 Data Scientists and ML Engineers Are Luxury Employees
Data Scientists and ML Engineers Are Luxury Employees

 Data Scientists and ML Engineers Are Luxury Employees
Data Scientists and ML Engineers Are Luxury EmployeesMaybe it seems that everyone wants to become a data scientist and every organization wants to hire one as quickly as possible. However, a mismatch often exists between what companies tend to need and what ML practitioners want to do. So, it's time for the field to take another step toward maturity through an enhanced appreciation of the broad range of technical foundations for an organization to become data-driven.
By Adrien Biarnes, Senior Machine Learning Engineer at Dailymotion.

Some background context
I started my career in 2010 after a master's in computer science. During my studies, I got hooked on software engineering. It can be really fascinating! You get to build stuff out of nothing. You start from a virtual blank sheet, and you can end up with an empire. But I think what really hooked me the most is this sense of personal growth that I got day after day as my craft improved.
Anyway, after 7 years, I didn’t always feel that I was learning new things on a daily basis. I was still learning but clearly not like I used to. More often than not, I was given tasks for which I knew upfront I would not learn anything (think CRUD-like applications). That’s when I decided to learn machine learning. I went back to school for a full-time master's in one of the best French engineering schools. Since then, I have been employed both as a data scientist and a machine learning engineer, and this is what I learned…
Machine Learning sits at the top of the software chain
A lot of the people who might read this probably already know the pyramid of data needs brilliantly illustrated by Monica Rogati:
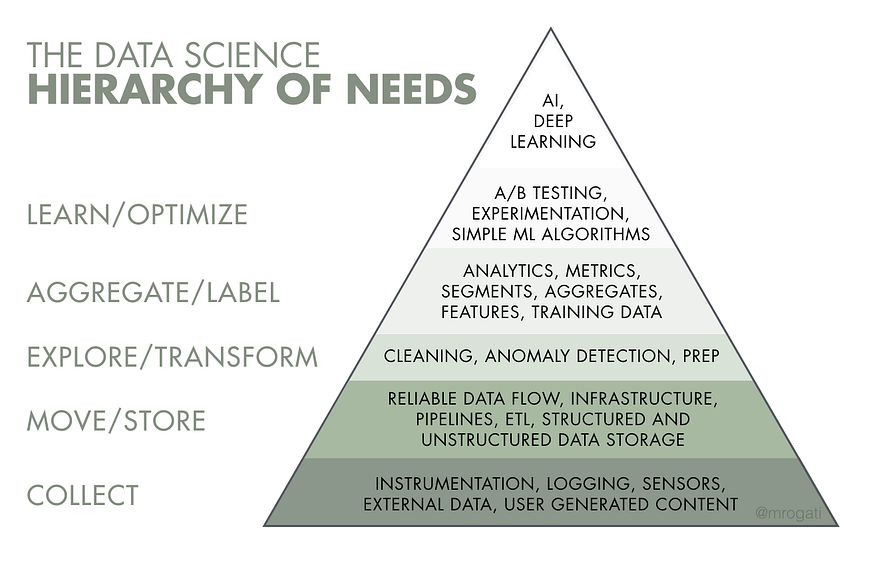
Image by Monica Rogati.
There have been numerous variants of this pyramid, but to me, the most important message is the fact that AI/Machine learning sits at the top. So if you want to do machine learning, you need solid foundations. You need robust data pipelines that collect, transform and load the data. You need to clean it and store it in well-organized and documented locations. Then you need tools to query this (big) data efficiently. You also need a solid infrastructure to run your algorithms. You also need pipelines for frequent repeated training and inference. You need orchestrators. You need to keep track of your past experiments and the datasets used at the time. I will stop there because the objective is not to draw up a complete list but to show that there is a huge amount of technical prerequisites.
In the same vein, an important source of information is Google’s paper on the hidden technical debt of machine learning systems. It basically shows that ML models are a tiny part of the overall system and that more attention and love should be given to other non ML parts.

Figure 1 of Google’s paper shows that only a tiny fraction of the system is ML code.
So there you have it. The models are a tiny part of the system. But wait? What is the specialization of data scientists and ML engineers? What is it that ML practitioners crave when they look for a job? Well, working on that tiny piece of the system. It is the most important thing we care about!
We all want to practice machine learning
If you think about it, it makes perfect sense and for numerous reasons.
First, machine learning and data science are fascinating fields. Mostly because they sit at the crossroad of computer science, mathematics, and business understanding. This means that there is way more room for personal growth. When switching from software engineering to machine learning engineering, my backyard suddenly tripled in size. I could continue to craft beautiful and complex systems with my hands (and become the great engineer I wanted to be) and at the same time satisfy (way more) my intellectual curiosity. Now every day, I get to learn and sit on the shoulder of giants!
Apart from the interest in the field, another main reason is a bit more practical. I have spent so much time and energy learning the necessary topics (think probability, statistics, calculus, linear algebra, distributed computing, machine learning, deep learning…) that I want this knowledge to stick in. And we are all humans. Even if you are a genius, if you don’t practice what you learn, the knowledge goes away. So when your boss asks you (for the tenth time in a row) to create a piece of software or an analysis that has nothing to do with machine learning, what is that you think? Are you happy?
Another important factor is that the field is moving at lightning speed. It was already the case when I was in software engineering, but now it is not even comparable. Not a day goes by without hearing from the latest breakthrough, the newest shiny deep learning architecture, this great new book that every ML practitioner should read, etc. When you are not practicing ML in your day job, you are left with practicing it during your free time. It is OK for a little while, but it is not sustainable in the long run. We are all humans. We need time off to relax and be with our loved ones. Don’t get me wrong. I love learning new things. It can be by completing a MOOC, reading a research paper, a blog post, or a book. But I just can’t spend all of my free time doing so.
Then there are all the other reasons like you can make good money, you can make a big impact in your company, AI is the future, yada yada…
Hacking your way into machine learning
So you manage to succeed in that last interview. You are now officially a data scientist. You are presented with a new project with a concrete business goal. Awesome! So what is it that you do? Well, you find a website where you can extract the data that is needed. You quickly hack a python script on the side to scrap it all and dump it into a dataframe. You open a Jupyter notebook, start massaging and plotting the data to understand it. You run a few experiments and produce a nice model using your favorite technique and framework. Finally, you dump your model into a pickle file and put it in production. In the end, this is what you get:
A hacked model in production — Image by author.
Congratulations, you are now the father of a nice heavyweight complex machine built on stilts. Now, pray that the wind won’t blow too hard, especially when you’ll want to add this last feature the product guys asked for. This is what I call hacking your way into machine learning. You wanted to build that shiny new model so hard that you just forgot or pretend to ignore the prerequisites!
As I said previously, ML sits at the top of the pyramid. Talking about a pyramid means that the foundations, to be solid, are also pretty large! Generally, there is way more effort to put in the bottom layers compared to the cherry of the latest SOTA model that you put on the top.
All companies want to claim they are doing AI
I also want to take the time to explain this phenomenon that will better illustrate the point of this article. I know this for a fact because I have experienced it myself.
When I started my journey into data science, I landed a data scientist internship in a consulting firm. I was quickly tasked with some basic stuff like cleaning the data and producing simple charts in R. Given what the team was doing, I quickly understood that I would have a hard time applying all the fancy techniques I learned during my master's degree. So after I complained about it, I was given the task to understand and describe the relationship between client consumptions and the prices they paid. Basically, I was to model the price elasticity of demand. Don’t get me wrong, I enjoyed every last moment of it. I was now able to apply my statistical lessons to a real-world business problem. So overall, it was a great task for a beginner in data science like me. But I went way too far for this task. I basically tried every model I could think of (even deep learning) just to practice. Overall do you think that this task justified that they needed a data scientist intern? Does that even exist? What was really needed here is someone who can perform a linear regression. That’s it. Pretty much any analyst can do that.
After that, I landed a job as a data scientist/ML engineer in a startup. For this one experience, I was extremely lucky. Even if the company has limited resources, they have a strong culture of innovation, and I was given a lot of freedom to experiment. So overall, I managed to tackle real-world and challenging machine learning tasks. But in the end, even if I have a strong culture of managing the technical debt, I was so eager to practice machine learning that the foundations of my final solution were not sufficiently robust, and I had troubles later down the road.
Finally, after that experience, I have had a quick passage in another startup where, once again, I was struck by false promises. This company is a great place, but they clearly have been hit by young data scientists who all hacked their way up the machine learning ladder. My first task was to analyze a legacy data pipeline and come up with recommendations to revamp it. This data pipeline was basically feeding all of their smart algorithms, and it was in a very, very bad shape, to say the least. I had huge trouble just understanding what it was doing. So not only was this task a pure data engineering task, it was also not very exciting.
All in all, this also makes perfect sense. Companies are in desperate need to attract talented and educated workers. Recruiting data scientists is sexy. It makes the company look good. You can claim to the world that you are leveraging the power of AI. It is also much easier to attract funds (especially for startups).
In the end, I am still grateful for this journey because it made me realize the discrepancies between what is advertised by most companies and the state of matters. I am now way more capable of predicting the odds that a company is doing and in need of real machine learning systems.
There is a huge mismatch between what most companies need and what ML practitioners want to do
Finally, I want to explain what I meant in the title. This is the direct corollary of what I just explained. Most of the time, even if a company has a real concrete advantage in becoming data-driven, it does not need machine learning or at least not fancy complicated machine learning. If you are in charge of recruiting that next employee, then ask yourself:
- Do I have the necessary resources to study my data and produce analysis to support my decisions? If not, bring in some more analysts or maybe statisticians.
- Do I have solid technical foundations to acquire, store, refresh, modify, document, query the data that I need? If not, bring in some data engineers.
- Do I have the technical infrastructure and tools in place to support data scientists and ML engineers? If not, bring in some software engineers (back end, front end, full-stack), DevOps, etc.
My profound belief is that, in the end, there is not that much need for ML resources. In fact, it is pretty obvious when you look at the data pyramid of needs. The corollary of this fact is that data scientists and ML engineers are luxury employees. Not many companies can nor should afford them. This is the sad reality.
As a final note, I want to say, like everything in life, it is not all black or white but mostly gray. So yes, you can always afford yourself a data scientist even if you are a small startup because you don’t have the fund to recruit a multi-disciplinary team, and you want to attract external funds. After all, data scientists are a jack of all trades! They sit at the crossroad of the 3 disciplines in the Venn diagram. Sure you can. But just be aware that when doing so, you have a high chance of ending up with:
- a product with a high technical debt which will probably fail in the long run (because it’s too hard and expensive to take care of).
- an employee who will be disappointed pretty quickly if you are not able to bring in some new specialized players into the game.
Original. Reposted with permission.
Related: