A Deep Dive into GPT Models: Evolution & Performance Comparison
The blog focuses on GPT models, providing an in-depth understanding and analysis. It explains the three main components of GPT models: generative, pre-trained, and transformers.
By Ankit, Bhaskar & Malhar
Over the past few years, there has been remarkable progress in the field of Natural Language Processing, thanks to the emergence of large language models. Language models are used in machine translation systems to learn how to map strings from one language to another. Among the family of language models, the Generative Pre-trained Transformer (GPT) based Model has garnered the most attention in recent times. Initially, the language models were rule-based systems that heavily relied on human input to function. However, the evolution of deep learning techniques has positively impacted the complexity, scale and accuracy of the tasks handled by these models.
In our previous blog, we provided a comprehensive explanation of the various aspects of the GPT3 model, evaluated features offered by Open AI’s GPT-3 API and also explored the model’s usage and limitations. In this blog, we will shift our focus to the GPT Model and its foundational components. We will also look at evolution - starting from GPT-1 to the recently introduced GPT-4 and dive into the key improvements done in each generation that made the models potent over time.
1. Understanding GPT Models
GPT (Generative Pre-trained Transformers) is a deep learning-based Large Language Model (LLM), utilizing a decoder-only architecture built on transformers. Its purpose is to process text data and generate text output that resembles human language.
As the name suggests, there are three pillars of the model namely:
- Generative
- Pre-trained
- Transformers
Let's explore the model through these components:
Generative: This feature emphasizes the model's ability to generate text by comprehending and responding to a given text sample. Prior to GPT models, text output was generated by rearranging or extracting words from the input itself. The generative capability of GPT models gave them an edge over existing models, enabling the production of more coherent and human-like text.
This generative capability is derived from the modeling objective used during training.
GPT models are trained using autoregressive language modeling, where the models are fed with an input sequence of words, and the model tries to find the most suitable next word by employing probability distributions to predict the most probable word or phrase.
Pre-Trained: "Pre-trained" refers to an ML model that has undergone training on a large dataset of examples before being deployed for a specific task. In the case of GPT, the model is trained on an extensive corpus of text data using an unsupervised learning approach. This allows the model to learn patterns and relationships within the data without explicit guidance.
In simpler terms, training the model with vast amounts of data in an unsupervised manner helps it understand the general features and structure of a language. Once learned, the model can leverage this understanding for specific tasks such as question answering and summarization.
Transformers: A type of neural network architecture that is designed to handle text sequences of varying lengths. The concept of transformers gained prominence after the groundbreaking paper titled "Attention Is All You Need" was published in 2017.
GPT uses decoder-only architecture.The primary component of a transformer is its "self-attention mechanism," which enables the model to capture the relationship between each word and other words within the same sentence.
Example:
- A dog is sitting on the bank of the River Ganga.
- I’ll withdraw some money from the bank.
Self-attention evaluates each word in relation to other words in the sentence. In the first example when “bank” is evaluated in the context of “River”, the model learns that it refers to a river bank. Similarly, in the second example, evaluating "bank" with respect to the word "money" suggests a financial bank.
2. Evolution of GPT Models
Now, let's take a closer look at the various versions of GPT Models, with a focus on the enhancements and additions introduced in each subsequent model.
