GitHub Copilot and the Rise of AI Language Models in Programming Automation
Read on to learn more about what makes Copilot different from previous autocomplete tools (including TabNine), and why this particular tool has been generating so much controversy.

Should I Use Github Copilot?
If you are a software engineer, or count any of them among your circle of acquaintances, then you're probably already aware at some level of Copilot. Copilot is GitHub's new deep learning code completion tool.
Autocomplete tools for programmers are nothing new, and Copilot is not even the first to make use of deep learning nor even the first to use a GPT transformer. After all, TabNine sprung out of a summer project by OpenAI alum Jacob Jackson and makes use of the GPT-2 general purpose transformer.
Microsoft (which owns GitHub) has packaged their own IntelliSense code completion tool with programming products since at least 1996, and autocomplete and text correction has been an active area of research since the 1950s.
Read on if you’d like to learn more about what makes Copilot different from previous autocomplete tools (including TabNine), and why this particular tool has been generating so much controversy.
Copyright Controversy
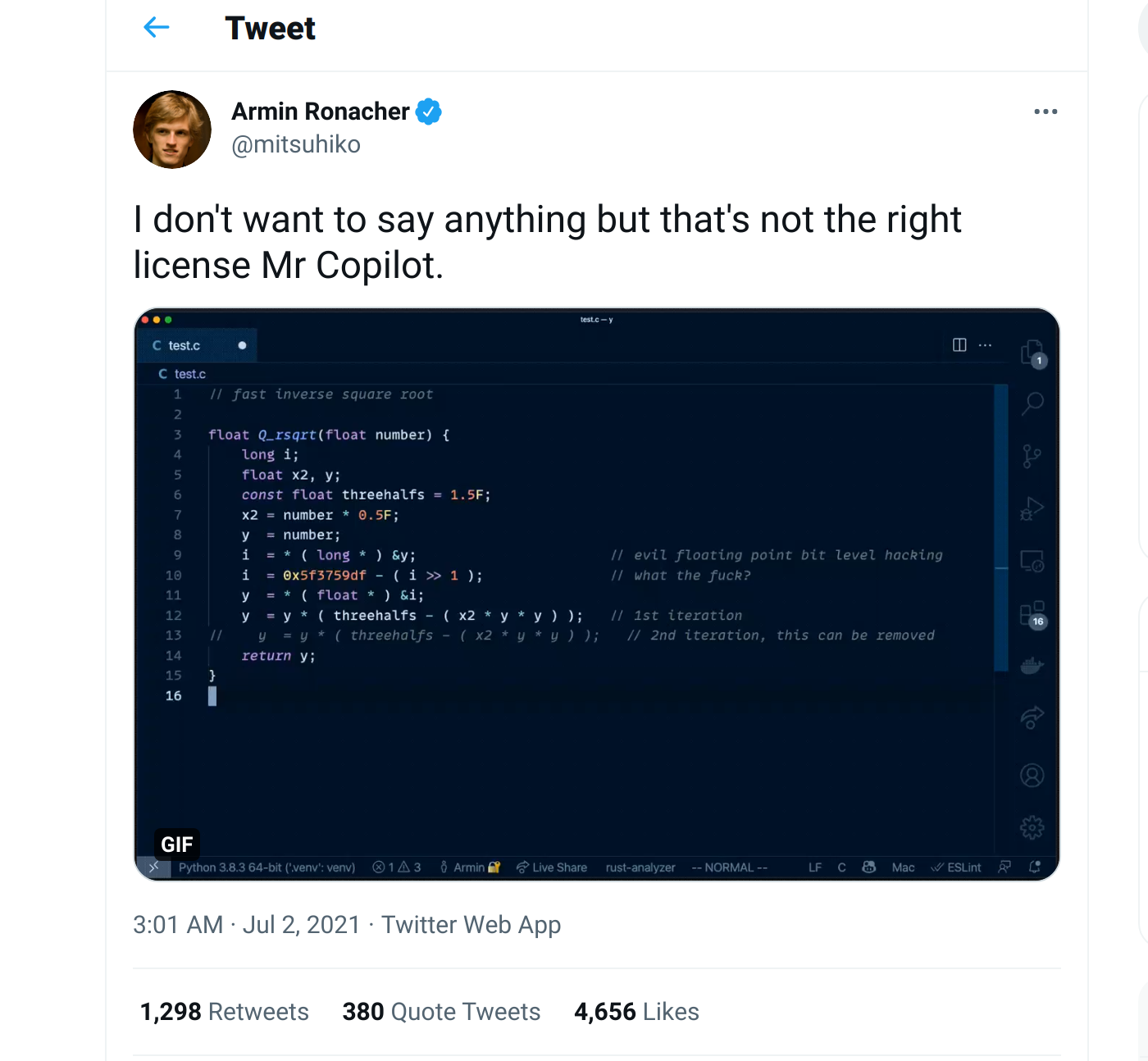
Screenshot of Armin Ronacher demonstrating GitHub Copilot’s eagerness to recite the fast inverse square root function from Quake III.
