 Most Common SQL Mistakes on Data Science Interviews
Most Common SQL Mistakes on Data Science Interviews
 Most Common SQL Mistakes on Data Science Interviews
Most Common SQL Mistakes on Data Science InterviewsSure, we all make mistakes -- which can be a bit more painful when we are trying to get hired -- so check out these typical errors applicants make while answering SQL questions during data science interviews.

These mistakes concern concepts that frequently appear in data science coding interview questions and can render your interview unsuccessful, so it’s important to know how to avoid them and the ways in which we can correct them.
Mistake 1: LIMIT for maximum/minimum
Probably the most common mistake has to do with finding records in a data set with the highest or the lowest values. This sounds like a straightforward problem, but because of how SQL works, we frequently can’t simply use the MAX or MIN functions. Instead, we need to devise another way to output the relevant rows. When doing it, there is one commonly used approach that logically seems correct and, what’s worse, it often produces an expected result. The problem is that the solution doesn’t account for all the possibilities and skips some important edge cases. Let’s see an example to understand this mistake.

Link: https://platform.stratascratch.com/coding/10353-workers-with-the-highest-salaries
This question comes from an actual interview for a data scientist position at DoorDash. We are being asked to find the titles of workers that earn the highest salary given the datasets of employees and their titles. A common and probably the simplest solution to this problem looks like this:
SELECT t.worker_title FROM worker AS w LEFT JOIN title AS t ON w.worker_id = t.worker_ref_id ORDER BY w.salary DESC LIMIT 1
We need to merge two tables because the column worker_title comes from one dataset and the column ‘salary from another, but that’s not the part we should focus on. The rest of the code is a pretty straightforward way of returning a row with the highest value. We select the columns to return, order the table by some value in descending order, and only output the first row by using LIMIT 1. Can you see what the problem is with this solution?
In many cases, using this approach will produce the expected output, but the issue is that it skips an important and common edge case. Namely, what if there is a tie in the data? What if two rows have the same highest value? As you can see in this example, this solution is marked as incorrect, and that’s because there are, in fact, two job titles with the same salary, which also happens to be the highest salary. Using the LIMIT statement requires us to know how many rows share the highest value, and in most cases, we don’t know it, and so this approach is incorrect.
How to correct this solution? There are actually multiple ways to find the rows with maximum or minimum value in a robust way. One approach is to use a subquery in which we find the value of interest and then to use it as a filter in the main query. In our example, we can leave the first three lines of the code but instead of the ORDER BY and LIMIT statements, let’s add a WHERE clause. In it, we want to tell the engine to only leave these rows where the column ‘salary’ is equal to the highest salary of the entire dataset. In SQL, this will look something like that:
SELECT t.worker_title
FROM worker AS w
LEFT JOIN title AS t ON w.worker_id = t.worker_ref_id
WHERE w.salary IN
(SELECT max(salary)
FROM worker)
In the WHERE clause, there’s a subquery that only returns a single value - the highest salary. Then we use this number to filter the dataset, outputting only the rows where salary is equal to the number.
Another common approach is to use the window function RANK() to add a new column with a ranking of the job titles based on their salaries.
SELECT t.worker_title,
RANK() OVER (
ORDER BY w.salary DESC) AS rnk
FROM worker AS w
LEFT JOIN title AS t ON w.worker_id = t.worker_ref_id
As you can see, the RANK() function accounts for ties in the results because here, two job titles have the same salary, and they’re both given the first place. We can then use this ranking as an inner query and add the main query in which we only leave these titles where the rank number is equal to 1.
SELECT worker_title
FROM
(SELECT t.worker_title,
RANK() OVER (
ORDER BY w.salary DESC) AS rnk
FROM worker AS w
LEFT JOIN title AS t ON w.worker_id = t.worker_ref_id) a
WHERE rnk = 1
Mistake 2: Row_Number() vs Rank() vs Dense_Rank()
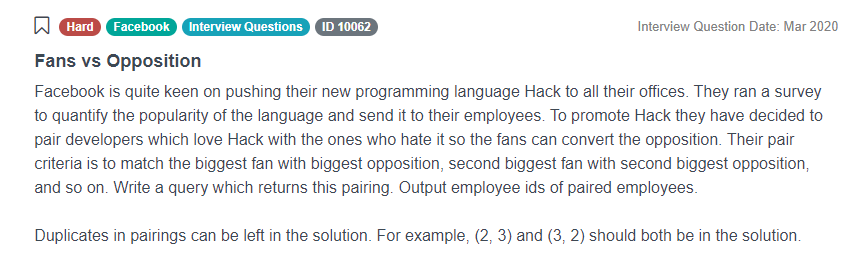
Link: https://platform.stratascratch.com/coding/10062-fans-vs-opposition
Speaking of RANK() and window functions in general, there is a common mistake related to them. Look at one of the SQL interview questions from Facebook above. Here Facebook says that they ran a survey among their employees to quantify the popularity of some new programming languages. Now they want to match the people who love it most to the ones who hate it most. The biggest fan gets paired with the biggest opposition, the second biggest fan with the second-biggest opposition, and so on.
Even though this interview question is long and seems difficult, the solution isn’t particularly complicated. We can simply take the dataset and order it by the popularity in descending order, then take it again, the order in ascending order, and put the two tables next to each other, or in technical terms, merge them. The solution may look something like that:
SELECT fans.employee_fan_id,
opposition.employee_opposition_id
FROM
(SELECT employee_id AS employee_fan_id,
RANK() OVER (
ORDER BY s.popularity DESC) AS position
FROM facebook_hack_survey s ) fans
INNER JOIN
(SELECT employee_id AS employee_opposition_id,
RANK() OVER (
ORDER BY s.popularity ASC) AS position
FROM facebook_hack_survey s ) opposition
ON fans.position = opposition.position
The key parts of this solution are the two subqueries on two sides of this ‘INNER JOIN’ statement. They return the same table but are sorted in opposite ways. To merge these tables together and to create the matching, the easiest way in SQL is to give employees subsequent numbers based on these orderings and match these numbers together so, the biggest fan will get number 1 and will be matched with the biggest opposition who also gets number 1 in the ‘opposition’ table.
But when we run this code, there is a problem. From the top of the results, we can see that employee 17 is paired with both employees 13 and 2. What’s more, the same employees 13 and 2 are also paired with an employee 5. And then again with an employee 8. Something is clearly wrong. Let’s modify the SELECT clause to show the rankings.
SELECT fans.employee_fan_id,
opposition.employee_opposition_id,
Fans.position AS position_fans,
Opposition.position AS position_opp
FROM
(SELECT employee_id AS employee_fan_id,
RANK() OVER (
ORDER BY s.popularity DESC) AS position
FROM facebook_hack_survey s ) fans
INNER JOIN
(SELECT employee_id AS employee_opposition_id,
RANK() OVER (
ORDER BY s.popularity ASC) AS position
FROM facebook_hack_survey s ) opposition
ON fans.position = opposition.position
What happened here? It seems like there are employees with the same score from the survey. In other words, there are ties in data. And as you may remember from the previous mistake, the RANK() function gives the same score to all rows that share the same value. So here, employees 17, 5, and 8 all had the same highest popularity score while employees 13 and 2 had the same lowest score. That’s why these five got matched together in all possible combinations. But if only 13 and 2 shared the same worst score, then there must have been an opposition employee with a rank of 3. But since there was no fan with rank 3, they didn’t get matched with anyone.
How to fix this? Some would say that if the RANK() function doesn’t work, we can try replacing it with DENSE_RANK(). The difference between the two is in how they handle ties. If we have four values and the first two are the same, then RANK() will give them ranks 1, 1, 3, and 4. Meanwhile, DENSE_RANK() would rank them as 1, 1, 2, and 3. But is it the right solution in this case?
SELECT fans.employee_fan_id,
opposition.employee_opposition_id,
fans.position as position_fans,
opposition.position as position_opp
FROM
(SELECT employee_id AS employee_fan_id,
DENSE_RANK() OVER (
ORDER BY s.popularity DESC) AS position
FROM facebook_hack_survey s ) fans
INNER JOIN
(SELECT employee_id AS employee_opposition_id,
DENSE_RANK() OVER (
ORDER BY s.popularity ASC) AS position
FROM facebook_hack_survey s ) opposition
ON fans.position = opposition.position
We solved the problem with employee 10 not being matched with anyone like before, but the other issues are still there. The DENSE_RANK() still gives the same ranking to rows with the same value, so there are still some employees paired with more than one person. So what’s the correct solution here? There is a third similar window function called ROW_NUMBER(). Some disregard it as being ‘basic’ because it simply counts the rows without dealing with tied values. But that’s exactly the feature that makes this function perfect in this case.
SELECT fans.employee_fan_id,
opposition.employee_opposition_id,
fans.position as position_fans,
opposition.position as position_opp
FROM
(SELECT employee_id AS employee_fan_id,
ROW_NUMBER() OVER (
ORDER BY s.popularity DESC) AS position
FROM facebook_hack_survey s ) fans
INNER JOIN
(SELECT employee_id AS employee_opposition_id,
ROW_NUMBER() OVER (
ORDER BY s.popularity ASC) AS position
FROM facebook_hack_survey s ) opposition
ON fans.position = opposition.position
All employees are now given unique ranks and so the pairing can be done without duplicates and skipping anyone. And while this problem of pairing fans with the opposition is not the most common at data science interviews, but based on this example, we wanted to show you how important it is to understand the difference between RANK(), DENSE_RANK(), and ROW_NUMBER() - all very similar window functions.
Mistake 3: Aliases in quotation marks

In this example, we gave names to some subqueries, like ‘fans’ and ‘opposition’, and to some columns as well. These are so-called aliases and are very popular in SQL but are also a source of some common mistakes. Let’s switch to an easier example to see them.

Link: https://platform.stratascratch.com/coding/2061-users-with-many-searches?python=
In this recent data science interview question, Facebook asked to count the number of users who made more than five searches in August 2021, based on some database of searches. The solution looks like this:
SELECT count(user_id) AS result
FROM
(SELECT user_id,
count(search_id) AS "AugustSearches"
FROM fb_searches
WHERE date::date BETWEEN '2021-08-01' AND '2021-08-31'
GROUP BY user_id) a
WHERE AugustSearches > 5
There is an inner query in which we count the number of searches for each user in the required timeframe and then an outer query in which we only consider users who made more than five searches, and we count them. But when we try to run it, there’s an error. It says that ‘column "augustsearches" does not exist’. How is it possible? After all, we gave the alias ‘AugustSearches’ to one of the columns in the inner query, so we should be able to use it in the WHERE clause of the outer query, right? Well, yes, but unfortunately, we made a mistake when assigning the alias. Can you see it? The simplest way to fix it is to remove the quotation marks from the alias:
SELECT count(user_id) AS result
FROM
(SELECT user_id,
count(search_id) AS AugustSearches
FROM fb_searches
WHERE date::date BETWEEN '2021-08-01' AND '2021-08-31'
GROUP BY user_id) a
WHERE AugustSearches > 5
It is a common mistake because we use quotation marks when writing strings in SQL, and an alias feels like a string. But the reason for it not working actually originates elsewhere and has to do with the capital letters. To save memory, SQL always forces the column names to small letters. So even if we write ‘WHERE AugustSearches’, SQL will interpret it as ‘WHERE augustsearches’. But when we define an alias in quotation marks, SQL keeps all the capitalized letters but then when we compare the alias to an alias written without quotation marks, it causes the problem. In theory, we could always use the aliases in quotation marks:
SELECT count(user_id) AS result
FROM
(SELECT user_id,
count(search_id) AS "AugustSearches"
FROM fb_searches
WHERE date::date BETWEEN '2021-08-01' AND '2021-08-31'
GROUP BY user_id) a
WHERE “AugustSearches” > 5
This code will run, but this will take much longer to compute, will consume more memory, and may cause some confusion. And we need to remember quotation marks every time when using an alias. So the lesson here is not to use them for aliases. And to only use small letters for aliases.
SELECT count(user_id) AS result
FROM
(SELECT user_id,
count(search_id) AS august_searches
FROM fb_searches
WHERE date::date BETWEEN '2021-08-01' AND '2021-08-31'
GROUP BY user_id) a
WHERE august_searches > 5
Mistake 4: Inconsistency in aliases
Link: https://platform.stratascratch.com/coding/10353-workers-with-the-highest-salaries
Another common problem is inconsistency in using aliases. It’s not a huge mistake, and as long as we don’t have the same column names in different tables, it won’t cause major problems. But this is a detail that can decide about the success or a failure of your data science interview. Let’s get back for a moment to the question from the beginning, the one about highest-earning job titles. This is another possible and correct solution for this question:
SELECT t.worker_title
FROM worker w
LEFT JOIN title t ON w.worker_id = t.worker_ref_id
WHERE salary =
(SELECT MAX(salary)
FROM worker w
LEFT JOIN title t ON w.worker_id = t.worker_ref_id)
ORDER BY worker_title ASC
Can you see the issue with aliases? First of all, we define the aliases for the two tables. In this case, it’s letters ‘w’ and ‘t’. We then say ‘t.worker_title’, but why in the WHERE clause do we have ‘salary’ without any alias? Why does the column ‘worker_title’ in the ORDER BY clause has no alias suddenly? And look at the subquery: we give aliases to the tables only to not use them when selecting the only column in this query. Another issue is using the same aliases in the inner and outer queries, but since, in this case, it’s always for the same tables, we can let it slide. This solution will look much cleaner and clearer if we stay consistent when using aliases.
SELECT t.worker_title
FROM worker w
LEFT JOIN title t ON w.worker_id = t.worker_ref_id
WHERE w.salary =
(SELECT MAX(w.salary)
FROM worker w
LEFT JOIN title t ON w.worker_id = t.worker_ref_id)
ORDER BY t.worker_title ASC
Mistake 5: Unnecessary JOINs
But we’re not quite done yet. There is one more mistake in this solution. Yes, it still works and produces an expected result, but we can’t say it’s efficient. Can you see why? Look at the inner query. In it, we only select one column, salary. This column comes from a table ‘worker’. It’s especially clear now that we fixed the aliases. But if this is the case, then why do we merge the two tables in the inner query? It’s not necessary, and it makes the solution less efficient. After all, each JOIN operation takes some time to compute, and if the tables are large, this time may be considerable. We know that frequently when we see that a question comes with several tables, the logical first step is to merge them together. But as this example shows, we should only do it when it’s necessary.
SELECT t.worker_title
FROM worker w
LEFT JOIN title t ON w.worker_id = t.worker_ref_id
WHERE w.salary =
(SELECT MAX(w.salary)
FROM worker w
ORDER BY t.worker_title ASC
Mistake 6: JOIN on columns with NULL values
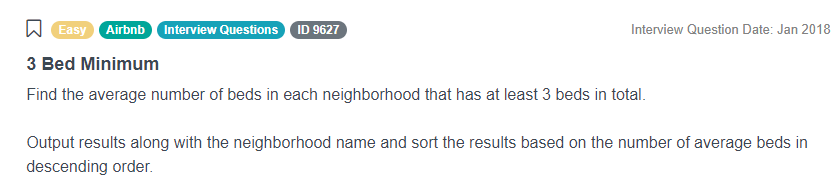
Link: https://platform.stratascratch.com/coding/9627-3-bed-minimum
Let us show you one more common mistake, again related to the JOIN statements. Look at this question in which Airbnb asks to find the average number of beds in each neighbourhood that has at least three beds in total. While there exist less complicated solutions, one valid approach is to merge the original table with itself but in an aggregated way so that we already have the number of beds per neighbourhood given that it’s at least three beds. We could do it using a subquery or with a JOIN statement like in this solution:
SELECT anb.neighbourhood,
avg(anb.beds) AS avg_n_beds
FROM airbnb_search_details AS anb
RIGHT JOIN
(SELECT neighbourhood,
sum(beds)
FROM airbnb_search_details
GROUP BY 1
HAVING sum(beds)>=3) AS fil_anb
ON anb.neighbourhood = fil_anb.neighbourhood
GROUP BY 1
ORDER BY avg_n_beds DESC
When we run this code, it looks nice at first glance, but what is this space here on top? And when we compare this output with the expected results, it turns out our code is not correct. So what happened? Let’s run only the inner query to look for clues.
SELECT neighbourhood,
sum(beds)
FROM airbnb_search_details
GROUP BY 1
HAVING sum(beds)>=3
Can you see this first row? It turns out there are 33 beds that are not assigned to any neighbourhood. Instead, the value for the neighbourhood is ‘NULL’. Why does it cause problems? Because back in our main query, we JOIN the two tables ON the neighbourhood columns - both of which contain NULL values. And in SQL, if we use the operator ‘=’ between NULL values, the engine won’t be able to match them correctly.
How to fix this problem? If we really need to merge two tables based on a column that contains NULL values, we need to explicitly tell the engine how to deal with them. So we can start as we did before, saying ‘anb.neighbourhood = fil_anb.neighbourhood’ and then continue by adding a second case: if a value in anb.neighbourhood is NULL, a value in fil_anb.neighbourhood should also be ‘NULL’. In code, it’ll look like this:
SELECT anb.neighbourhood,
avg(anb.beds) AS avg_n_beds
FROM airbnb_search_details AS anb
RIGHT JOIN
(SELECT neighbourhood,
sum(beds)
FROM airbnb_search_details
GROUP BY 1
HAVING sum(beds)>=3) AS fil_anb
ON (anb.neighbourhood= fil_anb.neighbourhood) or (anb.neighbourhood is NULL
and fil_anb.neighbourhood is NULL)
GROUP BY 1
ORDER BY avg_n_beds DESC
Conclusion
These are all the examples we have prepared for you in this article. We have shown you a number of different coding mistakes, some more and some less catastrophic but all equally important, especially in an interview setting. There it’s not only about whether a solution works but also how it’s written and if you as a candidate have attention to detail. If you remember these few most common mistakes and try to avoid them in the future, this will improve your chances of succeeding in a data science interview!
Original. Reposted with permission.
Related: