Data Labeling for Machine Learning: Market Overview, Approaches, and Tools
So much of data science and machine learning is founded on having clean and well-understood data sources that it is unsurprising that the data labeling market is growing faster than ever. Here, we highlight many of the top players in this industry and the techniques they use to help you consider which might make a good partner for your needs.
By Frederik Bussler, tech journalist focused on AI.

The data labeling market is growing faster than ever. Last year, its segment for 3rd party solutions reached over $1 billion and is expected to continue its steady climb over the next 5 years exceeding $7 billion by 2027. With growth at an impressive 25-30% per annum, some sources, including Grand View Research, estimate the market to be worth as much as $8.2 billion by 2028.
Background
Data labeling as a field emerged in the wake of ML research, beginning with basic algorithms and gradually making its way to the virtual assistants and self-driving vehicles we’re so in love with today. From Alan Turing’s seminal paper on AI from 1950 and Arthur Samuel’s 1959 paper with the first computer learning algorithm to the unveiling of IBM’s Deep Blue in 1996 and Google Brain in 2011 — ML has come a long way.
Nowadays, data labeling is an integral part of ML and AI development. Without labeled data, we can’t run ML algorithms. That’s why finding effective ways to label data quickly and cheaply has been on everyone’s mind. The better the solution, the faster AI can progress — it’s as simple as that.
Categories of Software Solutions
Sophisticated software is available for annotating production-grade training data. However, it’s not always easy to make the right choice. A variety of solutions have evolved — they can be categorized by format, availability, and approach.
The first two categories are pretty straightforward. Format refers to what type of data can be labeled, such as text, image, audio, or video.
Availability refers to how accessible and affordable a solution is. This depends on whether the software is proprietary (usually requiring payment) or open-source (and therefore free). Among proprietary solutions, some offer a free trial, and some do not.
The approach to labeling is a much more complex category, so let’s break it down.
Data Labeling Approaches
When it comes to data labeling approaches — arguably the most important category from the perspective of business — a wide range of solutions exists today. According to an article published by KDNuggets, the most common are the following:
- Internal labeling
This is considered to be the most reliable approach in terms of accuracy of labeled data, but it’s also one of the most expensive and time-consuming tracks to take. In this scenario, companies assign data labeling tasks to their own in-house teams. Teams may already be task-proficient, or they may require some training. Full control is maintained at every stage of the labeling process.
- Outsourcing to individuals
Another option is to put together a team of external labelers, most of whom are freelancers. They can be found on specialized websites like UpWork, as well as social media sites, namely LinkedIn, Facebook, and Twitter. First, the company needs to build a consistent workflow that includes these specialists. Then, the company needs to coordinate their roles, agree on software of choice, and write up clear instructions.
- Outsourcing to specialized companies
This is similar to the approach above, except that in this case interested businesses hire one entity in lieu of numerous labelers. As a result, this method is also more expensive in comparison, but purportedly less time-consuming and more dependable accuracy-wise. Which software tools and methodologies these specialized teams use varies from one team to the next — and they don’t always reveal their cards.
- Synthetic labeling
In this approach, faux training data is generated that resembles real data in terms of core parameters. These data can be generated relatively quickly and used for labeling accordingly. Within synthetic labeling, three sub-models exist: Generative Adversarial Networks (GANs), AutoRegressive models (ARs), and Variational Autoencoders (VAEs). All three carry practical applications, from detecting fraud in finance to producing healthcare datasets in medicine. However, these models require a great deal of computing power to run that’s often not available to every IT department.
- Data programming
This fully automated approach entails running code with labeling functions that allows the machines to do all of the work. While it’s admittedly less accurate than most other methods, data programming is the least labor-intensive of all approaches on the list. The noisy datasets that it generates can still be used for weak supervision models, or they can be cleaned up for other purposes, such as discriminative training.
- Crowdsourcing
Considered to be the fastest and most cost-effective method, crowdsourcing platforms make use of their vast pools of users to divide tasks into smaller, more digestible portions. These microtasks are completed and verified by multiple contributors — who often work in small groups — and subsequently aggregated and reassembled to produce end results. Data labeling accuracy remains this method’s primary ongoing concern.
7 Questions to Ask Yourself
When choosing the right software, you need to be well informed of the pros and cons of each one in order to minimize any chances of commercially damaging hiccups. You can start by asking these basic questions:
Is it expensive? What is the price-to-quality ratio?
Is it time-effective?
Does it come with inbuilt mechanisms for quality control?
Is there a steep learning curve for the user?
Does it provide comprehensive instructions for beginners?
Are all data types supported?
Does it require a lot of computational power?
Overview of Data Labeling Tools
There are currently over ten different data labeling tools and platforms available. Let’s take a look.
Company: Appen
Website: https://appen.com
Overview:
Appen offers solutions to businesses for their product data management. The company collects and tags data to build and improve in-house artificial intelligence systems. The industries Appen covers include financial services, retail, healthcare, and government. Appen is said to employ 1 million data annotators in 170 countries.
| Type of Data: | Most, including text, image, audio, and video |
| Availability: | Proprietary (trial plan available) |
| Approach: | Crowdsourcing (sub-categories: on demand, remote, secure, and on-site workers) on ADAP platform + platform for hire services (client’s own specialists) |
| Industries served: | Technology, Automotive, Financial Services, Healthcare, Government, and Retail |
| Price-to-quality ratio: | Above average |
| Time-effectiveness: | High |
| Instructions for beginners: | Yes (set of tutorials) |
| Learning curve for the user: | Average to Fast (depending on sub-category) |
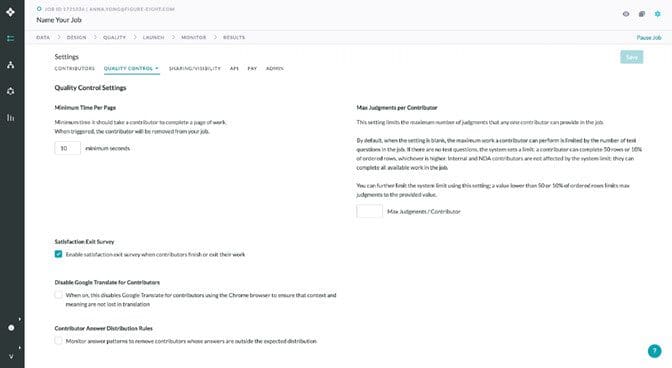
| Mechanisms for quality control: | Quality Control Settings: Minimum Time per Page, Maximum Judgments per Contributor, Disable Google Translate for Contributors and Answer Distribution Rules.
Source: Appen website |
| Computational power: | None needed for the client unless on-site work is required |
Company: Lionbridge AI
Website: https://lionbridge.ai/
Overview:
Lionbridge, based in Massachusetts, offers services in data collection, annotation, and validation, including text, audio, video, image, and geo. Its strongest suit is reportedly linguistics. The company prides itself on delivering quality human-labeled data. It’s involved in several industries, including automotive, medical, and e-commerce. (Acquired by Canada-based TELUS Corporation)
| Type of Data: | Most, including text, image, audio, video and geo-local data |
| Availability: | Proprietary |
| Approach: | Crowdsourcing and outsourcing (for highly specialized tasks) / own platform with a vast pool of in-house and outsourced/crowdsourced workers |
| Industries served: | Technology, Communications & Media, Fintech & Financial Services, Travel & Hospitality, Games, eCommerce, and Healthcare |
| Price-to-quality ratio: | Average to good (task and approach dependent) |
| Time-effectiveness: | Medium to High (task and approach dependent) |
| Instructions for beginners: | Yes (posts and walk-throughs) |
| Learning curve for the user: | Average to Fast (approach dependent) |
| Mechanisms for quality control: | Built-in validation, spot-checking and a workers seniority system to ensure the highest quality data. |
| Computational power: | None needed for the client in most cases |
Company: Scale
Website: https://scale.com/
Overview:
Based out of Silicon Valley, Scale is a go-to company that promises to provide high-quality data-labeling services from annotating and evaluating (including scalable, comprehensive and advanced solutions) to generating synthetic datasets. Scale is involved in robotics, speech, and language, autonomous vehicles, e-commerce, and document processing, to name a few.
| Type of Data: | 3D sensor fusion, text, image, video, mapping |
| Availability: | Proprietary (free trial available) |
| Approach: | “The data platform for AI.” A combination of tools and human review. |
| Industries served: | Technology, Retail, Government, Robotics, eCommerce |
| Price-to-quality ratio: | Average |
| Time-effectiveness: | Medium to High |
| Instructions for beginners: | Yes (guides and quickstarts) |
| Learning curve for the user: | Average |
| Mechanisms for quality control: | All tasks receive additional layers of both human and ML-driven checks. Quality assurance systems monitor and prevent errors, and varying levels of human review and consensus are provided according to customer requirements.