Since its inception, Copilot has fueled a heated discussion about the product and its potential copyright implications. In large part this is due to the way the model was trained. GitHub Copilot is based on OpenAI’s Codex, a variant of GPT-3 fine-tuned on code. GPT-3 is OpenAI’s 175 billion-parameter (Codex is apparently based on the 12-billion parameter version of GPT-3) general-purpose transformer, and of course any giant transformer needs a giant training dataset to be effective. GitHub is just the place to find such a dataset, and Copilot’s training dataset included all public code hosted by GitHub.
This is a principal source of controversy surrounding the project, surpassing the discussion about automating away software engineering and the impact of tools like Copilot on the future of programming. More technical information about the model and its limitations can be found in the paper on Arxiv.

Portrait of Edmond de Belamy.” Collective Obvious used open source code to generate the piece, later selling for over $400,000 at auction, much to the chagrin of Robbie Barrat, whose code they used.
Some programmers are simply upset that their code contributed to what is likely to become a paid product without their explicit permission, with a few commenters on hacker news discussing leaving the platform.
In some ways the reaction to Copilot echoes of the GAN-generated "painting” that sold for nearly half a million dollars at auction. The art piece was created on top of open source contributions with a lineage of multiple authors, none of whom received any compensation that we know of as reward for the noteworthy success of the work at auction.
The code used to produce the artwork, and potentially the pre-trained model weights as well, was made publicly available under a BSD license by the model’s author, Robbie Barrat, whose own work was based on previous open source projects and who later modified the license to disallow commercial use of the pre-trained weights. It’s understandable for programmers to be frustrated when left out of profitable uses of their work, but there’s more to the copyright controversy surrounding Copilot than that.
”github Copilot has, by their own admission, been trained on mountains of gpl code, so i'm unclear on how it's not a form of laundering open source code into commercial works.”-Twitter user eevee.
GitHub Copilot is demonstrably capable of reproducing extended sections of copyleft code, which many in the open source community consider a violation of the terms of licenses like GPL.
Copilot was trained on all public code, including permissive open source licenses like the MIT License. However, it also copyleft licenses like the Affero General Public License (AGPL) that allows use and modification, but requires modified works to be made available under the same license. In some interpretations, code generated by GitHub Copilot can be considered derivative of the original training data, and perhaps more problematically Copilot can sometimes reproduce code from the training dataset verbatim. That makes Copilot a trickier case than, say, the Google book-scanning precedent often cited as a cornerstone of fair use for scraping copyrighted data.
The discussion on potential legal issues continues with little consensus from either side of the debate for now, and the subject may very likely become an issue for the courts to resolve.
Even if we assume that Copilot is totally in the clear legally, there may be other risks to using the product. If Copilot’s training is considered fair use and its output is not considered derivative or copyright/copyleft infringing work, it could still produce output that easily fits the criteria for plagiarism in the context of something like a PhD student writing code for their thesis research. For the time being it may be a good idea to use Copilot carefully, but there’s another reason that Copilot is a trending topic of discussion: Copilot can give surprisingly good solutions to common programming tasks, and appears to be both quantitatively and qualitatively more capable than previous autocomplete tools.
How Good is GitHub’s Copilot?

GitHub Copilot CRUSHES Leetcode Interview Questions! Source
Even if you’re not a programmer, you’ve probably had some experience with autocomplete in the form of predictive text on a mobile phone. This will automatically suggest the next word as you begin to type it, and may suggest a slightly longer continuation such as to finish the current sentence.
For most programming autocomplete tools the amount and complexity of suggestions is roughly similar to what you’d find in a mobile phone keyboard, but not all code completion tools use modern (aka deep learning) machine learning.
The default autocomplete in vim, for example, will simply offer a list of suggested completions based on the words that a user has entered previously. More recently developed code completion tools like TabNine or Kite are a little more sophisticated and can suggest the completion of the rest of a line or two. The Kite website suggests this is enough to make a programmer nearly twice as efficient in terms of the number of keystrokes used, but Github Copilot takes this one step further, albeit with a very long stride.
Copilot has similar completion capabilities to the standard language GPT-3 it is based on, and working with the code completion tool looks and feels similar to the style of “prompt programming” that GPT-3 experimenters have adopted when working with the model. Copilot can interpret the contents of a docstring and write a function to match, or given a function and the start of an appropriately named test function it can generate unit tests. That saves a lot more than 50% of a programmer’s keystrokes.
Taken to its logical conclusion, when Copilot works perfectly it turns the job of a software engineer into something that looks a lot more like constant code review than writing code.
Several programmer-bloggers with early access to the technical preview version have put Copilot to the test by essentially challenging the model to solve interview-level programming problems. Copilot is pretty impressive in how well it can solve these types of challenges, but not good enough to warrant using its output without carefully reviewing it first.
Several online software engineers have put the “AI pair programmer” (as GitHub puts it) to the test. We’ll go through some of the points identified in the Arxiv paper as scenarios where Codex falls short and try to find examples in the experiments conducted by programmers involved in the technical preview.
The HumanEval Dataset
OpenAI Codex is a ~12 billion parameter GPT-3 fine-tuned on code, with Codex-S being the most advanced variant of Codex itself. To evaluate the performance of this model, OpenAI built what they call the HumanEval dataset: a collection of 164 hand-written programming challenges with corresponding unit tests, the sort you might find on a coding practice site like CodeSignal, Codeforces, or HackerRank.
In HumanEval, the problem specifications are included in function docstrings, and the problems are all written for the Python programming language.
While an undifferentiated GPT-3 without code-specific was unable to solve any of the problems in the HumanEval dataset (at least on the first try), the fine-tuned Codex and Codex-S were able to solve 28.8% and 37.7% of problems, respectively. By cherry-picking from the top-100 attempts at the problems, Codex-S was further able to solve 77.5% of problems.
One way to interpret this is that if a programmer was using Codex, they could expect to find a valid solution to a problem (at roughly the level of complexity encountered in technical interviews) by looking through the first 100 suggestions, or even blindly throwing attempted solutions at a valid set of unit tests until they pass. That’s not to say a better solution can’t be found, if a programmer is willing to modify suggestions from Codex, in one of the first few suggestions.
They also used a more complicated estimator for solving each problem by generating around 200 samples and calculating an unbiased estimator of the proportion of samples that pass unit tests, which they report as “pass@k” where k is 100, the number of samples being estimated. This method has a lower variance than reporting pass@k directly.
The Best Codex Model Still Under-Performs a Computer Science Student
The authors of Codex note that, being trained on over 150GB in hundreds of millions of lines of code from GitHub, the model has been trained on significantly more code than a human programmer can expect to read over the course of their careers. However, the best Codex model (Codex-S with 12 billion parameters) still under-performs the abilities of a novice computer science student or someone who spends a few afternoons practicing interview-style coding challenges.
In particular, Codex performance degrades rapidly when chaining together several operations in a problem specification.
In fact, the ability of Codex to solve several operations chained together drops by a factor of 2 or worse for each additional instruction in the problem specification. To quantify this effect, the authors at OpenAI built an evaluation set of string manipulations that could operate sequentially (change to lowercase, replace every other character with a certain character, etc.). For a single string manipulation, Codex passed nearly 25% of problems, dropping to just below 10% for 2 string manipulations chained together, 5% for 3, and so on.
The rapid drop-off in solving multi-step problems was seen by an early Copilot reviewer Giuliano Giacaglia on Medium. Giuliano reports giving Copilot a problem description of reversing the letters in each word in an input string, but instead Copilot suggested a function that reverses the order of words in a sentence, not letters in a sentence of words (“World Hello” instead of “olleH dlroW”). Copilot did, however, manage to write a test that failed for its own implementation.
Although not sticking to the multi-step string manipulation paradigm used by Giuliano and OpenAI to test Copilot, Kumar Shubham discovered an impressive result when Copilot successfully solved a multi-step problem description that involved calling system programs to take a screenshot, run optical character recognition on the image, and finally extract email addresses from the text. That does, however, raise the issue that Copilot may write code that relies on unavailable, out-of-date, or untrusted external dependencies. That’s a point raised by OpenAI alongside the model’s susceptibility to bias, ability to generate security vulnerabilities, and potential economic and energy costs in the section of their paper discussing risks.
Other reviews of Copilot by YouTubers DevOps Directive and Benjamin Carlson found impressive results when challenging Copilot with interview-style questions from leetcode.com, including some that seemed significantly more complex than chaining together a series of simple string manipulations. The difference in the complexity of code that Copilot can generate and the complexity of problem specifications that Copilot can understand is striking.
Perhaps the prevalence of code written in the style of interview practice questions in the training dataset leads to Copilot overfitting those types of problems, or perhaps it is just more difficult to chain together several steps of modular functionality than it is to churn out a big chunk of complex code that is very similar to something the model has seen before. Poorly described and poorly interpreted specifications are already a common source of complaints for engineers and their managers of the human variety, so perhaps it should not be so surprising to find an AI coding assistant fails to excel at parsing complicated problem specifications.
Copilot Alternatives
As of this writing, Copilot is still limited to programmers lucky enough to be enrolled in the technical preview, but fear not: myriad of other code completion assistants (whether using deep learning or not) are readily available to try out and it’s not a bad time to reflect on what increasing automation might mean for software engineering.
Earlier we mentioned TabNine, a code completion tool based in part on OpenAI’s GPT-2 transformer. Originally built by Jacob Jackson and now owned by codota, TabNine was able to solve 7.6% of the HumanEval benchmark in the pass@100 metric used by OpenAI authors. That’s fairly impressive considering that TabNine was designed to be a more hands-on code completion solution, unlike Codex which was explicitly inspired by the potential of GPT-3 models to produce code from problem descriptions. TabNine has been around since 2018 and has both free and paid versions.
Kite is another code completion tool in the same vein as TabNine, with free (desktop) and paid (server) versions that differ in the size of the model used by a factor of 25. According to Kite’s usage statistics, coders choose to use the suggested completions often enough to cut their keystrokes in half compared to manually typing out every line, and Kite’s cite their users’ self-reported productivity boost of 18%. Going by the animated demos on their website, Kite definitely suggests shorter completions than both TabNine and Copilot. This differs in degree from TabNine, which suggests only slightly longer completions for the most part, but it's qualitatively different from Copilot: Copilot can suggest extended blocks of code and changes the experience from choosing the best completion to code reviewing several suggested approaches to the problem.
Is Copilot Here to Take Your Job or Just Your Code?
GitHub Copilot has some software engineers joking that the automation they’ve been building for years is finally coming home to roost, and soon we’ll all be out of a job. In reality this is very unlikely to be the case for many years as there is more to programming than just writing code.
Besides, it’s an oft-repeated trope that even interpreting exactly what a client or manager wants in a set of software specifications is more of an art than a science.
On the other hand, Copilot and other natural language code completion tools like it (and trust us, more are coming) are indeed likely to have a big impact on the way software engineers do their jobs. Engineers will probably spend more time reviewing code and checking tests, whether the code under scrutiny was written by an AI model or a fellow engineer. We’ll probably also see another layer of meta to the art of programming as “prompt programming” of machine learning programming assistants becomes commonplace.
As cyberpunk author William Gibson put it all those years ago: “the future is already here — it’s just not evenly distributed.”
Copilot has also ignited a debate on copyright, copyleft, and all manner of open source licenses and the philosophy of building good technology, which is a discussion that needs to take place sooner rather than later. Additionally, most contemporary interpretations of intellectual property require a human author for a work to be eligible for copyright. As more code is written in larger proportions by machine learning models instead of humans, will those works legally enter the public domain upon their creation?
Who knows? Perhaps the open source community will finally win in the end, as the great-great-great successor to Copilot becomes a staunch open source advocate and insists on working only on free and open source software.
Bio: Kevin Vu manages Exxact Corp blog and works with many of its talented authors who write about different aspects of Deep Learning.
Original. Reposted with permission.
Related:
- GitHub Copilot Open Source Alternatives
- Managing Your Reusable Python Code as a Data Scientist
- GitHub Copilot: Your AI pair programmer – what is all the fuss about?