Development & Testing of ETL Pipelines for AWS Locally
Typically, development and testing ETL pipelines is done on real environment/clusters which is time consuming to setup & requires maintenance. This article focuses on the development and testing of ETL pipelines locally with the help of Docker & LocalStack. The solution gives flexibility to test in a local environment without setting up any services on the cloud.
By Subhash Sreenivasachar, Software Engineer Technical Lead at Epsilon
Introduction
AWS plays a pivotal role in helping engineers, data-scientists focus on building solutions and problem solving without worrying about the need to setup infrastructure. With Serverless & pay-as-you-go approach for pricing, AWS provides ease of creating services on the fly.
AWS Glue is widely used by Data Engineers to build serverless ETL pipelines. PySpark being one of the common tech-stack used for development. However, despite the availability of services, there are certain challenges that need to be addressed.
Debugging code in AWS environment whether for ETL script (PySpark) or any other service is a challenge.
- Ongoing monitoring of AWS service usage is key to keep the cost factor under control
- AWS does offer Dev Endpoint with all the spark libraries installed, but considering the price, it’s not viable for use for large development teams
- Accessibility of AWS services may be limited for certain users
Solution
Solutions for AWS can be developed, tested in local environment without worrying about accessibility or cost factor. Through this article, we are addressing two problems -
- Debugging PySpark code locally without using AWS dev endpoints.
- Interacting with AWS Services locally
Both problems can be solved with use of Docker images.
- First, we do away the need for a server on AWS environment & instead, a docker image running on the machine acts as the environment to execute the code.
AWS provides a sandbox image which can be used for PySpark scripts. Docker image can be setup to execute PySpark Code. https://aws.amazon.com/blogs/big-data/developing-aws-glue-etl-jobs-locally-using-a-container/
- With docker machine available to execute the code, there’s a need for a service like S3 to store (read/write) files while building an ETL pipeline.
Interactions with S3 can be replaced with LocalStack which provides an easy-to-use test/mocking framework for developing Cloud applications. It spins up a testing environment on your local machine that provides the same functionality and APIs as the real AWS cloud environment.
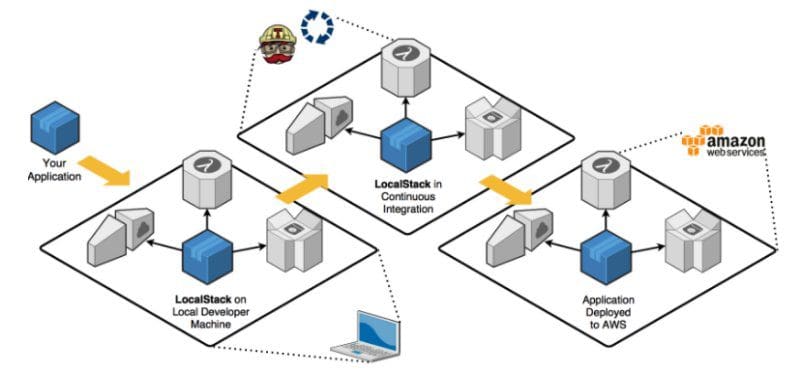
So far, the article deals with building an ETL pipeline and use of services available. However, similar approach can be adapted to any use case while working with AWS services like SNS, SQS, CloudFormation, Lambda functions etc.
Approach
- Use docker containers as remote interpreter
- Run PySpark session on the containers
- Spin up S3 service locally using LocalStack
- Use PySpark code to read and write from S3 bucket running on LocalStack
Pre-requisites
Following tools must be installed on your machine
- Docker
- PyCharm Professional/ VisualStudio Code
Setup
- Download or pull docker images (docker pull <image name>)
- libs:glue_libs_1.0.0_image_01
- localstack/localstack
- Docker containers can be used as remote interpreters in PyCharm professional version.
Implementation
With Docker installed and images pulled to your local machine, start setting PyCharm with configurations to start the containers.
- Create a docker-compose.yml file
version: '2'
services:
glue-service:
image: amazon/aws-glue-libs:glue_libs_1.0.0_image_01
container_name: "glue_ontainer_demo"
build:
context: .
dockerfile: Dockerfile
ports:
- "8000:8000"
volumes:
- .:/opt
links:
- localstack-s3
environment:
S3_ENDPOINT: http://localstack:4566
localstack-s3:
image: localstack/localstack
container_name: "localstack_container_demo"
volumes:
- ./stubs/s3:/tmp/localstack
environment:
- SERVICES=s3
- DEFAULT_REGION=us-east-1
- HOSTNAME=localstack
- DATA_DIR=/tmp/localstack/data
- HOSTNAME_EXTERNAL=localstack
ports:
- "4566:4566"
- Create a DockerFile
FROM python:3.6.10 WORKDIR /opt # By copying over requirements first, we make sure that Docker will cache # our installed requirements rather than reinstall them on every build COPY requirements.txt /opt/requirements.txt RUN pip install -r requirements.txt # Now copy in our code, and run it COPY . /opt
- Use requirements file with packages to be installed
moto[all]==2.0.5
- Setup Python remote interpreter
- Setup Python interpreter using the docker-compose file.
- Select `glue-service` in PyCharm Docker Compose settings.
- Docker-compose file creates and runs the containers for both images
- LocalStack by default runs on port 4566 and S3 service is enabled on it
Code
- Required libraries to be imported
import boto3 import os from pyspark.sql import SparkSession
- Add a file to S3 bucket running on LocalStack
def add_to_bucket(bucket_name: str, file_name: str):
try:
# host.docker.internal
s3 = boto3.client('s3',
endpoint_url="http://host.docker.internal:4566",
use_ssl=False,
aws_access_key_id='mock',
aws_secret_access_key='mock',
region_name='us-east-1')
s3.create_bucket(Bucket=bucket_name)
file_key = f'{os.getcwd()}/{file_name}'
with open(file_key, 'rb') as f:
s3.put_object(Body=f, Bucket=bucket_name, Key=file_name)
print(file_name)
return s3
except Exception as e:
print(e)
return None
http://host.docker.internal:4566 is the S3 running locally inside docker container
- Setup PySpark session to read from S3
def create_testing_pyspark_session():
print('creating pyspark session')
sparksession = (SparkSession.builder
.master('local[2]')
.appName('pyspark-demo')
.enableHiveSupport()
.getOrCreate())
hadoop_conf = sparksession.sparkContext._jsc.hadoopConfiguration()
hadoop_conf.set("fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
hadoop_conf.set("fs.s3a.path.style.access", "true")
hadoop_conf.set("fs.s3a.connection.ssl.enabled", "false")
hadoop_conf.set("com.amazonaws.services.s3a.enableV4", "true")
hadoop_conf.set("fs.s3a.aws.credentials.provider", "org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider")
hadoop_conf.set("fs.s3a.access.key", "mock")
hadoop_conf.set("fs.s3a.secret.key", "mock")
hadoop_conf.set("fs.s3a.session.token", "mock")
hadoop_conf.set("fs.s3a.endpoint", "http://host.docker.internal:4566")
return sparksession
- PySpark session connects to S3 via mock credentials provided
- You can read from S3 directly using the PySpark session created
test_bucket = 'dummypysparkbucket'
# Write to S3 bucket
add_to_bucket(bucket_name=test_bucket, file_name='dummy.csv')
spark_session = create_testing_pyspark_session()
file_path = f's3a://{test_bucket}/dummy.csv'
# Read from s3 bucket
data_df = spark_session.read.option('delimiter', ',').option('header', 'true').option('inferSchema',
'False').format('csv').load(
file_path)
print(data_df.show())
- Finally, it’s possible to write to S3 in any preferred format
# Write to S3 as parquet
write_path = f's3a://{test_bucket}/testparquet/'
data_df.write.parquet(write_path, mode='overwrite')
Once the above-mentioned steps have been followed, we can create a dummy csv file with mock data for testing and you should be good to
- Add file to S3 (which is running on LocalStack)
- Read from S3
- Write back to S3 as parquet
You should be able to run the .py file to execute & PySpark session will be created that can read from S3 bucket which is running locally using LocalStack API.
Additionally, you can also check if LocalStack is running with http://localhost:4566/health
LocalStack provides you ability to run commands using AWS CLI as well.
Conclusion
Use of Docker & Localstack provides a quick and easy way to run Pyspark code, debug on containers and write to S3 which is running locally. All this without having to connect to any AWS service.
References:
- Glue endpoint: https://docs.aws.amazon.com/glue/latest/dg/dev-endpoint.html
- Docker: https://docs.docker.com/get-docker/
- PyCharm: https://www.jetbrains.com/pycharm/
- PyCharm Remote interpreter: https://www.jetbrains.com/help/pycharm/using-docker-compose-as-a-remote-interpreter.html
- LocalStack: https://localstack.cloud
Bio: Subhash Sreenivasachar is Lead Software Engineer at Epsilon Digital Experience team, building engineering solutions to solve data science problems specifically personalization, and help drive ROI for clients.
Related:
- MLOps is an Engineering Discipline: A Beginner’s Overview
- ETL in the Cloud: Transforming Big Data Analytics with Data Warehouse Automation
- What’s ETL?