Data Warehouses vs. Data Lakes vs. Data Marts: Need Help Deciding?
A comparative overview of data warehouses, data lakes, and data marts to help you make informed decisions on data storage solutions for your data architecture.
Image by Author
To make the most out of data, organizations need efficient and scalable solutions that can store, process, and analyze data effectively. From ingesting data from multiple sources through transformation and serving, data storage underpins the data architecture.
So choosing the right data storage solution while factoring in how you’ll access the data and the specific use case is important. In this article, we’ll explore three popular data storage abstractions: data warehouses, data lakes, and data marts.
We’ll go over the basics and compare these data storage abstractions across features like access patterns, schema, data governance, use cases, and more.
Let’s get started!
Data Warehouses
Data warehouses are foundational components of modern data management systems, designed to facilitate efficient storage, organization, and retrieval of structured data for analytical purposes.
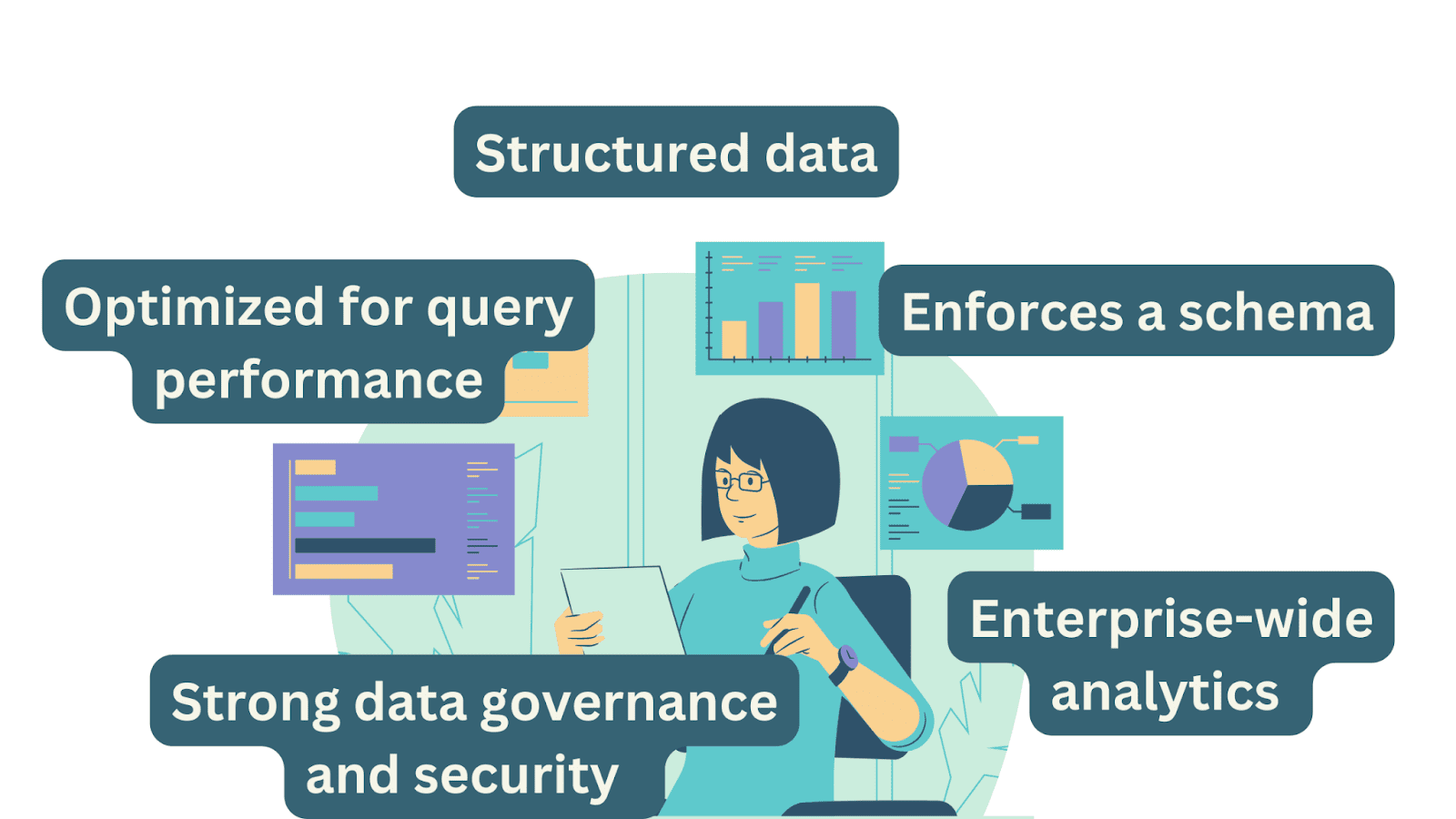
Image by Author
What Is a Data Warehouse?
