Combining Pandas DataFrames Made Simple
For this tutorial, we will work through examples to understand how different mehtods for combining Pandas DataFrames work.
Introduction
In many Real-Life Scenarios, our data is placed in different files for the sake of management and simplicity. We often need to combine them into a single, larger DataFrame for analysis. Pandas package comes to our rescue by providing us with various methods to combine the DataFrames like concat and merge. In addition, it also provides the utilities for comparison purposes.
We will work through the examples to understand how both methods work. For this tutorial, we will assume that you have basic knowledge about Python and Pandas.
Concatenating Dataframes
If the format of the two DataFrames is the same, we opt for the .concat() method. It appends either the columns or rows from one DataFrame to another. The .concat() takes full responsibility for performing the concatenation operation along the axis. Before we dive into its details, let us have a quick look at the function syntax and its parameter.
pd.concat(objs, axis=0, join="outer",ignore_index=False, keys=None,
levels=None, names=None, verify_integrity=False, copy=True, )
Though there is much going on, we will focus on the prime parameters only :
- objs: List of DataFrame objects or Series to be concatenated
- axis: axis = 0 tells the pandas to stack the second DataFrame under the first one (concatenating by rows) while axis =1 tells the pandas to stack the second DataFrame to the right of the first one (concatenating by columns). By default , axis = 0.
- join: By default join= outer, outer is used for union and inner for intersection
- ignore_index: It would ignore the index axis in the concatenation process, and by default, it's kept as False because they are respected in the join. However, if the index axis does not have meaningful information, then it is useful to ignore them.
- verify_integrity: It checks for duplicates in the new concatenated axis but by default, it's kept as False as it can be very expensive relative to actual concatenation itself.
Example
import pandas as pd
# First Dict with two 2 and 4 columns
data_one = {'A' : ['A1','A2','A3','A4'] , 'B' : ['B1','B2','B3','B4']}
# Second Dict with two 2 and 4 columns
data_two = {'C' : ['C1','C2','C3','C4'] , 'D' : ['D1','D2','D3', 'D4']}
# Converting to DataFrames
df_one=pd.DataFrame(data_one)
df_two=pd.DataFrame(data_two)

Scenario 1: Concatenating by Columns
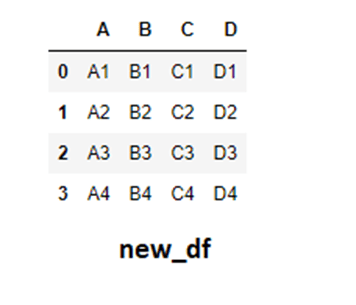
Assuming that columns A, B, C & D represent different functionalities but the index number refers to the same id, it makes more sense to join the C, and D rows to the right of df_one. Let's do it,
# Joining the columns new_df = pd.concat([df_one,df_two],axis=1)
Scenario 2: Concatenating by Rows
If we continue our above assumption and concatenate them by rows, then the resulting DataFrame will have a lot of missing data in form of NaN values. The reason is simple, let's say for index = 0 in df_two we cannot place it directly under columns A and B as we considered them to be separate functions for which the value is not present. Hence pandas will automatically create a complete row for A, B, C, and D with missing values in their respective columns.
# Joining the rows new_df1 = pd.concat([df_one,df_two],axis=0)
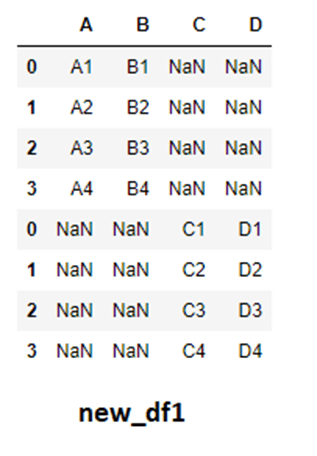
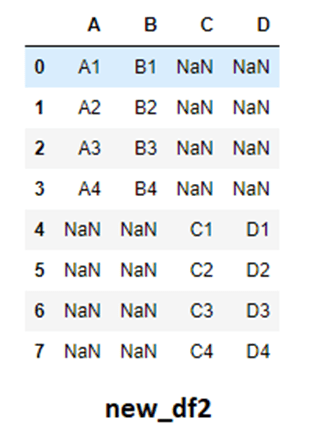
Notice that we have the duplicate index in our final result. This is because by default ignore_index is set to False which saves the index of DataFrames as it is present originally. This may not be useful in our case so we will set ignore_index = True.
# Joining the rows new_df2 = pd.concat([df_one,df_two],axis=0 , ignore_index= True)
If the columns in both the DataFrames represent the same thing and are just named differently, then we can rename the columns before concatenating.
# Joining the rows df_two.columns = df_one.columns new_df3 = pd.concat([df_one,df_two],axis=0 , ignore_index= True)

Merging Dataframes
Merging or joining the dataFrames is different from concatenating. Concatenating means just stacking up one dataFrame on another along the desired axis. While joining works just like the joins in SQL. We can combine the dataFrames based on a unique column. These methods have high performance and perform significantly better. It is useful when one DataFrame is the “lookup Table” containing additional data that we want to join to the other. Let's take a look at its syntax and parameters:
pd.merge( left, right, how="inner", on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True, suffixes=("_x", "_y"),
copy=True, indicator=False, validate=None)
Let's take a look at its prime parameters and what are they for :
- left: Dataframe object
- right: Dataframe object
- how: Join type i.e inner, outer, left, right, etc. By default how = “inner”
- on: Column common in both DataFrame and forms the basis for join operation.
- left_on: If you are using the right_index as the column to join on then you must specify the column that will be used as the key.
- right_on: Vice versa of left_on
- left_index: if set to True, then it uses the row labels (Index) of left DataFrame as join key
- right_index: Vice Versa of left_index
- sort: Sort the resultant dataFrame by join keys in lexicographical order but it is not recommended as it substantially affects the performance.
- suffixes: If we have an overlapping column, you can assign the suffixes to distinguish between them. By default, it is set to ('_x', '_y').
Example
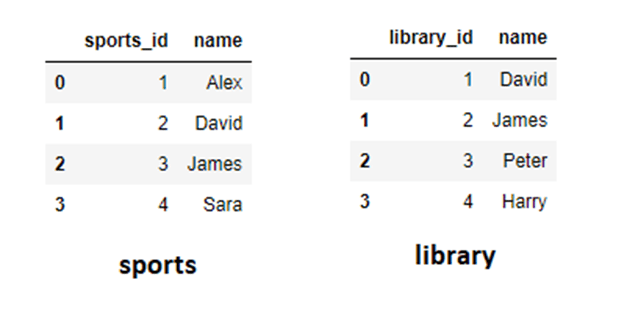
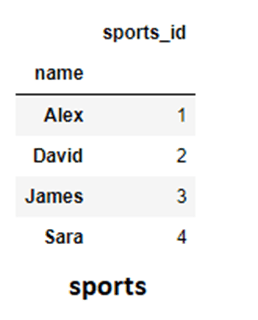
Consider an example of sports and a library dataFrame and assume that the “name” column in both the DataFrames is unique and can be used as the primary key.
import pandas as pd
# First DataFrame
sports= pd.DataFrame({'sports_id':[1,2,3,4],'name':['Alex','David','James','Sara']})
# Second DataFrame
library= pd.DataFrame({'library_id':[1,2,3,4],'name':['David','James','Peter','Harry']})
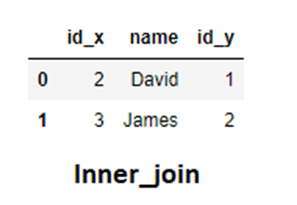
Scenario 1: Inner and Outer Join
For both of them, the order in which you place the dataFrame in the .merge() method doesn’t matter as the final result would still be the same. If we consider the two DataFrames as the two sets then the inner join would refer to their intersection while the outer join to their union.
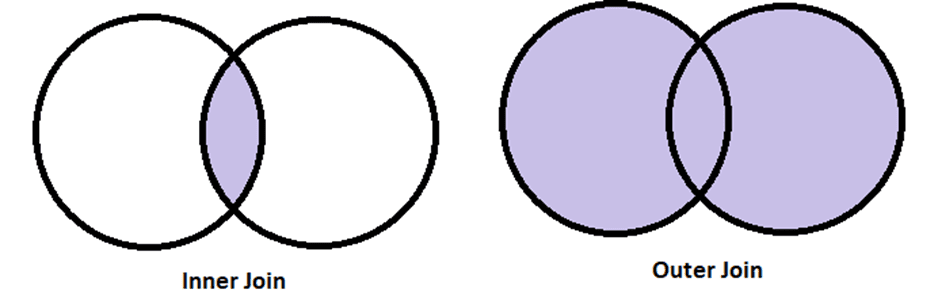
inner_join = pd.merge(sports,library,how="inner",on="name") outer_join= pd.merge(library,sports,how="outer",on="name")

Scenario 2: Left and Right Join
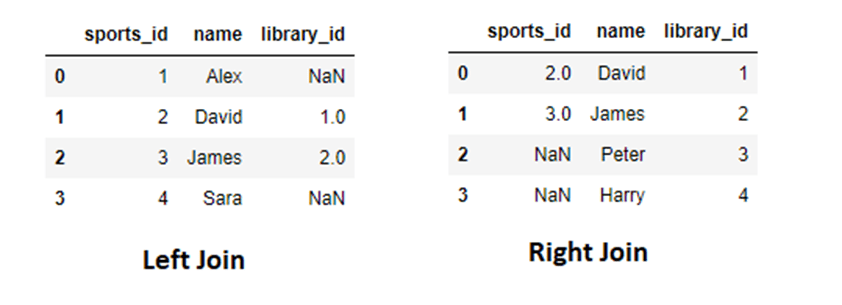
Here, the order in which we place the DataFrames matter. For example, in the left join, all the entries of the DataFrame object placed in the left spot will be displayed along with their matching entries from the right DataFrame object. The right join is just the opposite of what the left join does. Let us understand the concept from an example,
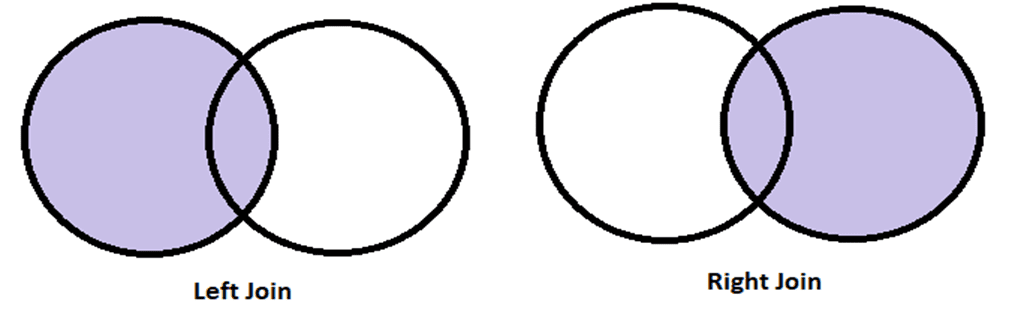
left_join = pd.merge(sports,library,how="left",on="name") right_join= pd.merge(library,sports,how="right",on="name")
Scenario 3: Joining when using Index
Firstly, Let us modify our sports table to make the “ name” column an index by using the set_index() method.
sports = sports.set_index("name")
Now we will apply the inner operation and set the value of left_index= True if we are taking sports as our left DataFrame.
index_join = pd.merge(sports,library,how="inner",left_index = True , right_on="name")
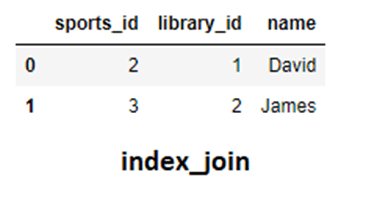
Notice that it shows the same result as we did earlier for the inner join.
Scenario 4: Suffixes Attribute
Let us make a small modification to our original dataFrames by changing the sports_id and login_id as the id. Now although the name is the same, but we are referring to different ids. Pandas is smart enough to identify it and it adds the suffixes itself. We will see later on how to customize these suffixes ourselves.
# First DataFrame
sports= pd.DataFrame({'id':[1,2,3,4],'name':['Alex','David','James','Sara']})
# Second DataFrame
library= pd.DataFrame({'id':[1,2,3,4],'name':['David','James','Peter','Harry']})
inner_join = pd.merge(sports,library,how="inner",on="name")
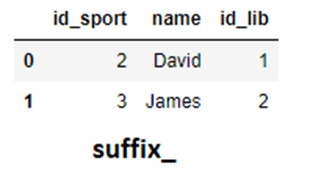
Here the id_x refers to the left dataFrame while id_y refers to the right one. Although, it does its job but for the sake of readability and cleaner code we customize these suffixes by using the suffixes attribute.
suffix_ = pd.merge(sports,library,how="inner",on="name", suffixes=('_sport','_lib'))
Conclusion
This article was intended to simplify the concept of combining the rows in Pandas. When you are extracting the data on a larger scale lets say from .csv files, it is always recommended to analyze the type and format of data before you begin to perform the joining operation. Pandas has some excellent methods in this regard too. In case of any issue, you should refer to the official documentation of Pandas. Last but not least, everything comes with practice so experiment with different DataFrames in your own time for better understanding.
Kanwal Mehreen is aspiring Software Developer who believes in consistent hard work and commitment. She is an ambitious programmer with a keen interest in the field of Data Science and Machine Learning.