approaches to better data management, version control, and experiment tracking can help build reproducible ML pipelines.

Image by Author
When I was teaching myself machine learning, I’d often try to code along with project tutorials. I'll follow the steps that the author had outlined. But, sometimes, my model would perform worse than the tutorial author’s model. Maybe you’ve been in a similar situation, too. Or perhaps, you just pulled your colleague’s code from GitHub. And your model’s performance metrics are different from those that your colleague’s report claims. So doing the same thing doesn’t guarantee the same results, yes? This is a prevalent problem in machine learning: the challenge of reproducibility.
It’s needless to say: machine learning models are useful only when others can replicate the experiments and reproduce the results. From the typical “It works on my machine” problem to subtle changes in the way the machine learning model is trained, there are several challenges to reproducibility.
In this article, we’ll take a closer look at the challenges and importance of reproducibility in machine learning, along with the role of data management, version control, and experiment tracking in addressing the machine learning reproducibility challenge.
What Is Reproducibility in the Context of Machine Learning?
Let's see how we can best define reproducibility in the context of machine learning.
Suppose there is an existing project using a specific machine learning algorithm on a given dataset. Given the dataset and the algorithm, we should be able to run the algorithm (for as many times as we’d like) and reproduce (or replicate) the result in each of those runs.
But reproducibility in machine learning is not without challenges. We’ve already discussed a couple of them, let's go over them in more detail in the next section.
Challenges of Reproducibility in Machine Learning
For any application, there are challenges like reliability and maintainability. However, in machine learning applications, there are additional challenges.
When we talk about machine learning applications, we often refer to the end-to-end machine learning pipelines that usually include the following steps:
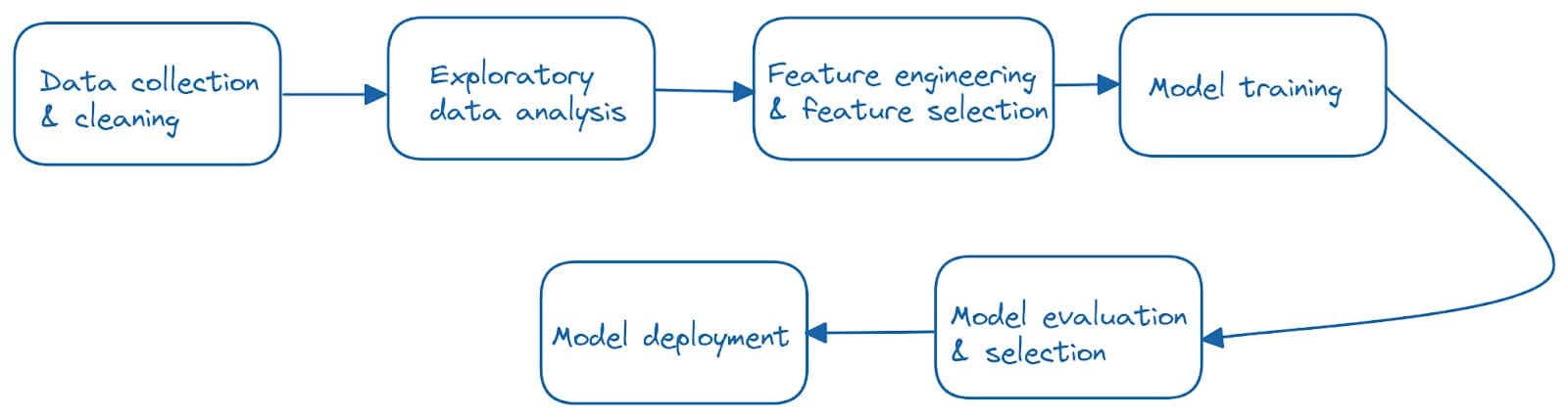
Image by Author
Therefore, reproducibility challenges can pop up due to changes in one or more of these steps. And most changes can be captured in one of the following:
- Environment changes
- Code changes
- Data changes
Let’s see how each of these changes hinder reproducibility.
Environment changes
Python and Python-based machine learning frameworks make developing ML apps a breeze. However, dependency management in Python—managing the different libraries and versions required for a given project—is a non trivial challenge. A small change such as using a different version of the library and a function call using a deprecated argument is enough to break the code.
This also includes the choice of operating systems. There are hardware-associated challenges such as the differences in GPU floating-point precision and the like.
Code changes
From the shuffling of the input dataset to determine which of the samples go into the training dataset to random initialization of weights when training neural networks – randomness plays an important role in machine learning.
Setting a different random seed can lead to totally different results. For every model that we train, there is a set of hyperparameters. So tweaking one or more of the hyper parameters can also lead to different results.
Data changes

Image by Author
Even with the same dataset, we’ve seen how inconsistencies in hyperparameter values and randomness can make it difficult to replicate the results. Therefore, it's obvious that, when the data changes—a change in the data distribution, modifications to a subset of records, or dropping of some samples—make it difficult to reproduce the results.
Summing up: when we try to replicate the results of a machine learning model, even the smallest of changes in the code, the dataset used, and the environment in which the machine learning model runs can prevent us from getting the same results as the original model.
How to Address the Reproducibility Challenge
We’ll now see how we can address these challenges.
Image by Author
Data Management
We saw that one of the most obvious challenges in reproducibility is with the data. There are certain data management approaches such as versioning the datasets so that we can track changes to the dataset, and storing useful metadata on the dataset.
Version Control
Any changes to the code should be tracked using a version control system such as Git.
In modern software development, you’d have come across CI/CD pipelines that make tracking changes, testing new changes, and pushing them to production much simpler and more efficient.
In other software applications, tracking changes to the code is straightforward. However, in machine learning, the code changes can also involve changes to the algorithm used and hyperparameter values. Even for simple models, the number of possibilities we can try out is combinatorially large. Here’s where experiment tracking becomes relevant.
Experiment Tracking
Building machine learning applications is synonymous with extensive experimentation. From algorithms to hyperparameters, we experiment with different algorithms and hyperparameter values. So it is important to track these experiments.
Tracking machine learning experiments includes:
- recording hyperparameter sweeps
- logging model’s performance metrics, model checkpoints
- Storing useful metadata about the dataset and model
Tools for ML Experiment Tracking, Data Management, and More
As seen, versioning datasets, tracking changes to code, and tracking machine learning experiments replicate machine learning applications. Here are some of the tools that can help you build reproducible machine learning pipelines:
Wrapping Up
To sum up, we’ve reviewed the importance and challenges of reproducibility in machine learning. We went over the approaches such as data and model versioning and experiment tracking. In addition, we also listed some of the tools you can use for experiment tracking and better data management.
The MLOps Zoomcamp by DataTalks.Club is an excellent resource to gain experience with some of these tools. If you like building and maintaining end to end machine learning pipelines, you might be interested in understanding the role of an MLOps engineer.
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more.