
Data Ingestion with Pandas: A Beginner Tutorial
Learn tricks on importing various data formats using Pandas with a few lines of code. We will be learning to import SQL databases, Excel sheets, HTML tables, CSV, and JSON files with examples.

Image by author
Pandas is easy to use, open-source data analysis tool which is widely used by data analytics, data engineering, data science, and machine learning engineers. It comes with powerful functions such as data cleaning & manipulations, supporting popular data formats, and data visualization using matplotlib. Most data science students only learn to import CSV, but at work, you have to deal with multiple data formats, and things can get complicated if you are doing it for the first time. In this guide, we will be focusing on importing CSV, Excel, SQL, HTML, and JSON datasets.
SQL
For running SQL queries, we need to download SQLite database for Kaggle Mental Health in the Tech Industry under the License CC BY-SA 4.0. The database contains three tables; Questions, Answer, and Survey.
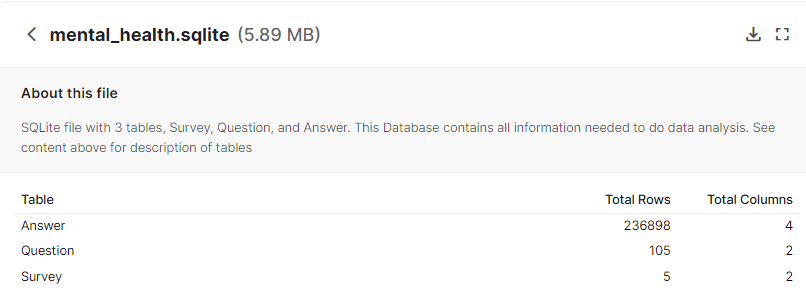
SQL Schema | Kaggle
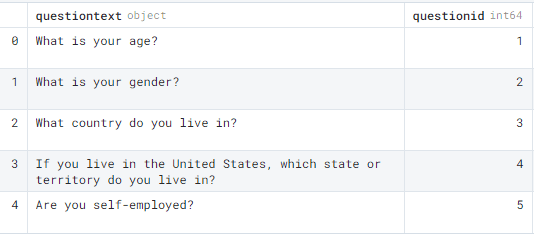
To import data from any SQL server, we need to create a connection (SQLAlchemy connectable / sqlite3), write SQL query, and use Pandas’s read_sql_query() function to convert output to dataframe. In our case, we will first connect mental_health.sqlite by using sqlite3 package and then pass the object into the read_sql_query() function. The last step is to write a query to import all columns from the Question table. If you are new to SQL, I will suggest you learn the basics by taking a free course: Learn SQL | Codecademy.
import pandas as pd
import sqlite3
# Prepare a connection object
# Pass the Database name as a parameter
conn = sqlite3.connect("mental_health.sqlite")
# Use read_sql_query method
# Pass SELECT query and connection object as parameter
pdSql = pd.read_sql_query("SELECT * FROM Question", conn)
# display top 5 rows
pdSql.head()
We have successfully converted SQL query into Pandas dataframe. It’s that easy.
HTML
Web scraping is a complicated and time-consuming job in the tech world. You will be using Beautiful Soup, Selenium, and Scrapy to extract and clean your HTML data. Using Pandas read_html(), you can skip all the steps and directly import table data from the website into a dataframe. It’s that easy. In our case, we will be scraping the COVID-19 Vaccination Tracker website to extract tables containing COVID19 vaccination data.
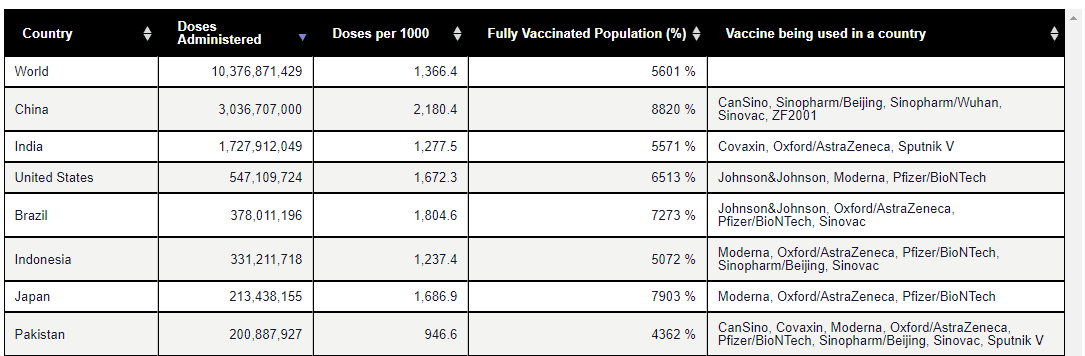
COVID19 Vaccination Data | Pharmaceutical Technology
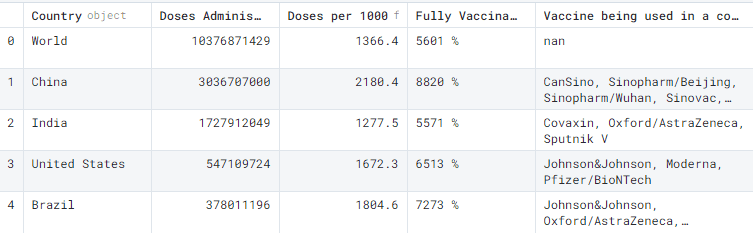
Just by using pd.read_html() we were able to extract the data from the website.
df_html = pd.read_html( "https://www.pharmaceutical-technology.com/covid-19-vaccination-tracker/" )[0] df_html.head()
Our initial output was list and to convert list into a dataframe we have use [0] at the end. This will only display the first value in the list.
Note: You need to experiment with your initial result to get the perfect result.
CSV
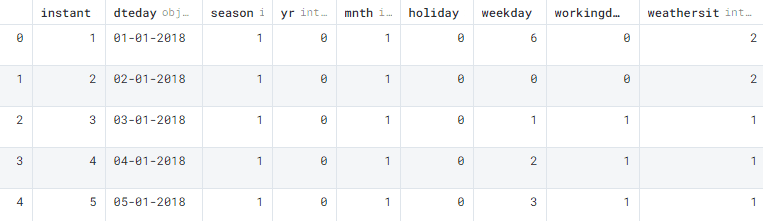
CSV is the most common file format in data science. It is simple and can be accessed by multiple Python packages. The first thing you will learn in a data science course is to import a CSV file. In our case, we are using Kaggle’s Bike Sharing Dataset under CC0: Public Domain license. The values in CSV are separated by commas as shown below.

Image by author
We will use the read_csv() function to import the dataset into Pandas dataframe. This function is quite powerful as we can parse dates, remove missing values and do a lot of data cleaning with just one line of code.
data_csv = pd.read_csv("day.csv")
data_csv.head()
We have successfully loaded the CSV file and displayed the first five rows.
Excel
Excel sheets are still popular among data and business analytics professionals. In our case we will be converting the U.S. Presidents and Debt dataset by kevinnayar under CC BY 2.0 license into .xlsx format by using Microsoft Excel. Our Excel file contains two sheets but Pandas dataframe is a flat table, we will use sheet_name to import selected sheets into Pandas dataframe.
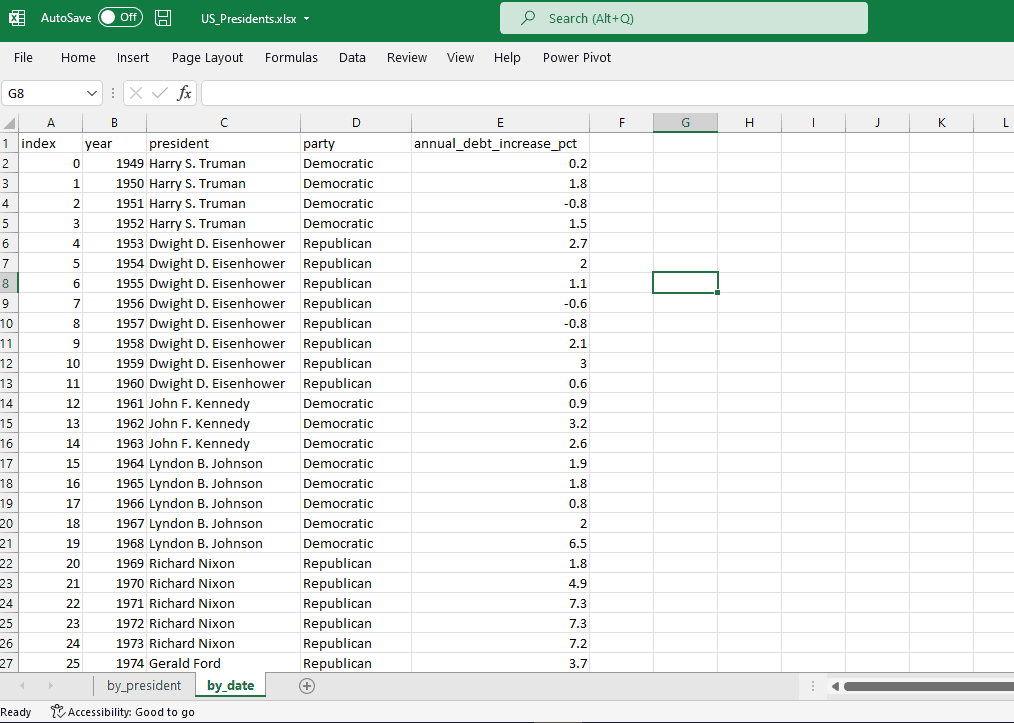
Image by author
We will be using read_excel() to import our dataset:
- The first parameter is file path.
- The second is sheet_name: in our case we are importing the second sheet. The sheet numbers start from 0.
- Third is index_col: as our dataset contains index columns, to avoid duplication, we will provide index_col=<column_name>.
data_excel = pd.read_excel("US_Presidents.xlsx",sheet_name = 1, index_col = "index")
data_excel.head()

JSON
Reading JSON files is quite tricky as there are multiple formats that you need to understand. Sometimes, Pandas fails to import nested JSON files so we need to perform manual steps to import the file perfectly. JSON is the most common file format for the tech industry. It is preferred by web developers to data engineers. In our case, we are going to download the Spotify Recommendation dataset under CC0: Public Domain license. The dataset contains good songs and bad songs JSON files. For this example, we will only use the good.json file. As we can observe, we are dealing with a nested dataset.
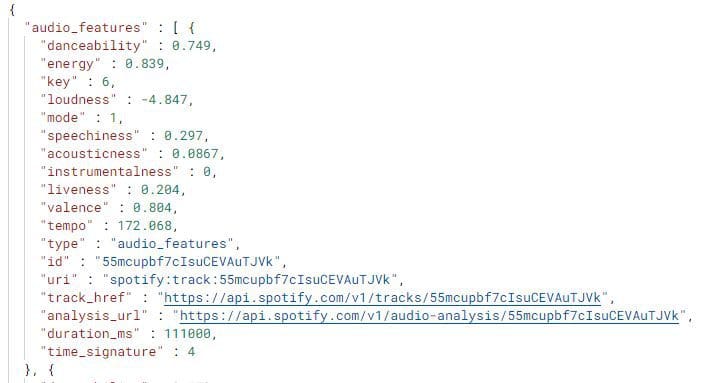
Image by author
Before doing any data processing let’s import the dataset without parameters by using the read_json() function.
df_json = pd.read_json("good.json")
df_json.head()
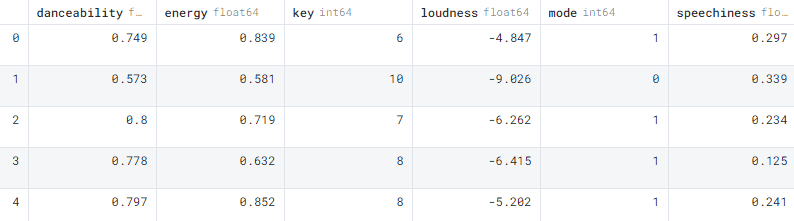
As we can observe, the dataframe contains only one column, and it's all over the place. To debug this issue, we need to import the raw dataset and then parse it.

First, we will be importing raw JSON files using the json package and only selecting the audio_features subset. Finally, we will convert the JSON to Pandas dataframe by using the json_normalize() function.
It’s a success and we have finally parsed the JSON into a dataframe. If you are dealing with a multi-layer nested JSON file, try to import the raw data and then process the data so that the final output is a flat table.
import json
with open('good.json') as data_file:
data = json.load(data_file)
df = pd.json_normalize(data["audio_features"])
df.head()
The code and all datasets are available at Deepnote.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in Technology Management and a bachelor's degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.