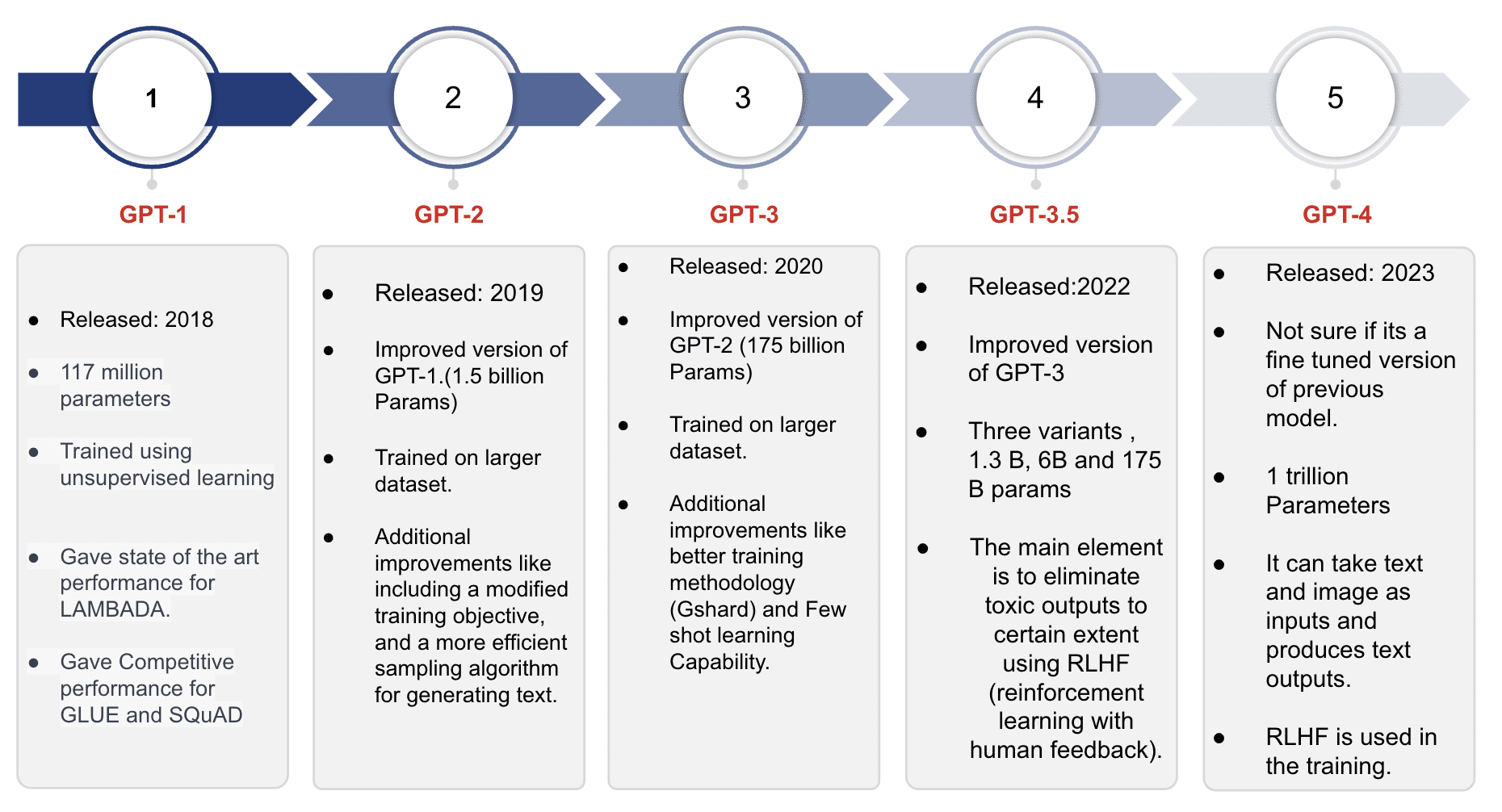
*Slide 3 in GPT Models
GPT-1
It is the first model of the GPT series and was trained on around 40GB of text data. The model achieved state-of-the-art results for modeling tasks like LAMBADA and demonstrated competitive performance for tasks like GLUE and SQuAD. With a maximum context length of 512 tokens (around 380 words), the model could retain information for relatively short sentences or documents per request. The model's impressive text generation capabilities and strong performance on standard tasks provided the impetus for the development of the subsequent model in the series.
GPT-2
Derived from the GPT-1 Model, the GPT-2 Model retains the same architectural features. However, it undergoes training on an even larger corpus of text data compared to GPT-1. Notably, GPT-2 can accommodate double the input size, enabling it to process more extensive text samples. With nearly 1.5 billion parameters, GPT-2 exhibits a significant boost in capacity and potential for language modeling.
Here are some major improvements in GPT-2 over GPT 1:
- Modified Objective Training is a technique utilized during the pre-training phase to enhance language models. Traditionally, models predict the next word in the sequence solely based on previous words, leading to potentially incoherent or irrelevant predictions. MO training addresses this limitation by incorporating additional context, such as Parts of Speech (Noun, Verb, etc.) and Subject-Object Identification. By leveraging this supplementary information, the model generates outputs that are more coherent and informative.
- Layer normalization is another technique employed to improve training and performance. It involves normalizing the activations of each layer within the neural network, rather than normalizing the network's inputs or outputs as a whole. This normalization mitigates the issue of Internal Covariate Shift, which refers to the change in the distribution of network activations caused by alterations in network parameters.
- GPT 2 is also powered by superior sampling algorithms as compared to GPT 1. Key improvements include:
- Top - p sampling: Only tokens with cumulative probability mass exceeding a certain threshold are considered during sampling. This avoids sampling from low-probability tokens, resulting in more diverse and coherent text generation.
- Temperature scaling of the logits (i.e., the raw output of the neural network before Softmax), controls the level of randomness in the generated text. Lower temperatures yield more conservative and predictable text, while higher temperatures produce more creative and unexpected text.
- Unconditional sampling (random sampling) option, which allows users to explore the model's generative capabilities and can produce ingenious results.
GPT-3
| Training Data source | Training Data Size |
| Common Crawl, BookCorpus, Wikipedia, Books, Articles, and more | over 570 GB of text data |
The GPT-3 Model is an evolution of the GPT-2 Model, surpassing it in several aspects. It was trained on a significantly larger corpus of text data and featured a maximum of 175 billion parameters.
Along with its increased size, GPT-3 introduced several noteworthy improvements:
- GShard (Giant-Sharded model parallelism): allows the model to be split across multiple accelerators. This facilitates parallel training and inference, particularly for large language models with billions of parameters.
- Zero-shot learning capabilities facilitates GPT-3 to exhibit the ability to perform tasks for which it hadn't been explicitly trained. This means it could generate text in response to novel prompts by leveraging its general understanding of language and the given task.
- Few-shot learning capabilities powers GPT-3 to quickly adapt to new tasks and domains with minimal training. It demonstrates an impressive ability to learn from a small number of examples.
- Multilingual support: GPT-3 is proficient in generating text in ~30 languages, including English, Chinese, French, German, and Arabic. This broad multilingual support makes it a highly versatile language model for diverse applications.
- Improved sampling: GPT-3 uses an improved sampling algorithm that includes the ability to adjust the randomness in generated text, similar to GPT-2. Additionally, it introduces the option of "prompted" sampling, enabling text generation based on user-specified prompts or context.
GPT-3.5
| Training Data source | Training Data Size |
| Common Crawl, BookCorpus, Wikipedia, Books, Articles, and more | > 570 GB |
Similar to its predecessors, the GPT-3.5 series models were derived from the GPT-3 models. However, the distinguishing feature of GPT-3.5 models lies in their adherence to specific policies based on human values, incorporated using a technique called Reinforcement Learning with Human Feedback (RLHF). The primary objective was to align the models more closely with the user's intentions, mitigate toxicity, and prioritize truthfulness in their generated output. This evolution signifies a conscious effort to enhance the ethical and responsible usage of language models in order to provide a safer and more reliable user experience.
Improvements over GPT-3:
OpenAI used Reinforcement Learning from human feedback to fine-tune GPT-3 and enable it to follow a broad set of instructions. The RLHF technique entails training the model using reinforcement learning principles, wherein the model receives rewards or penalties based on the quality and alignment of its generated outputs with human evaluators. By integrating this feedback into the training process, the model gains the ability to learn from errors and enhance its performance, ultimately producing text outputs that are more natural and captivating.
GPT 4
GPT-4 represents the latest model in the GPT series introducing multimodal capabilities that allow it to process both text and image inputs while generating text outputs. It accommodates various image formats, including documents with text, photographs, diagrams, graphs, schematics, and screenshots.
While OpenAI has not disclosed technical details such as model size, architecture, training methodology, or model weights for GPT-4, some estimates suggest that it comprises nearly 1 trillion parameters. The base model of GPT-4 follows a training objective similar to previous GPT models, aiming to predict the next word given a sequence of words. The training process involved using a huge corpus of publicly available internet data and licensed data.
GPT-4 has showcased superior performance compared to GPT-3.5 in OpenAI's internal adversarial factuality evaluations and public benchmarks like TruthfulQA. The RLHF techniques utilized in GPT-3.5 were also incorporated into GPT-4. OpenAI actively seeks to enhance GPT-4 based on feedback received from ChatGPT and other sources.
Performance Comparison of GPT Models for Standard Modeling Tasks
Scores of GPT-1,GPT-2 and GPT-3 in standard NLP Modeling tasks LAMBDA, GLUE and SQuAD.
| Model | GLUE | LAMBADA | SQuAD F1 | SQuAD Exact Match |
| GPT-1 | 68.4 | 48.4 | 82.0 | 74.6 |
| GPT-2 | 84.6 | 60.1 | 89.5 | 83.0 |
| GPT-3 | 93.2 | 69.6 | 92.4 | 88.8 |
| GPT-3.5 | 93.5 | 79.3 | 92.4 | 88.8 |
| GPT-4 | 94.2 | 82.4 | 93.6 | 90.4 |
All numbers are in Percentages. || source - BARD
This table demonstrates the consistent improvement in results, which can be attributed to the aforementioned enhancements.
GPT-3.5 and GPT-4 are tested on the newer benchmarks tests and standard examinations.
The newer GPT models, (3.5 and 4) are tested on the tasks that require reasoning and domain knowledge. The models have been tested on numerous examinations which are known to be challenging. One such examination for which GPT-3 (ada, babbage, curie, davinci), GPT-3.5 , ChatGPT and GPT-4 are compared is the MBE Exam. From the graph we can see continuous improvement in score, with GPT-4 even beating the average student score.
Figure 1 illustrates the comparison of percentage of marks obtained in MBE* by different GPT models:
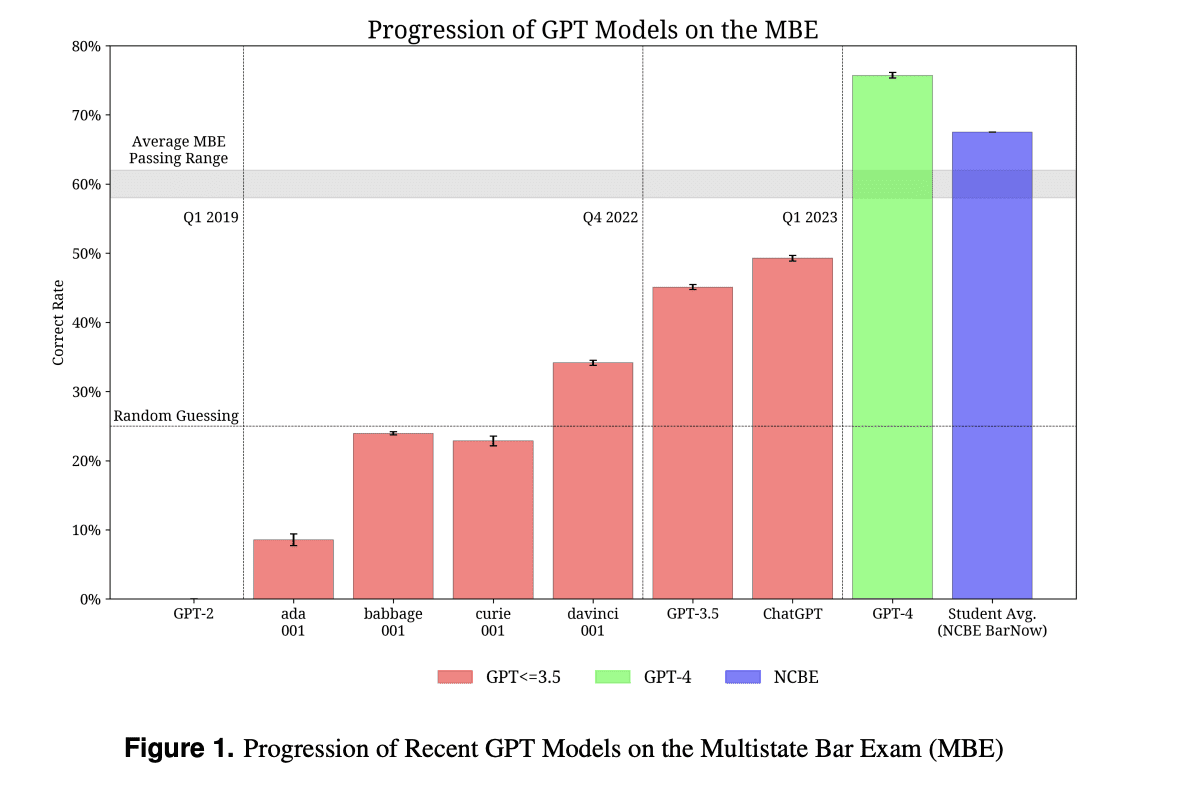
*The Multistate Bar Exam (MBE) is a challenging battery of tests designed to evaluate an applicant’s legal knowledge and skills, and is a precondition to practice law in the US.
The below graphs also highlights the progress of the models and again beating the average students scores for different streams of legal subject areas.
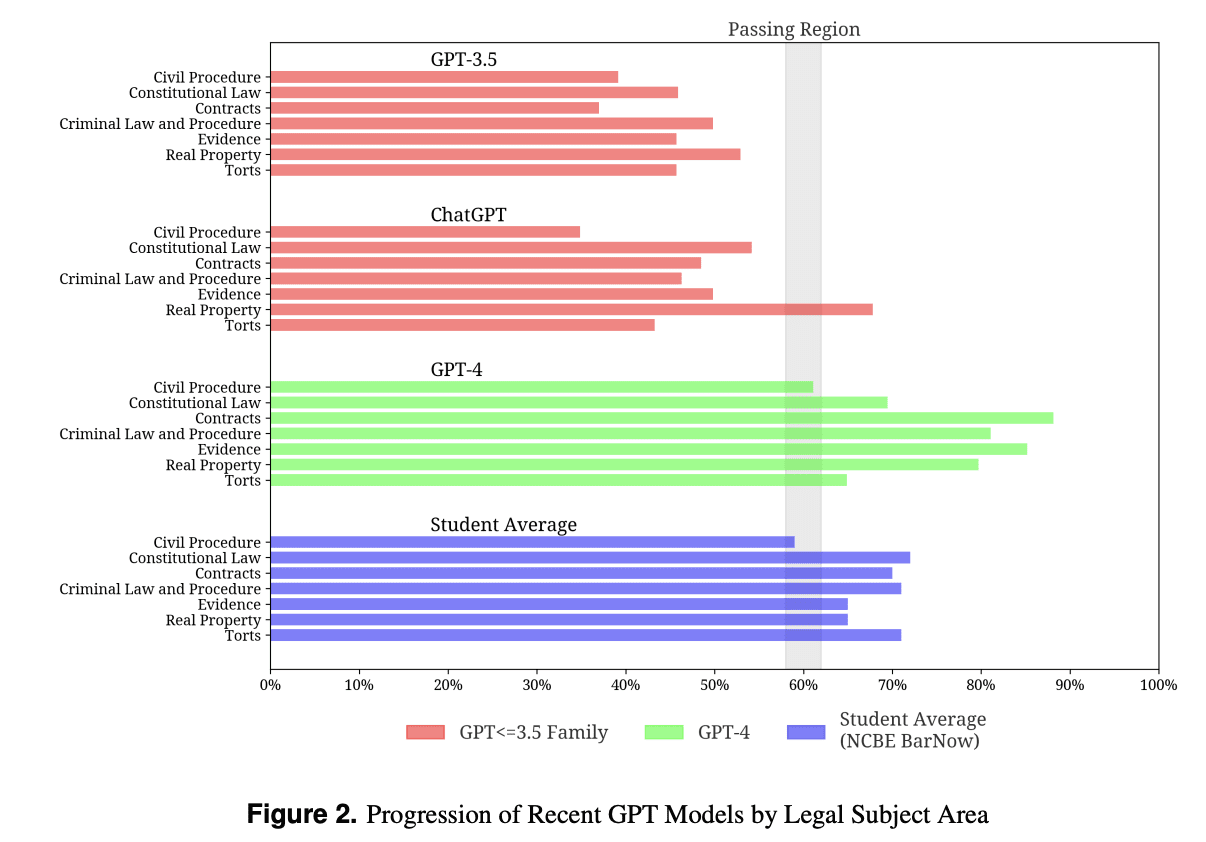
Source: Data Science Association
Conclusion
With the rise of Transformer-based Large Language Models (LLMs), the field of natural language processing is undergoing rapid evolution. Among the various language models built on this architecture, the GPT models have emerged exceptional in terms of output and performance. OpenAI, the organization behind GPT, has consistently enhanced the model on multiple fronts since the release of the first model.
Over the course of five years, the size of the model has scaled significantly, expanding approximately 8,500 times from GPT-1 to GPT-4. This remarkable progress can be attributed to continuous enhancements in areas such as training data size, data quality, data sources, training techniques, and the number of parameters. These factors have played a pivotal role in enabling the models to deliver outstanding performance across a wide range of tasks.
- Ankit Mehra is a Senior Data Scientist at Sigmoid. He specializes in analytics and ML-based data solutions.
- Malhar Yadav is an Associate Data Scientist at Sigmoid and a coding and ML enthusiast.
- Bhaskar Ammu is a Senior Lead Data Scientist at Sigmoid. He specializes in designing data science solutions for clients, building database architectures, and managing projects and teams.