The Data Science Puzzle, Explained
The puzzle of data science is examined through the relationship between several key concepts in the data science realm. As we will see, far from being concrete concepts etched in stone, divergent opinions are inevitable; this is but another opinion to consider.
There is no dearth of articles around the web comparing and contrasting data science terminology. There are all sorts of articles written by all types of people relaying their opinions to anyone who will listen. It's almost overwhelming.
So let me set the record straight, for those wondering if this is one of those types of posts. Yes. Yes it is.
Why another one? I think that, while there may be an awful lot of opinion pieces defining and comparing these related terms, the fact is that much of this terminology is fluid, is not entirely agreed-upon, and, frankly, being exposed to other peoples' views is one of the best ways to test and refine your own.
So, while one may not agree entirely (or even minimally) with my opinion on much of this terminology, there may still be something one can get out of this. Several concepts central to data science will be examined. Or, at least, central in my opinion. I will do my best to put forth how they relate to one another and how they fit together as individual pieces of a larger puzzle.
As an example of somewhat divergent opinions, and prior to considering any of the concepts individually, KDnuggets' Gregory Piatetsky-Shapiro has put together the following Venn diagram which outlines the relationship between the very same data science terminology we will be considering herein. The reader is encouraged to compare this Venn diagram with Drew Conway's now famous data science Venn diagram, as well as my own discussion below and modified process/relationship diagram near the bottom of the post. I think that, while differences exist, the concepts line up with some degree of similarity (see the previous few paragraphs).
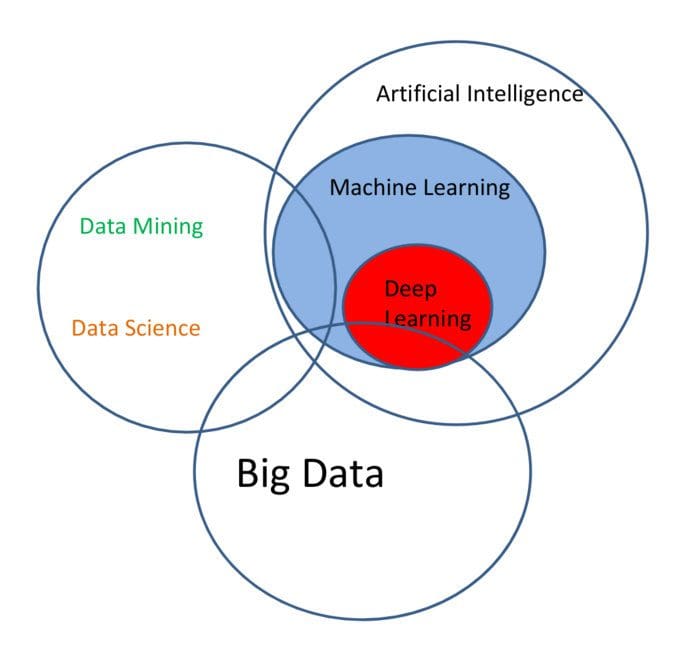
We will now give treatment to the same 6 selected core concepts as depicted in the above Venn diagram, and provide some insight as to how they fit together into a data science puzzle. First, we quickly dispense with one of the biggest buzz terms of the past decade.
Big Data
There are all sorts of articles available defining big data, and I won't spend much time on this concept here. I will simply state that big data could very generally be defined as datasets of a size "beyond the ability of commonly used software tools to capture, manage, and process." Big data is a moving target; this definition is both vague and accurate enough to capture its central characteristic.

As for the remaining concepts we will investigate, it's good to gain some initial understanding of their search term popularities and N-gram frequencies, in order to help separate the hard fact from the hype. Given that a pair of these concepts are relatively new, the N-gram frequencies for our 'older' concepts from 1980 to 2008 are shown above.
The more recent Google Trends show the rise of 2 new terms, the continued upward trend of 2 others, and the gradual, but noticeable, decline of the last. Note that big data was not included in the above graphics due to it already being quantitatively analyzed to death. Read on for further insights into the observations.
Machine Learning
According to Tom Mitchell in his seminal book on the subject, machine learning is "concerned with the question of how to construct computer programs that automatically improve with experience." Machine learning is interdisciplinary in nature, and employs techniques from the fields of computer science, statistics, and artificial intelligence, among others. The main artifacts of machine learning research are algorithms which facilitate this automatic improvement from experience, algorithms which can be applied in a variety of diverse fields.
I don't think there is anyone who would doubt that machine learning is a central aspect of data science. I give the term data science detailed treatment below, but if you consider that at a very high level its goal is to extract insight from data, machine learning is the engine which allows this process to be automated. Machine learning has a lot in common with classical statistics, in that it uses samples to infer and make generalizations. Where statistics has more of a focus on the descriptive (though it can, by extrapolation, be predictive), machine learning has very little concern with the descriptive, and employs it only as an intermediate step in order to be able to make predictions. Machine learning is often thought to be synonymous with pattern recognition; while that really won't get much disagreement from me, I believe that the term pattern recognition implies a much less sophisticated and more simplistic set of processes than machine learning actually is, which is why I tend to shy away from it.
Machine learning has a complex relationship with data mining.