Source: Scale website |
| Computational power: | None is needed for the client unless specific custom-made solutions requested |

Company: Toloka
Website: https://toloka.ai/
Overview:
The company was launched in 2014 and has since risen to serve 2,000 businesses. Toloka has several million registered users in over 100 countries (known as “Tolokers”) — 200,000 of which are active monthly — completing on-demand data labeling tasks. Trained ML algorithms are subsequently utilized for developing self-driving vehicles, NLP, chatbots and voice assistants, as well as e-commerce. Toloka is also actively involved in AI research. The team regularly shares its results at the top ML/AI/DS conferences and workshops around the globe.
| Type of Data: | Most, including text, image, audio, and video |
| Availability: | Proprietary |
| Approach: | Crowdsourcing |
| Industries served: | eCommerce, Retail, Automotive, Cybersecurity, Banking, Sports. Legal Tech, Research, Manufacturing, Healthcare. |
| Price-to-quality ratio: | Above average |
| Time-effectiveness: | High |
| Instructions for beginners: | Yes (Knowledge base) |
| Learning curve for the user: | Average to Fast |
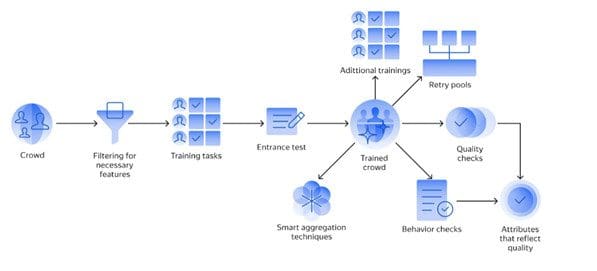
| Mechanisms for quality control: | Selecting performers: pre-filtering, training, entrance testing. Synchronous quality control: behavior checks (CAPTCHA, speed monitoring, checking for certain actions), assignment quality checks (majority vote, control tasks). Asynchronous quality control: assignment review, smart aggregation methods.
Source: Toloka website |
| Computational power: | None needed for the client |
Company: MTurk (Amazon Mechanical Turk)
Website: https://www.mturk.com/
Overview:
MTurk is one of the biggest and most well-known crowdsourcing platforms today. After being launched in 2005, the company has expanded rapidly, thanks in part to the global recognition of the Amazon brand. With a vast pool of contributors (known as “Turkers”), of which 100,000 are available at any given time, the company harbors clients from all over the globe and focuses on HITs (Human Intelligence Tasks).
| Type of Data: | Most |
| Availability: | Proprietary |
| Approach: | Crowdsourcing |
| Industries served: | Most industries |
| Price-to-quality ratio: | Above average |
| Time-effectiveness: | High |
| Instructions for beginners: | Yes (tutorials and support) |
| Learning curve for the user: | Average to Fast |
| Mechanisms for quality control: | Qualifications allow you to select or create specific Worker eligibility requirements for your projects. MTurk offers three types of pre-defined Qualifications — Masters, System, and Premium Qualifications. |
| Computational power: | None needed for the client |
Company: Hive
Website: https://thehive.ai/
Overview:
Another Silicon Valley-based company, Hive was launched in 2013 and has two main business paradigms: Hive Models (turnkey AI solutions for pre-trained Deep Learning models) and Hive Data (in-house data annotation solutions for sourcing and labeling ML models). For the latter, the company is said to have over 2 million contributors working on its platform. This year, the company raised an additional $85 million in funding.
| Type of Data: | Many, including text, image, audio, video, 3D point cloud |
| Availability: | Proprietary |
| Approach: | Crowdsourcing and outsourcing + on-demand data generation |
| Industries served: | Technology, Automotive, Manufacturing, Hospitality, Retail, eCommerce |
| Price-to-quality ratio: | Average to Good |
| Time-effectiveness: | Medium to High (task-dependent) |
| Instructions for beginners: | Yes (+ support from assigned project managers) |
| Learning curve for the user: | Fast |
| Mechanisms for quality control: | Integrated manual labeling. Real-time edge case validation, additional enrichment as needed. Testing projects by small data samples. |
| Computational power: | None needed for the client in most cases |
Company: Webtunix AI
Website: https://www.webtunix.com/
Overview:
Based out of NYC, Webtunix, founded by Indian entrepreneurs, is a Big Data consulting company that helps businesses meet their AI needs. This includes various data labeling services in Human and Computer Vision, audio, NLP, and semantic segmentation, as well as video and line annotations. The company was launched in 2015.
| Type of Data: | Most, including text, image, and video |
| Availability: | Proprietary |
| Approach: | Specific software tools for specific tasks with a human-in-the-loop approach (custom technology-based outsourcing and data programming) |
| Industries served: | Agriculture, Automobile, eCommerce, Cybersecurity, Healthcare, Banking, Sports |
| Price-to-quality ratio: | Average |
| Time-effectiveness: | Medium to High |
| Instructions for beginners: | Yes (24/7 support) |
| Learning curve for the user: | Fast (comprehensive guides) |
| Mechanisms for quality control: | Qualified human assessors and curators, machine-assisted. |
| Computational power: | None needed for the client in most cases |
Company: iMerit
Website: https://imerit.net/
Overview:
iMerit was launched in 2012. The company combines MAA and human-made annotations to streamline business processes and deliver labeled data to corporate clients. The company is involved mainly in Computer Vision and NLP and relies on its own team of trained experts. With over 4,000 employees, iMerit is SOC 2 compliant and has another data protection certification — ISO 27001:2013. As far as data labeling goes, the company’s own annotation tools, clients’ tools, or third-party tools are all on the menu.
| Type of Data: | Text, image, audio, video, geospatial |
| Availability: | Proprietary (free quote with sample dataset) |
| Approach: | Multi-tiered approach: assessment followed by outsourcing, crowdsourcing, or data programming tacks |
| Industries served: | Transportation, Geospatial, Medical, eCommerce, Agriculture, Government |
| Price-to-quality ratio: | Average to Above average (task and approach dependent) |
| Time-effectiveness: | Average to High |
| Instructions for beginners: | Yes (comprehensive customer support available) |
| Learning curve for the user: | Average to Fast (task and approach dependent) |
| Mechanisms for quality control: | 
Source: iMerit website |
| Computational power: | None needed for the client in most cases |
Company: CloudFactory
Website: https://www.cloudfactory.com/
Overview:
Based out of Reading, England, CloudFactory announced its presence on the market in 2010 and has since been offering its outsourcing and crowdsourcing data-labeling services to global clients. The company specializes in Computer Vision, NLP, and data entry and enrichment. Referring to its delivery pipelines as “virtual assembly lines,” CloudFactory provides work for around 1 million people in developing countries, “raising them up as leaders to address poverty in their own communities.”
| Type of Data: | Primarily text, image, video, and audio |
| Availability: | Proprietary (free demo) |
| Approach: | Crowdsourcing and Outsourcing (workforce management platform), turnkey or platform for hire/workforce extension |
| Industries served: | Retail, Transportation, Entertainment, Education, Fitness, Agriculture, Manufacturing |
| Price-to-quality ratio: | Average to Above average (approach dependent) |
| Time-effectiveness: | Medium to High (approach dependent) |
| Instructions for beginners: | Yes (blog, webinars, resource library) |
| Learning curve for the user: | Fast |
| Mechanisms for quality control: | Highlighted in The Outsourcers' Guide to Quality on the company’s website.
Image source: CloudFactory website |
| Computational power: | Not required for the client in most cases |

Company: Clickworker
Website: https://www.clickworker.com/
Overview:
Founded in 2008, Clickworker, based in Germany, is a crowdsourcing platform that specializes in Computer Vision and NLP. With close to 3 million contributor (“Clickworkers”) spread throughout 136 countries, the company claims to have completed over 1 million data labeling projects to date. The company also has a specialized Clickworker app for smartphones and tablets.
| Type of Data: | Most, including text, image, audio, and video |
| Availability: | Proprietary (free trial available) |
| Approach: | Crowdsourcing (managed service, self-service, API) |
| Industries Served: | eCommerce, Retail, Research, and Big Data |
| Price-to-quality ratio: | Above average |
| Time-effectiveness: | High |
| Instructions for beginners: | Yes (set of tutorials) |
| Learning curve for the user: | Fast |
| Mechanisms for quality control: | Special quality assurance procedures, such as statistical process testing, audits, and peer review. Clickworkers are selected according to training and testing results as well as past performance.
Source: Clickworker website |
| Computational power: | None needed for the client in most cases |

The Bottom Line
The quality of labeled data remains a major hurdle in data labeling. This hurdle becomes painfully pertinent when building complex ML models, particularly when multiple models are running in parallel. Numerous annotation tools are readily available. With this in mind, the foremost challenge for data scientists today is matching the task to the software — working out in what situations certain tools have advantages over others. This translates into a simple question: how can a data labeling job be completed with the least amount of effort, time, and cost, while at the same time delivering the highest possible results?
Approaches that rely on exclusively human-dependent tactics are slowly being sidelined, as scientists have evolved data labeling methods that combine manual and computational components. Further development, refinement, and advancement of these new, cutting-edge instruments is bound to set the pace in the years to come, as more IT companies will likely follow this trajectory.
Related: