Convert Text Documents to a TF-IDF Matrix with tfidfvectorizer
Convert text documents to vectors using TF-IDF vectorizer for topic extraction, clustering, and classification.

Image by Author
TF-IDF Matrix
Term frequency Inverse document frequency (TFIDF) is a statistical formula to convert text documents into vectors based on the relevancy of the word. It is based on the bag of the words model to create a matrix containing the information about less relevant and most relevant words in the document.
TF-IDF is particularly useful in NLP tasks, topic modeling, and machine learning tasks. It helps algorithms to use the importance of the words to predict outcomes.
Term Frequency (TF)
It is the ratio of the occurrence of the word (w) in document (d) per the total number of words in the documents. With this simple formulation, we are measuring the frequency of a word in the document.
For example, if the sentence has 6 words and contains two “the”, the TF ratio of this word would be (2/6).
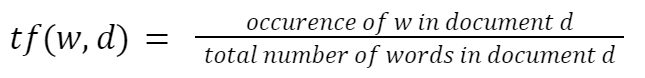
Inverse Document Frequency (IDF)
IDF calculates the importance of a word in a corpus D. The most frequently used words like “of, we, are” have little to no significance. It is calculated by dividing the total number of documents in the corpus by the number of documents containing the word.
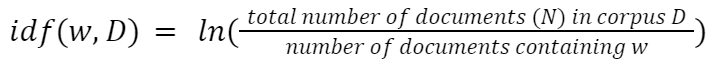

Term Frequency Inverse Document Frequency (TFIDF)
TF-IDF is the product of term frequency and inverse document frequency. It gives more importance to the word that is rare in the corpus and common in a document.
TF-IDF Matrix example from Vaibhav Jayaswal’s blog:
There are two documents in a corpus: Text A and Text B. We will use them to create a TF-IDF matrix.
- Text A: Jupiter is the largest planet
- Text B: Mars is the fourth planet from the sun
The table below shows the values of TF for A and B, IDF, and TFIDF for A and B.
| Words | TF ( A ) | TF ( B ) | IDF | TFIDF ( A ) | TFIDF ( B ) |
| jupiter | 1/5 | 0 | In (2/1)=0.69 | 0.138 | 0 |
| is | 1/5 | 1/8 | In (2/2)=0 | 0 | 0 |
| the | 1/5 | 2/8 | In (2/2)=0 | 0 | 0 |
| largest | 1/5 | 0 | In (2/1)=0.69 | 0.138 | 0 |
| planet | 1/5 | 1/8 | In (2/2)=0 | 0.138 | 0 |
| mars | 0 | 1/8 | In (2/1)=0.69 | 0 | 0.086 |
| fourth | 0 | 1/8 | In (2/1)=0.69 | 0 | 0.086 |
| from | 0 | 1/8 | In (2/1)=0.69 | 0 | 0.086 |
| sun | 0 | 1/8 | In (2/1)=0.69 | 0 | 0.086 |
TF-IDF Tutorial
In this tutorial, we are going to use TfidfVectorizer from scikit-learn to convert the text and view the TF-IDF matrix.
In the code below, we have a small corpus of 4 documents. First, we will create a vectorizer object using `TfidfVectorizer()` and fit and transform the text data into vectors. After that, we will use vectorizers to extract the names of the words.
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'KDnuggets Collection of data science Projects',
'3 Free Statistics Courses for data science',
'Parallel Processing Large File in Python',
'15 Python Coding Interview Questions You Must Know For data science',
]
vectorizer = TfidfVectorizer()
# TD-IDF Matrix
X = vectorizer.fit_transform(corpus)
# extracting feature names
tfidf_tokens = vectorizer.get_feature_names_out()
We will now use TF-IDF tokens and vectors to create a pandas dataframe.
- Convert the vectors to arrays and add it to the data argument.
- Four indexes are created manually.
- tfidf_tokens names are added to columns
import pandas as pd
result = pd.DataFrame(
data=X.toarray(),
index=["Doc1", "Doc2", "Doc3", "Doc4"],
columns=tfidf_tokens
)
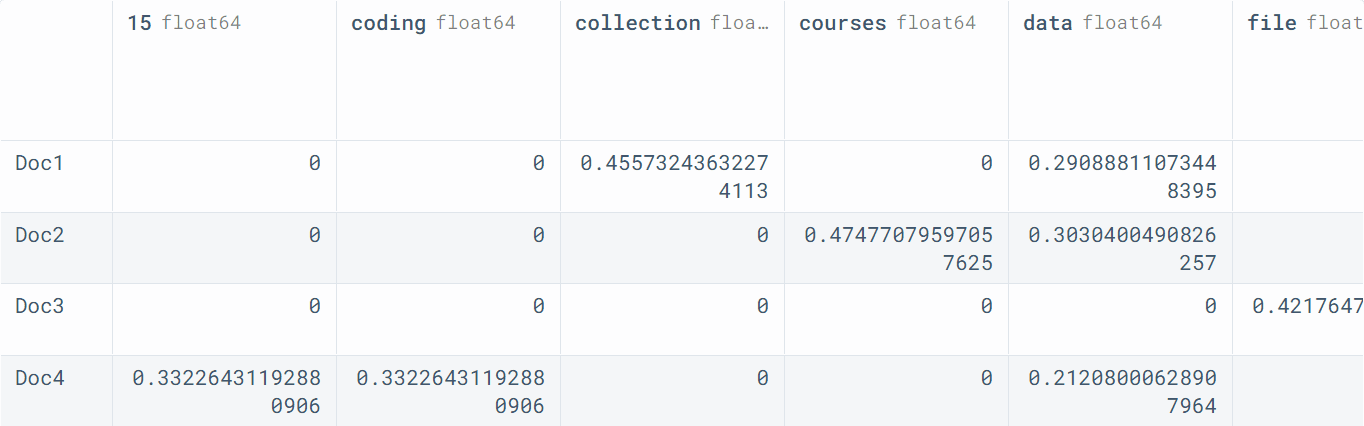
result
The pandas data frame shows columns as the words and rows as the documents.
In the dataframe below, every word has an important value based on the TF-IDF formula.
TF-IDF For Text Classification
Let’s go one step further and use the TF-IDF to convert text into vectors and then use it to train a text classification model. For training the model, we will be using Spotify App Reviews data from Kaggle.
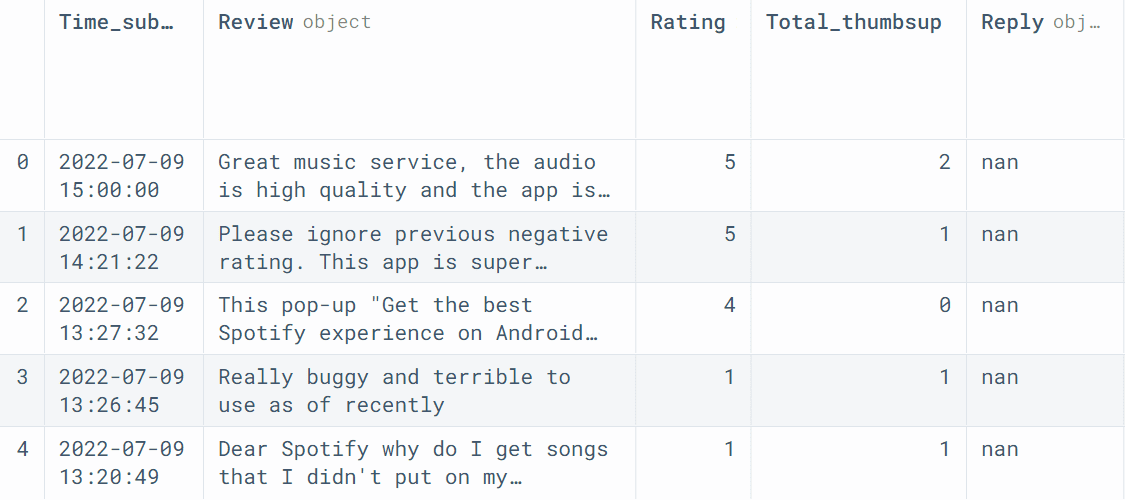
We will use read_csv to load the data and view the first five rows.
import pandas as pd
spotify = pd.read_csv("reviews.csv")
spotify.head()
We will be only using Review and Rating columns for training the models.
We will transform the Review column to vectors and set Rating as the target. After that, we will split the dataset for training and testing.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
# Transform features
X = spotify.Review
X_tfidf = vectorizer.fit_transform(X)
# create target
y = spotify.Rating
# split the dataset for training and testing
X_train, X_test, y_train, y_test = train_test_split(
X_tfidf, y, test_size=0.33, random_state=42
)
We won’t be going deep into feature engineering, text processing, or hyperparameter optimization. We will select a simple model (SGDClassifier) and train it on X_train and y_train.
For model validation, we will predict the values using X_test and print classification report.
from sklearn.linear_model import SGDClassifier from sklearn.metrics import classification_report # Training classifier model clf = SGDClassifier() clf.fit(X_train, y_train) # model validation y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred))
As we can observe, we got a 0.69 F1 score by training it on the default configuration. We can improve model performance by cross-validation, hyper-parameter optimization, text cleaning and processing, and feature engineering.
precision recall f1-score support
1 0.57 0.90 0.69 5817
2 0.25 0.03 0.05 2274
3 0.28 0.06 0.10 2293
4 0.41 0.19 0.26 2556
5 0.73 0.91 0.81 7387
accuracy 0.62 20327
macro avg 0.45 0.42 0.38 20327
weighted avg 0.54 0.62 0.54 20327
"Thank you for reading the tutorial. I hope I made a difference in making you understand the fundamentals of TF-IDF. If you have any further questions just type below or reach out on LinkedIn."
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in Technology Management and a bachelor's degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.