A data warehouse is a specialized database that centralizes, stores, and manages structured and processed data from various sources for the primary purpose of supporting complex analytics and reporting.
The data warehouse is, therefore, a centralized repository for structured data, allowing organizations to:
- Perform complex data analysis
- Generate reports and dashboards
- Support business intelligence (BI) and decision-making processes
- Gain insights into historical and current data trends
Data Type, Access Patterns, and Benefits
Data warehouses primarily store structured data, which is data organized into well-defined tables with rows and columns. This structured format simplifies data retrieval and analysis, making it suitable for reporting and querying.
Data warehouses are optimized for query performance and reporting. They often use indexing and caching mechanisms to accelerate data retrieval, ensuring that analysts and business users can quickly access the information they need.
Data Integration
Data warehouses centralize the integration of data from various source systems. This involves extracting data from source systems, transforming it into a consistent format, and loading it into the warehouse.
ETL processes are commonly employed for data integration in data warehouses. These pipelines extract data from source systems, apply transformations to clean and structure the data, and then load it into the warehouse's database tables. ETL processes ensure data quality and consistency within the data warehouse.
Schema
Data warehouses enforce a schema for data consistency. A schema defines the structure of the data, including the tables, columns, data types, and relationships. This enforced schema ensures that data remains consistent and can be relied upon for analysis.
Data warehouses often use a star or snowflake schema to organize data. In a star schema, a central fact table contains transactional data, surrounded by dimension tables that provide context and attributes. In a snowflake schema, dimension tables are normalized to reduce redundancy. The choice between these schemas depends on the specific data warehousing requirements.
Data Governance and Security
Data warehouses are known for their strong governance and security controls. They are designed for structured data and provide features like data validation, data quality checks, access controls, and auditing capabilities.
Use Cases and Business Units
Data warehouses are primarily used for enterprise-wide analytics and reporting. They consolidate data from various sources into a single repository, making it accessible for analysis and reporting across the entire organization. They support standardized reporting and ad-hoc querying for decision-makers.
Data Lakes
Data lakes represent a flexible and scalable approach to data storage and management, catering to the diverse needs of modern organizations.
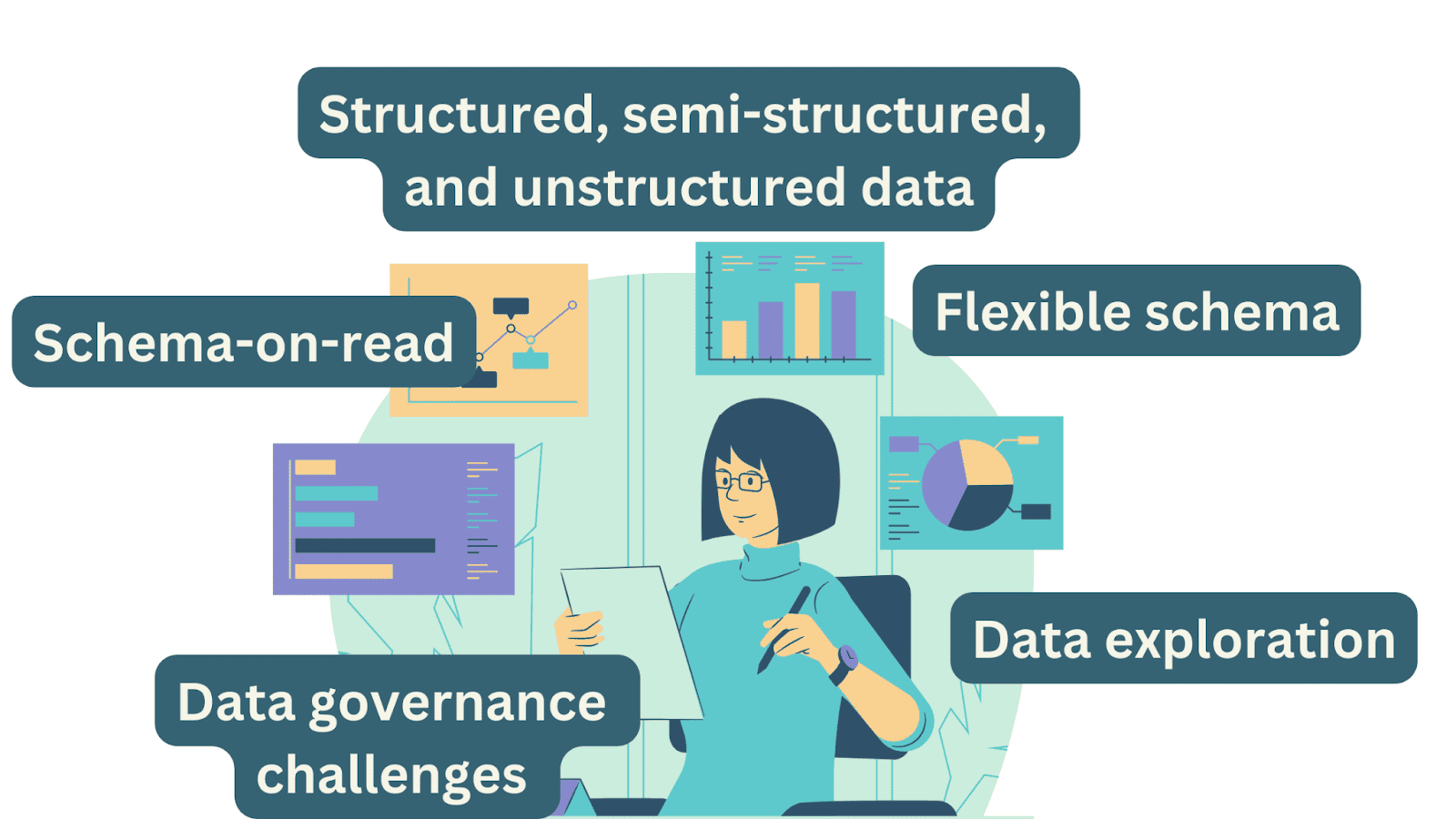
Image by Author
What Is a Data Lake?
A data lake is a centralized repository that stores large volumes of raw, structured, semi-structured, and unstructured data, allowing organizations to store and manage vast amounts of information without the constraints of a predefined schema.
The primary purpose of a data lake is to provide a flexible and cost-effective solution for storing and managing diverse data types:
- Data lakes retain data in its raw and native form.
- Data lakes facilitate a wide range of use cases, from traditional analytics to advanced machine learning and AI applications.
- Users can explore and analyze data without predefining its structure or schema.
Data lakes are designed to address the challenges posed by the increasing volume, velocity, and variety of data generated by organizations today.
Data Type, Access Patterns, and Benefits
Data lakes are capable of storing a diverse array of data types, including structured data from relational databases, semi-structured data such as JSON, XML, and unstructured data like text documents, images, and videos. This makes data lakes suitable for handling data in its raw and native form.
Data Integration
Ingesting data into a data lake can be through both batch or real-time data ingestion. Batch processes involve periodically loading large volumes of data, while real-time ingestion enables the continuous flow of data from various sources. This flexibility ensures that data lakes can handle various data velocity requirements.
Data lakes have a schema-on-read approach. Unlike data warehouses, data in a data lake does not have a predefined schema. Instead, the schema is defined at the time of analysis, allowing users to interpret and structure the data based on their specific needs. This schema flexibility is a hallmark feature of data lakes.
Schema
Data lakes offer schema flexibility, allowing data to be ingested without a predefined schema. This flexibility accommodates changes in data structure over time and empowers users to define the schema as needed for their analysis.
Data in a data lake is given structure and meaning at the time of analysis. This approach means that users can interpret and structure the data to suit their analytical requirements.
Data Governance and Security
Data lakes often face governance challenges because they store both structured and unstructured data in their raw form. It can be difficult to manage metadata, enforce data quality, and maintain a unified data catalog, which can lead to issues related to data discovery and compliance.
Use Cases and Business Units
Data lakes are ideal for data exploration and experimentation. They can store vast amounts of raw, unstructured data, making them suitable for data professionals to explore and experiment without predefined schemas.
Data Marts
Data marts are subsets of the enterprise data warehouse catering to specific business units or functions within an organization.
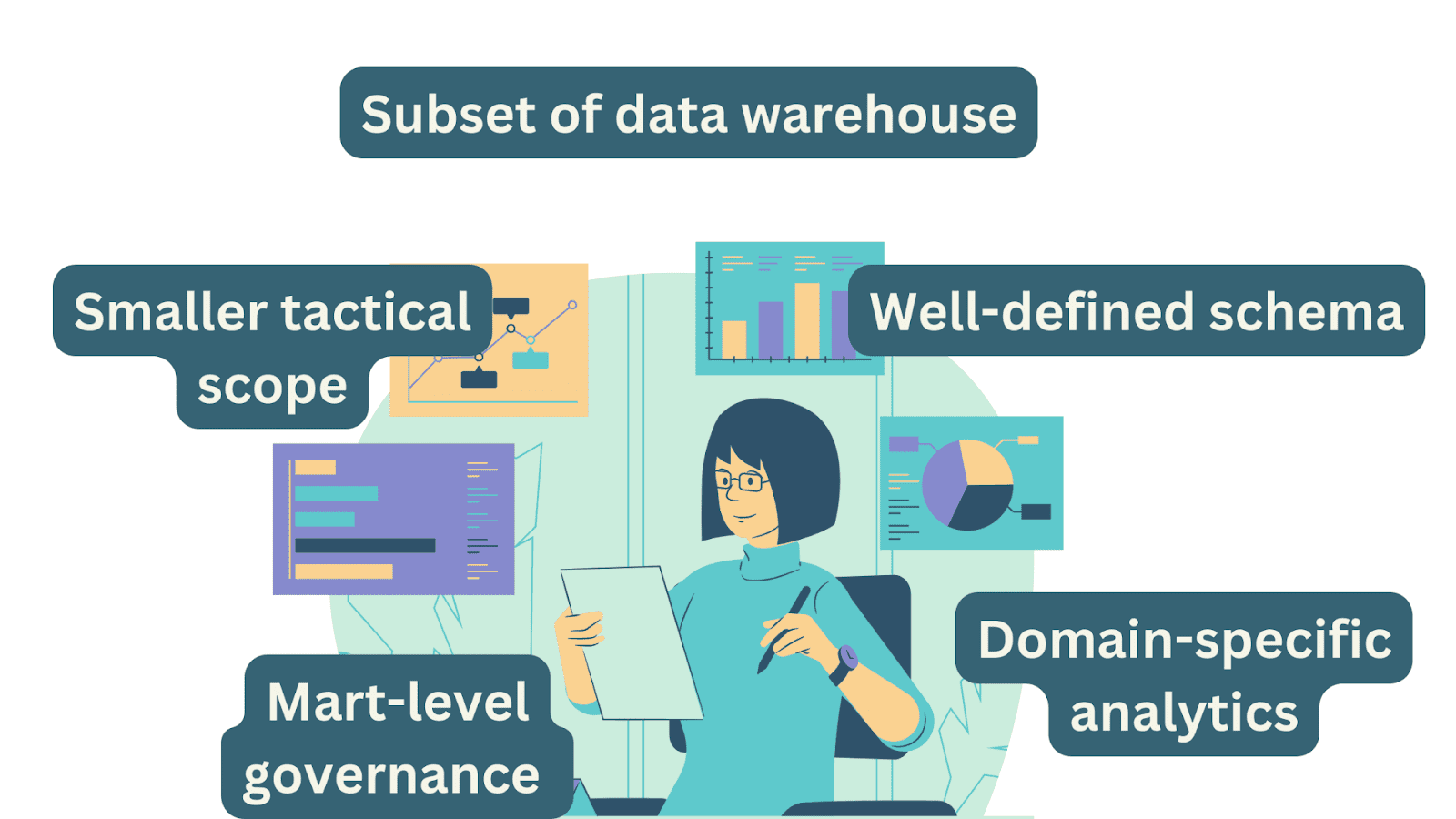
Image by Author
What Is a Data Mart?
A data mart is a specialized subset of a data warehouse or data lake that stores structured data tailored to the needs of a specific business unit, department, or functional area within an organization.
The primary purpose of a data mart is to provide focused and efficient access to data for specific analytical and reporting needs. Key objectives include:
- Supporting specific business units: Data marts are designed to cater to the requirements of individual business units, such as sales, marketing, finance, or operations.
- Simplifying data access: By providing easier access to the relevant data, data marts make it easier for users within a specific domain to access and analyze the information they need.
- Faster time to insights: Data marts can improve query and reporting performance by reducing the volume of data that needs to be processed.
Data marts are, therefore, instrumental in ensuring that relevant data is readily available to decision-makers within various parts of the organization.
Data Types, Access Patterns, and Benefits
Data marts primarily store structured data that is pertinent to the specific business unit or function they serve. This structured format ensures data consistency and relevance to the domain's analytical needs.
Data marts provide a more focused and easier access to data compared to enterprise data warehouses or data lakes. This focused approach enables users to quickly access and analyze data that is directly relevant to their domain.
Data Integration
Data marts typically extract data from central repositories, such as data warehouses. This extraction process involves identifying and selecting data relevant to the specific business unit or function.
Once extracted, data undergoes transformation specific to the mart's needs. This may include data cleansing, aggregation, or customization to ensure that the data aligns with the analytical requirements of the domain it serves.
Schema
Data marts may either adhere to the schema defined in the central data warehouse or employ a custom schema tailored to the specific mart's analytical needs. The choice depends on factors such as data consistency and the mart's autonomy.
Data Governance and Security
Data marts are typically subsets of data warehouses, focusing on specific business domains or units. Governance efforts are concentrated at the mart level, ensuring that the data used by specific business units is compliant with enterprise-wide governance standards set by the data warehouse.
Use Cases and Business Units
Data marts are tailored to the specific needs of business units or domains within an organization. They provide a subset of data from the data warehouse that is relevant to a particular business area. This allows business units to perform specialized analytics and reporting without the complexity of handling the entire enterprise dataset.
Data Warehouses vs. Data Lakes vs. Data Marts: A Comprehensive Comparison
Let’s sum up the key differences between data warehouses, data lakes, and data marts:
| Feature | Data Warehouses | Data Lakes | Data Marts |
| Data Types and Flexibility | Structured data, fixed schema | Various data types, schema flexibility | Structured data, well-defined schema |
| Data Integration | ETL pipelines | Flexible data ingestion, schema-on-read | Extraction and transformation for domains |
| Query Performance | Optimized for queries | Performance varies | Optimal performance |
| Data Governance | Strong data governance and security controls | Data governance challenges | Mart-level governance |
| Use Cases | Enterprise analytics | Exploration of large volumes of data | Domain-specific analytics |
Conclusion
I hope you’ve gained an overview of data warehouses, lakes, and marts. The choice of architecture depends on the organization's specific requirements and the balance between governance and flexibility needed for their data and business needs:
- Data warehouses—with strong governance and security controls—are suitable for enterprise-wide analytics and reporting.
- Data lakes are suitable for data exploration and big data analytics. But can pose governance and security challenges.
- Data marts offer domain-specific analytics aligned with business unit needs while complying with the governance standards of the data warehouse.
You can also explore data lakehouses, a relatively recent and evolving architecture. Data lakehouses aim to bridge the gap between data warehouses and data lakes, offering a unified approach to data storage and analytics.
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more. Bala also creates engaging resource overviews and coding tutorials.