Classifying Long Text Documents Using BERT
Transformer based language models such as BERT are really good at understanding the semantic context because they were designed specifically for that purpose. BERT outperforms all NLP baselines, but as we say in the scientific community, “no free lunch”. How can we use BERT to classify long text documents?
By Sinequa
What do we want to achieve?
We want to classify texts into predefined categories which is a very common task in NLP. For many years, the classical approach for simple documents was to generate features using TF-IDF and combine it with logistic regression. Formerly we used to rely on this stack at Sinequa for textual classification, and, spoiler alert, with the model presented here we have beaten our baseline from 5% to 30% for very noisy and long documents datasets. This former approach had two main issues: the feature sparsity that we tackled via compression techniques and the word-matching issue that we tamed leveraging Sinequa’s powerful linguistic capacities (mainly through our homegrown tokenizer).
Later on, the pandora box of language models (pre-trained on humongous corpora in an unsupervised fashion and fine-tuned on downstream supervised tasks) was opened and TF-IDF based techniques were not state of the art anymore. Such language models could be word2vec combined with LSTMs or CNNs, ELMo, and most importantly the Transformer (in 2017: https://arxiv.org/pdf/1706.03762.pdf).
BERT is a Transformer based language model that has gained a lot of momentum in the last couple of years since it beat all NLP baselines by far and came as a natural choice to build our text classification.
What is the challenge then?
Transformer based language models such as BERT are really good at understanding the semantic context (where bag-of-words techniques fail) because they were designed specifically for that purpose. As explained in the introduction, BERT outperforms all NLP baselines, but as we say in the scientific community, “no free lunch”. This extensive semantic comprehension of a model like BERT offers comes with a big caveat: it cannot deal with very long text sequences. Basically, this limitation is 512 tokens (a token being a word or a subword of the text) which represent more or less two or three Wikipedia paragraphs and we obviously don’t want to consider only such a small sub-part of a text to classify it.
To illustrate this, let’s consider the task of classifying comprehensive product reviews into positive or negative reviews. The first sentences or paragraphs may only contain a description of the product and it would likely require to go further down the review to understand whether the reviewer actually likes the product or not. If our model does not encompass the whole content, it might not be possible to make the right prediction. Therefore, one requirement for our model is to capture the context of a document while managing correctly long-time dependencies between the sentences at the beginning and the end of the document.
Technically speaking, the core limitation is the memory footprint that grows quadratically with the number of tokens along with the use of pre-trained models that come with a fixed size determined by Google (& al.). This is expected since each token is “attentive” [https://arxiv.org/pdf/1706.03762.pdf] to every other token and therefore requires a [N x N] attention matrix, with [N] the number of tokens. For example, BERT accepts a maximum of 512 tokens which hardly qualifies as long text. And going beyond 512 tokens rapidly reaches the limits of even modern GPUs.
Another problem that arises using Transformers in a production environment is the very slow inference due to the size of the models (110M parameters for BERT base) and, again, the quadratic cost. So, our goal is not only to find an architecture that fits into memory during the training but to find one that also responds reasonably fast during inference.
The last challenge we address here is to build a model based on various feature types: long text of course, but also additional textual metadata (such as title, abstract …) and categories (location, authors …).
So, how to deal with really long documents?
The main idea is to split the document into shorter sequences and feed these sequences into a BERT model. We obtain the CLS embedding for each sequence and merge the embeddings. There are a couple of possibilities to perform the merge, we experimented with:
- Convolutional Neural Networks (CNN)
- Long Short-Term Memory Networks (LSTM)
- Transformers (to aggregate Transformers, yes :) )
Our experiments on different standard text classification corpora showed that using additional Transformer layers to merge the produced embeddings works best without introducing a large computational cost.
Want the formal description, right?
We consider a text classification task with L labels. For a document D, its tokens given by the WordPiece tokenization can be written X =( x₁, …, xₙ) with N the total number of token in D. Let K be the maximal sequence length (up to 512 for BERT). Let I be the number of sequences of K tokens or less in D, it is given by I=⌊ N/K ⌋.
Note that if the last sequence in the document has a size lower to K it will be padded with 0 until the Kᵗʰ index. Then if sⁱ with i∈ {1, .., I}, is the i-th sequence with K elements in D, we have:
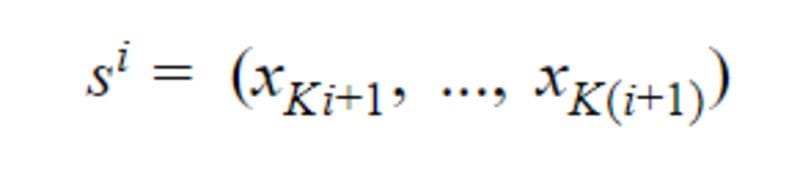
We can note that
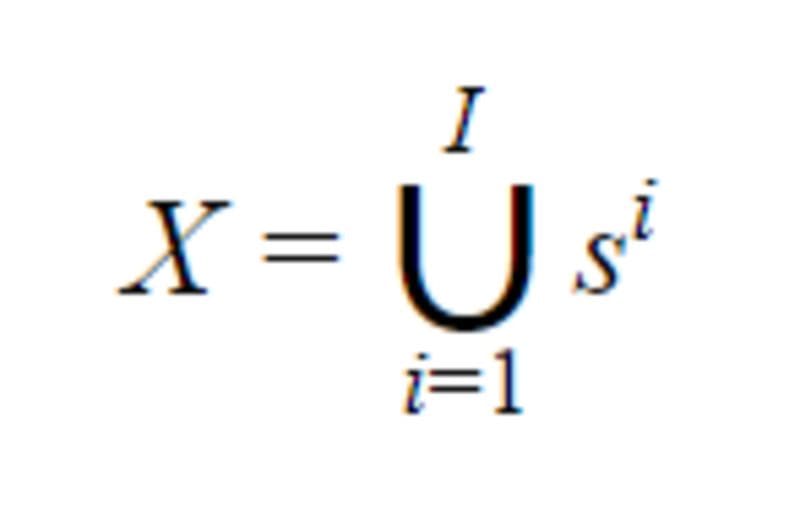
BERT returns the CLS embedding but also an embedding per token.
Let define the embeddings per token returned by BERT for the i-th sequence of the document such as:
where CLS is the embedding of the special token inserted in front of each text sequence fed to BERT, it is generally considered as an embedding summarizing the full sequence.
To combine the sequences, we only use CLSᵢ and do not use y. We use t transformers T₁, …,Tₜ to obtain the final vector to feed to the last dense layer of the network:
where ∘ is the function composition operation.
Given the last dense layer weights W ∈ ℝᴸˣᴴ where H is the hidden size of the transformer and bias b ∈ ℝᴸ
The probabilities P ∈ ℝᴸ are given by:
Finally, applying argmax on the vector P returns the predicted label. For a summary of the above architecture, you can have a look at figure 1.
The architecture above enables us to leverage BERT for the text classification task bypassing the maximum sequence length limitation of transformers while at the same time keeping the context over multiple sequences. Let’s see how to combine it with other types of features.
How to deal with metadata?
Oftentimes, a document comes with more than just its content. There can be metadata that we divide into two groups, textual metadata, and categorical metadata.
Textual Metadata
By textual metadata, we mean short text that has (after tokenization) a relatively small number of tokens. This is required to fit entirely into our language model. A typical example of such metadata would be titles or abstracts.
Given a document with M metadata annotation. Let
be the CLS embeddings produced by BERT for each metadata. The same technique as above is used to get the probability vector as:
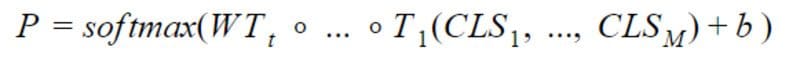
Categorical Metadata
Categorical metadata can be a numerical or textual value that represents a category. Numerical values can be the number of pages whereas textual values can be the publisher name or a geo-location.
A common way to deal with such features is to implement the Wide and Deep architecture. Our experiments showed that results yielded by the deep part of this network were sufficiently good and the wide part was not required.
We encode the categorical metadata in a single cross-category vector using one-hot encoding. This encoding is then passed into an embedding layer that learns a vector representation for each distinct category. The last step is to apply a pooling layer on the resulting embedding matrix.
We considered max, average and min pooling and found that using average pooling worked best for our test corpora.
How does the complete architecture look?
Hope you stuck around until now, the following figure will hopefully make things a lot clearer.
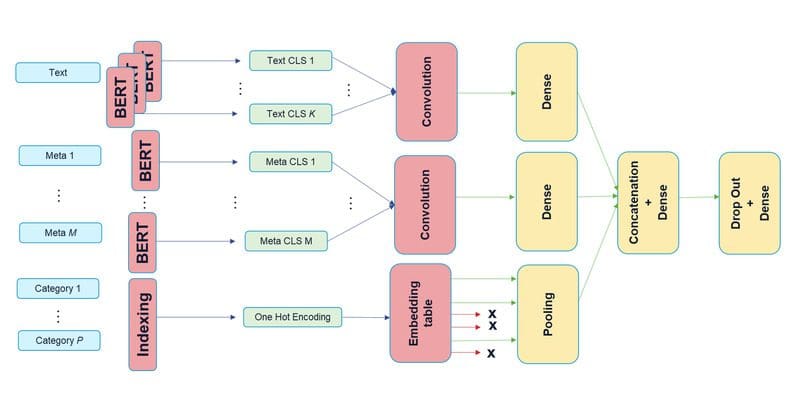
Figure 1
There are three sub-models, one for text, another for textual metadata, and the last one for categorical metadata. The output of the three sub-models is merely concatenated into a single vector before passing it through a dropout layer and finally into the last dense layer with a softmax activation for the classification.
You probably have noticed that there are multiple BERT instances depicted in the architecture, not only for the text input but also for the textual metadata. As BERT comes with many parameters to train, we decided not to include a separate BERT model per sub-model, but instead share the weights of a single model in between the sub-models. Sharing weights certainly reduces the RAM used by the model (enabling training with larger batch-size, so accelerating training in a sense) but it does not change the inference-time since there will still be as many BERT executions no matter whether their weights are shared or not.
What about inference time?
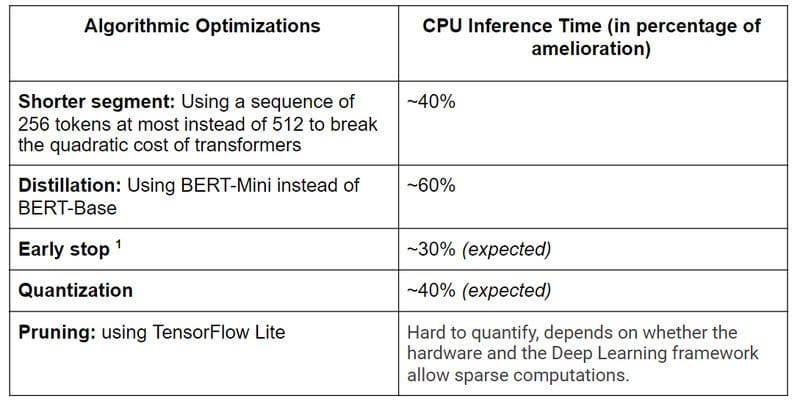
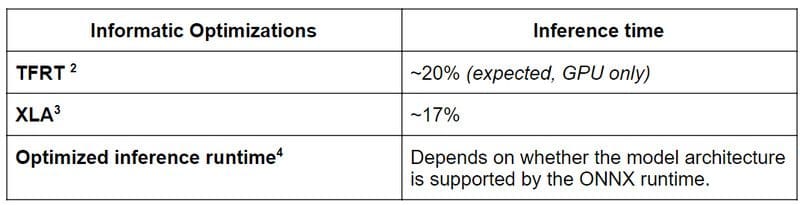
By now, you must have guessed that including that many invocations of the BERT model do not come for free. And it is true that it is computationally expensive to run inference of such a model. However, there are a couple of tricks to improve inference times. In the following, we focus on CPU inference as this is very important in production environments.
A couple of notes for the conducted experiments:
- We consider a simplified model only containing a text feature.
- We limited the tokens that we used per document to 25,600 tokens which correspond roughly to around 130,000 characters if the document contains English text.
- We perform the experiments with documents that have the above described maximum length. In practice, documents have varying sizes and as we use dynamic size tensors in our model, inference times are considerably faster for short documents. As a rule of thumb, when using a document that is half as long reduces the inference time by 50 %.
References
- https://arxiv.org/abs/2006.04152, https://arxiv.org/pdf/2001.08950.pdf
- https://blog.tensorflow.org/2020/04/tfrt-new-tensorflow-runtime.html
- https://www.tensorflow.org/xla?hl=fr
- https://medium.com/microsoftazure/accelerate-your-nlp-pipelines-using-hugging-face-transformers-and-onnx-runtime-2443578f4333
What else is there to do?
Linear Transformers
Building a Transformer-like architecture that does not come with the quadratic complexity in time and memory is currently a very active field of research. There are a couple of candidates that are definitely worth trying once pre-trained models will be released:
- Linformer [https://arxiv.org/pdf/2006.04768.pdf]
- BigBird [https://arxiv.org/pdf/2007.14062.pdf]
- Reformers [https://arxiv.org/pdf/2001.04451.pdf] (only O(N log(N)) complexity)
- Performers [https://arxiv.org/pdf/2009.14794.pdf]
- etc…
A preliminary test with the very promising Longformer model could not be executed successfully. We tried to train a LongFormer model using the TensorFlow implementation of Hugging Face. However, it appears that the implementation is not yet memory-optimized as it was not possible to train it even on a large GPU with 48 GB of memory.
Inference time is the cornerstone of any ML project that needs to run in production, so we do plan to use such “linear transformers” in the future in addition to pruning and quantization.
Are we done yet?
Yes, thanks for sticking with us until the end. If you have questions or remarks about our model, feel free to comment. We would love to hear from you.
Original. Reposted with permission.