The Difference Between L1 and L2 Regularization
Two types of regularized regression models are discussed here: Ridge Regression (L2 Regularization), and Lasso Regression (L1 Regularization)
Key Takeaways
- Regularized regression can be used for feature selection and dimensionality reduction
- Two types of regularized regression models are discussed here: Ridge Regression (L2 Regularization), and Lasso Regression (L1 Regularization)
Basic Linear Regression
Suppose we have a dataset with  features and observations as shown below:
features and observations as shown below:

A basic regression model can be represented as follows:
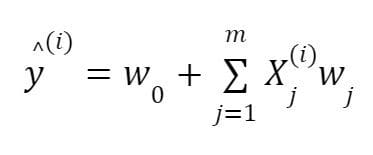
where is the feature matrix, and are the weight coefficients or regression coefficients. In basic linear regression, the regression coefficients are obtained by minimizing the loss function given below:
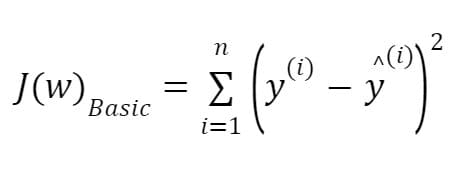
Ridge Regression: L2 Regularization
In L2 regularization, the regression coefficients are obtained by minimizing the L2 loss function, given as:
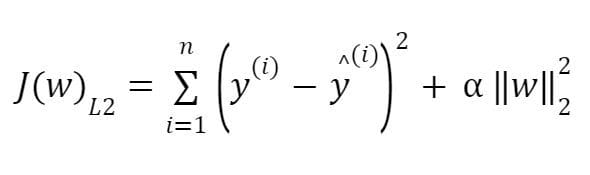
where
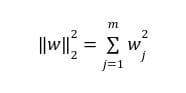
Here, α ∈[0, 1] is the regularization parameter. L2 regularization is implemented in Python as:
from sklearn.linear_model import Ridge lasso = Ridge(alpha=0.7) Ridge.fit(X_train_std,y_train_std) y_train_std=Ridge.predict(X_train_std) y_test_std=Ridge.predict(X_test_std) Ridge.coef_
Lasso Regression: L1 Regularization
In L1 regularization, the regression coefficients are obtained by minimizing the L1 loss function, given as:

where
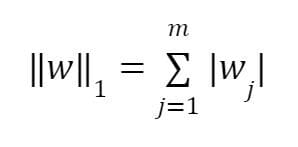
L1 regularization is implemented in Python as:
from sklearn.linear_model import Lasso lasso = Lasso(alpha=0.7) lasso.fit(X_train_std,y_train_std) y_train_std=lasso.predict(X_train_std) y_test_std=lasso.predict(X_test_std) lasso.coef_
In both L1 and L2 regularization, when the regularization parameter (α ∈[0, 1]) is increased, this would cause the L1 norm or L2 norm to decrease, forcing some of the regression coefficients to zero. Hence, L1 and L2 regularization models are used for feature selection and dimensionality reduction. One advantage of L2 regularization over L1 regularization is that the L2 loss function is easily differentiable.
Case Study: L1 Regression Implementation
An implementation of L1 regularization using the cruise ship dataset can be found here: Implementation of Lasso Regression.
The plot below is a plot of the R2 score and the L1 norm as a function of the regularization parameter.
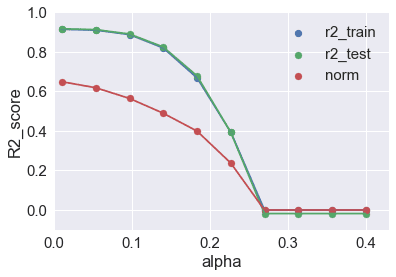
We observe from the figure above that as the regularization parameter α increases, the norm of the regression coefficients become smaller and smaller. This means more regression coefficients are forced to zero, which intend increases bias error (over simplification). The best value to balance bias-variance tradeoff is when α is kept low, say α=0.1 or less.
Benjamin O. Tayo is a Physicist, Data Science Educator, and Writer, as well as the Owner of DataScienceHub. Previously, Benjamin was teaching Engineering and Physics at U. of Central Oklahoma, Grand Canyon U., and Pittsburgh State U.