Deep Learning for Virtual Try On Clothes – Challenges and Opportunities
Learn about the experiments by MobiDev for transferring 2D clothing items onto the image of a person. As part of their efforts to bring AR and AI technologies into virtual fitting room development, they review the deep learning algorithms and architecture under development and the current state of results.
By Maksym Tatariants, Data Science Engineer at MobiDev.
The research described below was held by MobiDev as a part of an investigation on bringing AR & AI technologies for virtual fitting room development.
Exploring 2D Cloth Transfer onto an Image of a Person
When working on virtual fitting room apps, we conducted a series of experiments with virtual try on clothes and found out that the proper rendering of a 3D clothes model on a person still remains a challenge. For a convincing AR experience, the deep learning model should detect not only the basic set of keypoints corresponding to the joints of the human body. It should also identify the body's actual shape in three dimensions so that the clothing could be appropriately fitted to the body.
For an example of this model type, we can look at the DensePose by the Facebook research team (Fig. 1). However, this approach is not accurate, slow for mobile, and expensive.

Figure 1: Body mesh detection using DensePose (source).
So, it is required to search for simpler alternatives to virtual clothing try-on techniques.
A popular option here is, instead of going for fitting 3D clothing items, working with 2D clothing items and 2D person silhouettes. It is exactly what Zeekit company does, giving users a possibility to apply several clothing types (dresses, pants, shirts, etc.) to their photo.
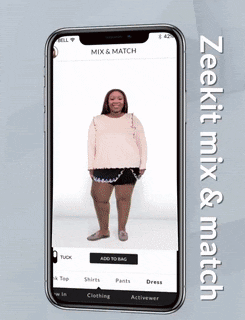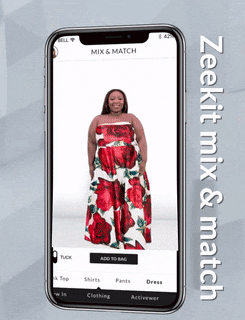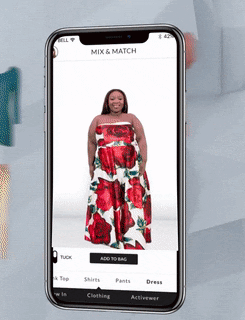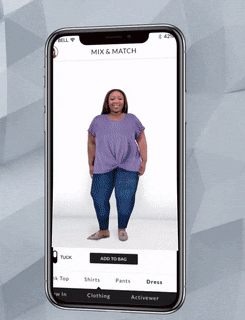
Figure 2: 2D clothing try-on, Zeekit (source, 0:29 - 0:39).
Since the cloth transferring techniques used by the company have not been revealed besides incorporating deep learning models, let's refer to scientific articles on the topic. Upon reviewing several of the most recent works (source 1, source 2, source 3), the predominant approach to the problem is to use Generative Adversarial Networks (GANs) in combination with Pose Estimation and Human Parsing models. The utilization of the last two models helps identify the areas in the image corresponding to specific body parts and determine the position of body parts. The use of Generative Models helps produce a warped image of the transferred clothing and apply it to the image of the person so as to minimize the number of produced artifacts.
Selected Model and Research Plan
For this research, we chose the Adaptive Content Generating and Preserving Network (ACGPN) model described in the “Towards Photo-Realistic Virtual Try-On by Adaptively GeneratingPreserving↔Image Content” paper. In order to explain how ACGPN works, let’s review its architecture shown in Fig. 3.
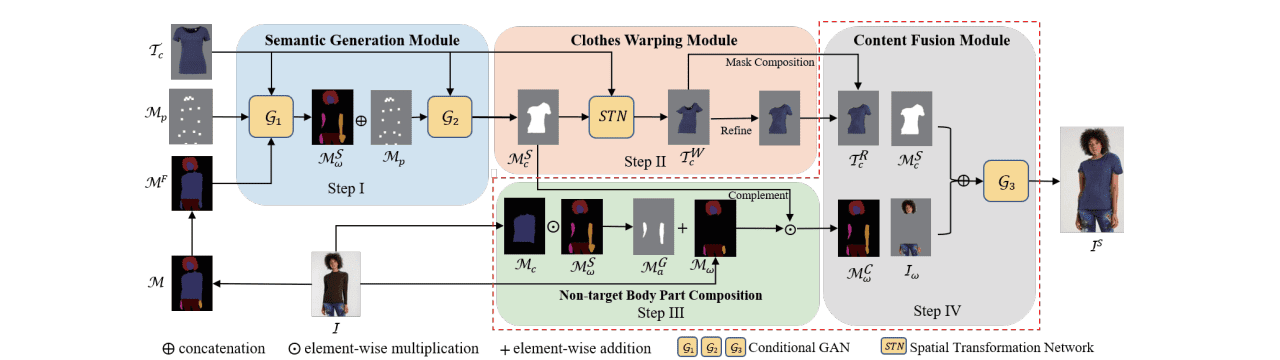
Figure 3: Architecture of the ACGPN model (credit: Yang et al.,2020).
The model consists of three main modules: Semantic Generation, Clothes Warping, and Content Fusion.
The Semantic Generation module receives the image of a target clothing and its mask, data on the person's pose, a segmentation map with all the body parts (hands are especially important), and clothing items identified.
The first generative model (G1) in the Semantic Generation module modifies the person’s segmentation map so that it clearly identifies the area on the person’s body that should be covered with the target clothes. Having this information received, the second generative model (G2) warps the clothing mask so as to correspond to the area it should occupy.
After that, the warped clothing mask is passed to the Clothes Warping module, where the Spatial Transformation Network (STN) warps the clothing image according to the mask. And finally, the warped clothing image, the modified segmentation map from Semantic Generation Module, and a person’s image are fed into the third generative module (G3), and the final result is produced.
For testing the capabilities of the selected model, we went through the following steps in the order of increasing difficulty:
- Replication of the authors’ results on the original data and our preprocessing models (Simple).
- Application of custom clothes to default images of a person (Medium).
- Application of default clothes to custom images of a person (Difficult).
- Application of custom clothes to custom images of a person (Very difficult).
Replication of the Authors’ Results on the Original Data and Our Preprocessing Models
The authors of the original paper did not mention the models they used to create person segmentation labels and detect the keypoints on a human body. Thus, we picked the models ourselves and ensured the quality of the ACGPN model’s outputs were similar to the one reported in the paper.
As a keypoint detector, we chose the OpenPose model because it provided the appropriate order of keypoints (COCO keypoint dataset) and was used in other researches related to the virtual try-on for clothes replacement.
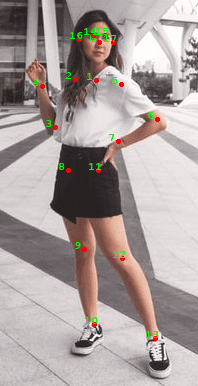
Figure 4: Example of COCO keypoint detections using OpenPose.
We chose the SCHP model presented in the Self Correction for Human Parsing paper for the body part segmentation. This model utilizes the common for human parsing architecture CE2P with some modifications of the loss functions.
SCHP segmentation model uses a pre-trained backbone (encoder) to extract features from the input image. The recovered features are then used for the contour prediction of the person in the edge branch and the person segmentation in the parsing branch. The outputs of these two branches alongside feature maps from the encoder were fed into the fusion branch to improve the segmentation maps' quality.
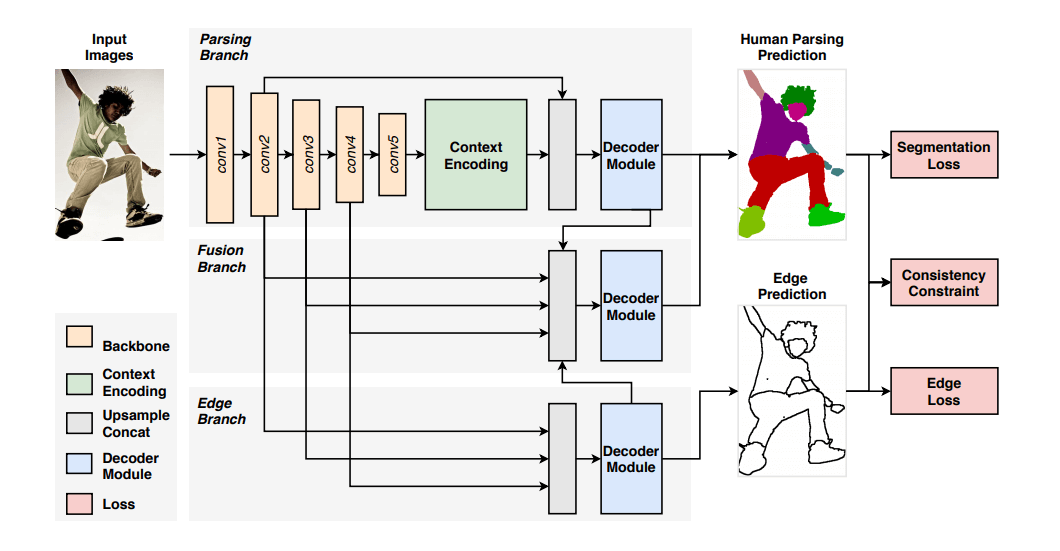
Figure 5: Architecture of the SCHP model (based on CE2P), image credit – Li, et al.
Another new element in the SCHP model is the self-correction feature used to iteratively improve the model’s prediction on noisy ground truth labels. These labels are commonly used in human parsing tasks since it can be difficult for human annotators to produce segmentation labels. During this process, the model, firstly trained on inaccurate human annotations, is aggregated with new models trained on pseudo-ground truth masks obtained from the previously trained model.
The process is repeated several times until both the model and pseudo-ground truth masks reach better accuracy. For the human parsing task, we used the model trained on the Look Into Person (LIP) dataset because it is the most appropriate for this task.
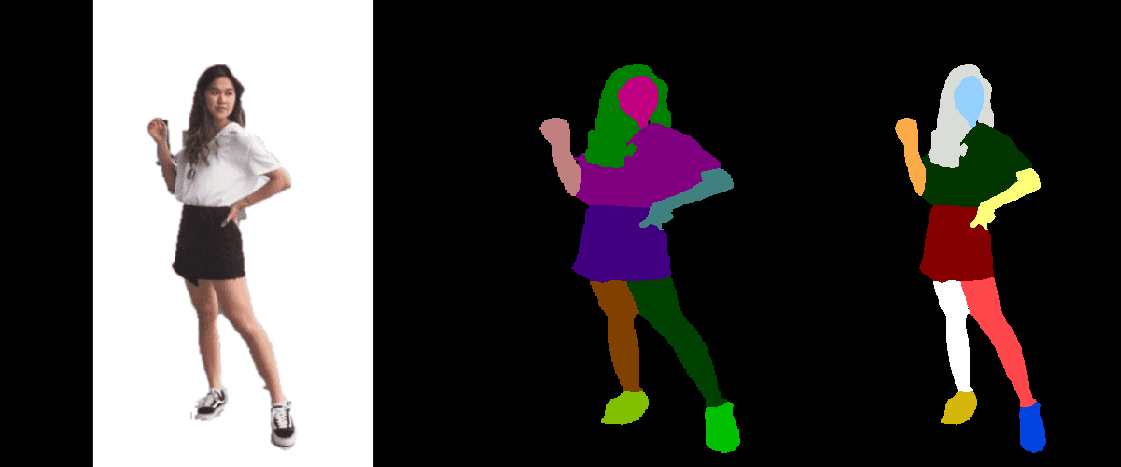
Figure 6: Examples of human parsing using SCHP model (person - left, segmentation - right).
Finally, when the keypoint and human parsing models were ready, we used their outputs for running the ACGPN model on the same data used by the authors for training. In the image below, you can see the results we obtained from the VITON dataset.
The semantic generation module modifies the original segmentation so that it reflects the new clothing type. For example, the pullover on the original image has long sleeves, whereas the target cloth (T-shirt) has short sleeves. Therefore, the segmentation mask should be modified so that the arms are more revealed. This transformed segmentation is then used by the Content Fusion module to inpaint modified body parts (e.g., draw naked arms), and it is one of the most challenging tasks for the system to perform (Fig. 7).

Figure 7: Inputs and outputs of the ACGPN model.
In the image below (Fig. 8), you can see the compilation results of successful and unsuccessful clothing replacement using the ACGPN model. The most frequent errors we encountered were poor inpainting (B1), new clothing overlapping with body parts (B2), and edge defects (B3).
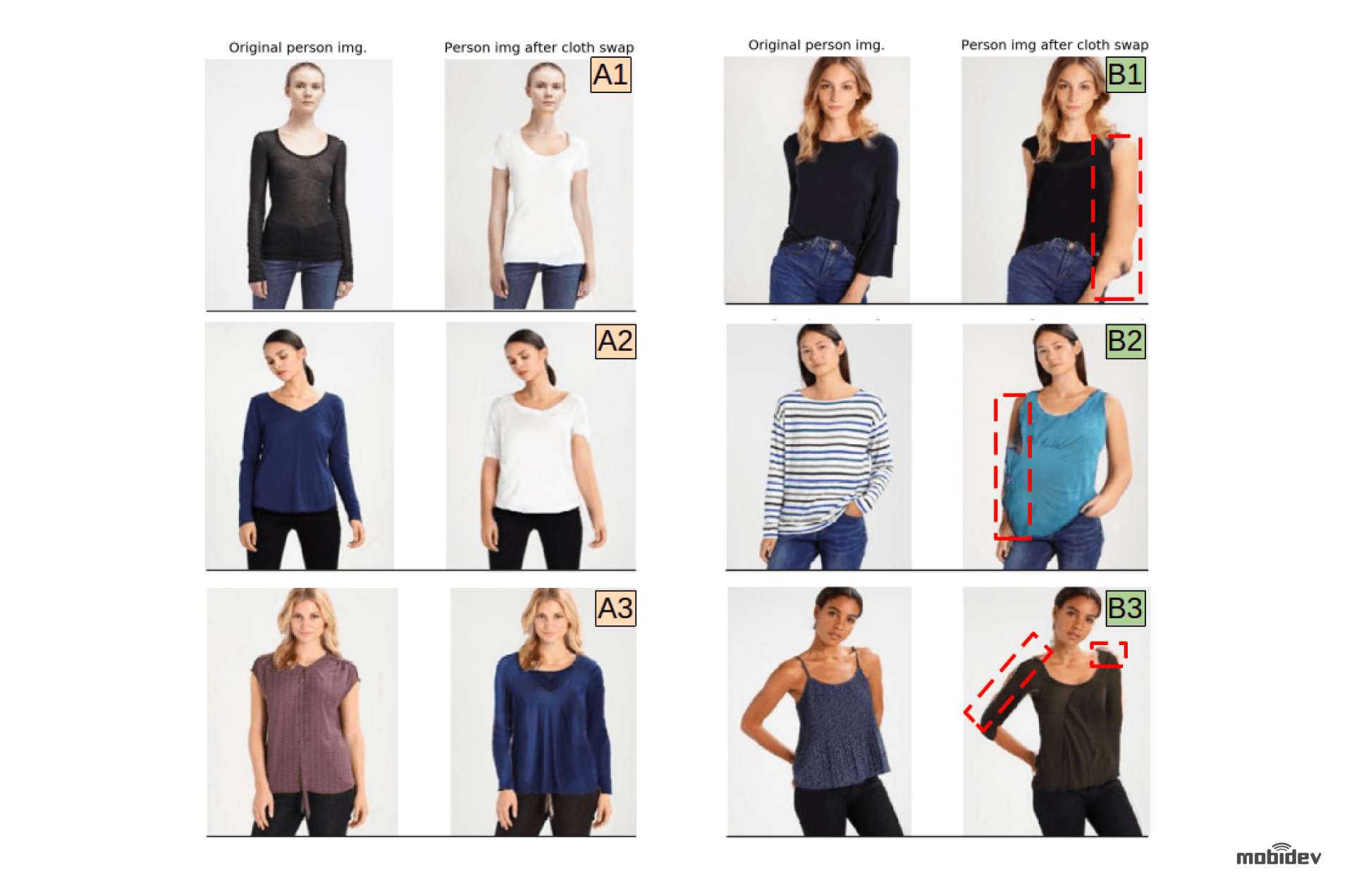
Figure 8: Successful (A1-A3) and unsuccessful (B1-B3) replacement of clothing. Artefacts are marked with red rectangles.
Application of Custom Clothes to Default Person Images
For this experiment, we picked several clothing items (Fig. 9) and applied them to images of a person from the VITON dataset. Please note that some images are not real clothing photos, but 3D renders or 2D drawings.

Figure 9: Clothing images used for virtual try-on (A - photo of an item, B, C - 3D renders, D - 2D drawing).
Moving on to the results of clothing replacement (Fig. 10), we can see that they may be roughly split into three groups.

Figure 10: Examples of clothing replacement using custom clothes (Row A - successful with minor artifacts, Row B - moderate artifacts, Row C - major artifacts).
The images in Row A have no defects and look the most natural. This can be attributed to the fact that people in the images have a similar upright, facing camera pose. As the authors of the paper explained, such a pose makes it easier for the model to define how the new clothing should be warped and applied to the person’s image.
The images in Row B present the more challenging pose to be processed by the model. The person’s torso is slightly bent, and arms partially occlude the body area where the clothing is supposed to be applied. As shown in Fig. 8, a bent torso results in the edge defects. Notice that difficult long-sleeve clothing (item C from Fig. 9) is processed correctly. It is because sleeves should go through complicated transformations to be appropriately aligned with the person’s arms. It is incredibly complicated if the arms are bent or their silhouette is occluded by clothing in the original image.
The images in Row C show examples where the model fails almost completely. It is expected behavior since the person in the input images has a hard torso twist and arms bent so that they occlude nearly half of the stomach and chest area.
Application of Default Clothes to the Custom Person Images
Let’s review the experiments of the model application to the unconstrained images of people in natural environments. The VITON dataset used for the model training has very static lighting conditions and not many variants of camera perspectives and poses.
When using real images for testing the model, we realized that the difference between the training data and unconstrained data significantly diminishes the quality of the model’s output. The example of this issue you can see in Fig. 11.
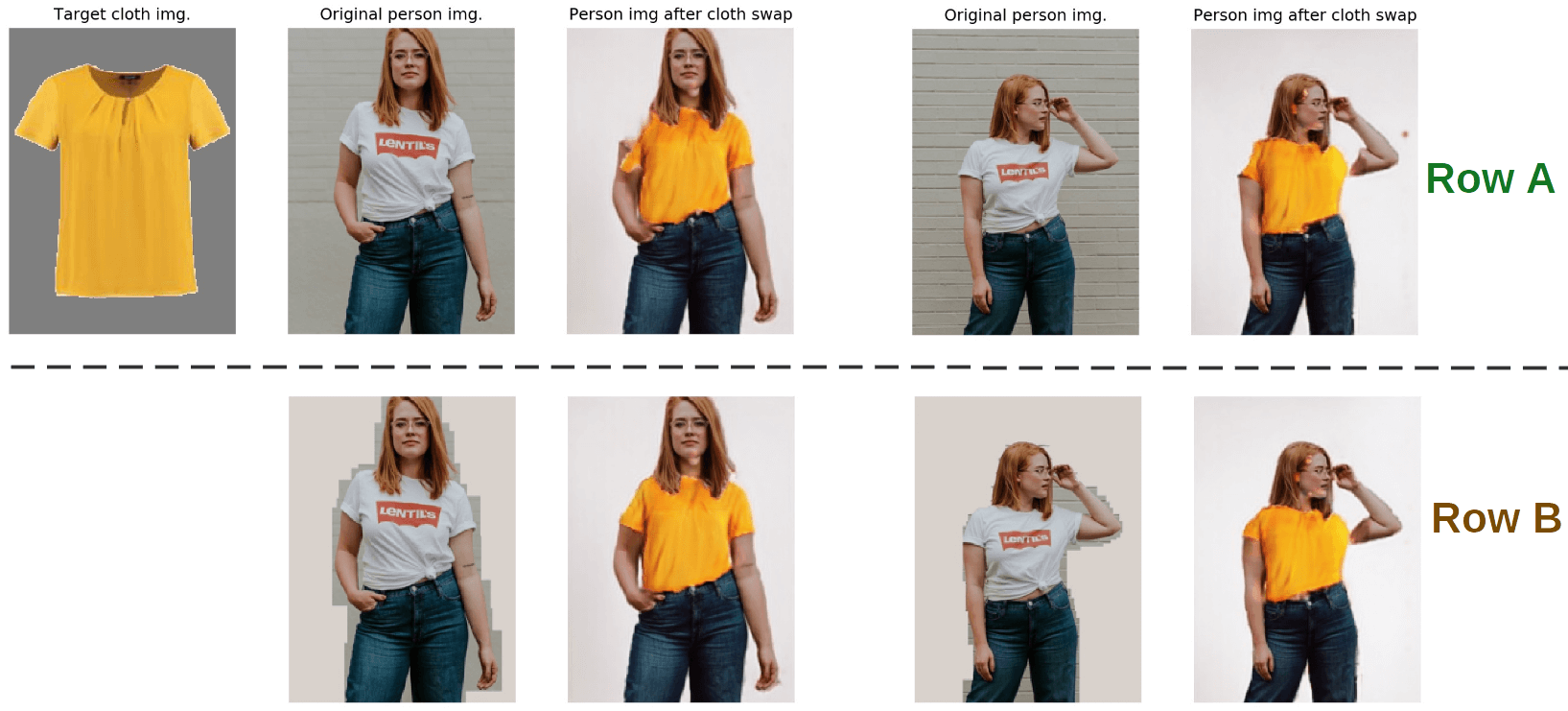
Figure 11: Clothing replacement - the impact of background dissimilarity with the training data. Row A - original background, row B - background replaced with a background similar to the one in VITON dataset.
We found images of a person who had a similar pose and camera perspective to the training dataset images and saw numerous artifacts present after processing (Row A). However, after removing the unusual background texture and filling the area with the same background color as in the training dataset, the received output quality was improved (although some artifacts were still present).
When testing the model using more images, we discovered that the model performed semi-decently on the images similar to the ones from the training distribution and failed completely where the input was distinct enough. You can see the more successful attempts of applying the model and the typical issues we found in Fig 12.

Figure 12: Outputs of clothing replacement on images with an unconstrained environment (Row A -minor artifacts, Row B- moderate artifacts, Row C - major artifacts).
The images in Row A show the examples of places where the main defects are edge defects.
The images in Row B show more critical cases of masking errors. For example, cloth blurring, holes, and skin/clothing patches in those places where they should not be present.
The images in Row C show severe inpainting errors like poorly drawn arms and masking errors, like the unmasked part of the body.
Application of Custom Clothes to the Custom Person Images
Here we tested how well the model can handle both custom clothing and custom person photos and divided results into three groups again.

Figure 13: Clothing replacement with an unconstrained environment and custom clothing images.
The images in Row A display the best result we could obtain from the model. The combination of custom clothes and custom person images proved to be too difficult for processing without at least moderate artifacts.
The images in Row B display results where the artifacts became more abundant.
The images in Row C display the most severely distorted results due to the transformation errors.
Future Plans
ACGPN model has its limitations, such as the training data must contain paired images of target clothes and people wearing those specific clothes.
Considering everything described above, there might be an impression that a virtual try on clothes is non-implementable, but it’s not. Being a challengeable task now, it is also providing a window of opportunity for AI-based innovations in the future. And there are already new approaches designed to solve those issues. Another important thing is to take the technology capabilities into account when choosing a proper use case scenario.
Related: