
Robolawyer. Credit: Midjourney
If you read my work you probably know that I publish my articles first and foremost in my AI newsletter, The Algorithmic Bridge. What you may not know is that every Sunday I publish a special column I call “what you may have missed,” where I review everything that has happened during the week with analyses that help you make sense of the news.
ChatGPT, ChatGPT, and more ChatGPT
Microsoft-OpenAI $10-billion deal
Semafor reported two weeks ago that, if everything goes according to the plan, Microsoft will close a $10B investment deal with OpenAI before the end of January (Satya Nadella, Microsoft’s CEO, announced the extended partnership officially on Monday).
There’s been some misinformation about the deal which implied that OpenAI execs weren’t sure about the company’s long-term viability. However, it was later clarified that the deal looks like this:
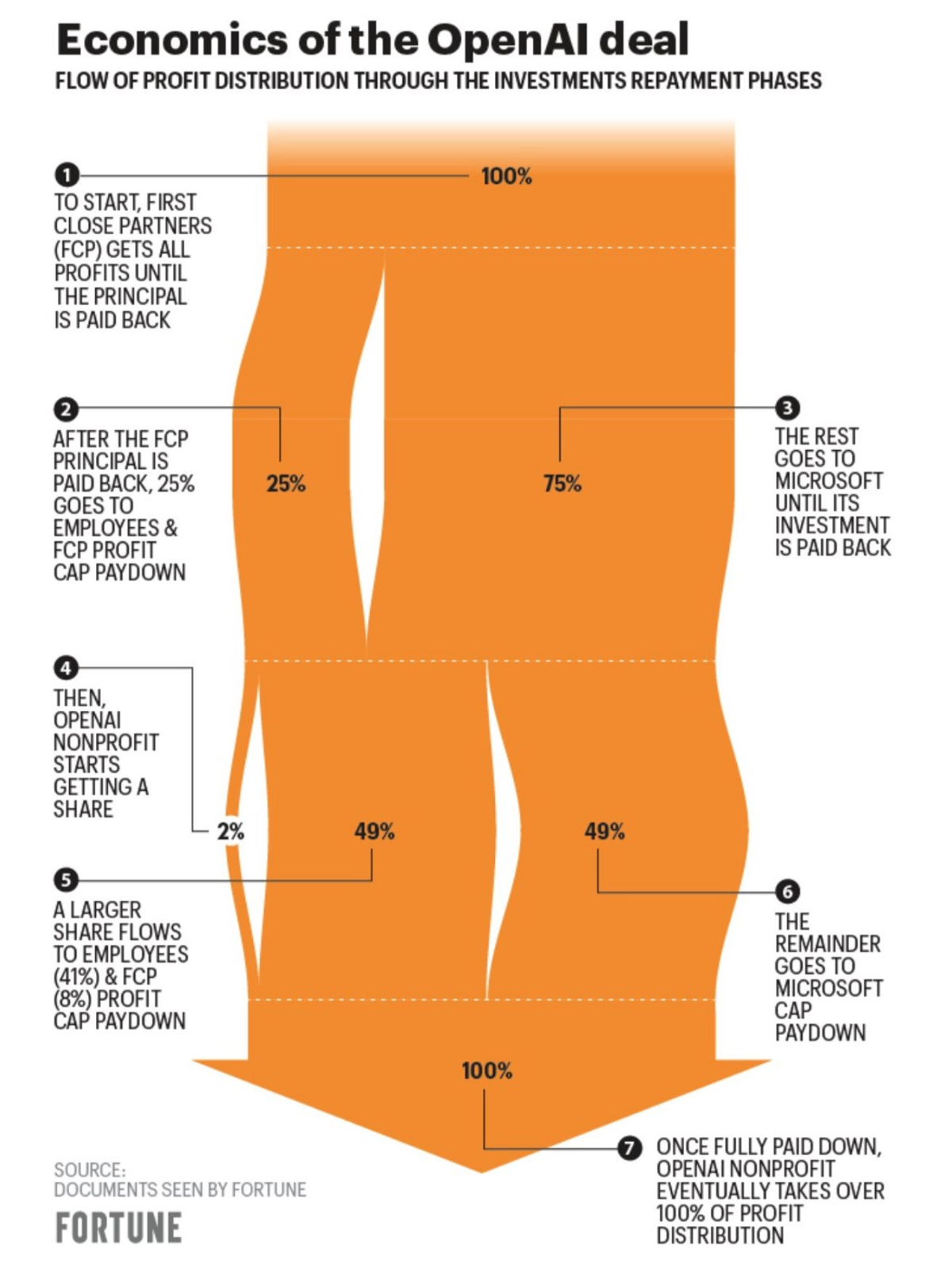
Credit: Fortune
Leo L’Orange, who writes The Neuron, explains that “once $92 billion in profit plus $13 billion in initial investment are repaid to Microsoft and once the other venture investors earn $150 billion, all of the equity reverts back to OpenAI.”
People are divided. Some say the deal is “cool” or “interesting”, whereas others say it’s “odd” and “crazy”. What I perceive with my non-expert eyes is that OpenAI and Sam Altman do trust (some would say overtrust) the company’s long-term ability to achieve its goals.
However, as Will Knight writes for WIRED, “it’s unclear what products can be built on the technology.” OpenAI must figure out a viable business model soon.
Changes to ChatGPT: New features and monetization
OpenAI updated ChatGPT on Jan 9 (from the previous update on Dec 15). Now the chatbot has “improved factuality” and you can stop it mid-generation.
They’re also working on a “professional version of ChatGPT” (which is rumored to go out at $42/month) as OpenAI’s president Greg Brockman announced on Jan 11. These are the three main features:
“Always available (no blackout windows).
Fast responses from ChatGPT (i.e. no throttling).
As many messages as you need (at least 2X regular daily limit).”
To sign up for the waitlist you have to fill out a form where they ask you, among other things, how much you’d be willing to pay (and how much would be too much).
If you plan to take it seriously, you should consider going deep into OpenAI’s product stack with the OpenAI cookbook repo. Bojan Tunguz said it is “the top trending repo on GitHub this month.” Always a good sign.
ChatGPT, the fake scientist
ChatGPT has entered the scientific domain. Kareem Carr posted a screenshot on Thursday of a paper of which ChatGPT is a co-author.
Source
But why, given that ChatGPT is a tool? “People are starting to treat ChatGPT as if it were a bona fide, well-credentialed scientific collaborator,” explains Gary Marcus in a Substack post. “Scientists, please don’t let your chatbots grow up to be co-authors,” he pleads.
More worrisome are those cases where there’s no disclosure of AI use. Scientists have found that they can’t reliably identify abstracts written by ChatGPT — its eloquent bullshit fools even experts in their field. As Sandra Wachter, who “studies technology and regulation” at Oxford, told Holly Else for a piece on Nature:
“If we’re now in a situation where the experts are not able to determine what’s true or not, we lose the middleman that we desperately need to guide us through complicated topics.”
ChatGPT’s challenge to education
ChatGPT has been banned in education centers all across the globe (e.g. New York public schools, Australian universities, and UK lecturers are thinking about it). As I argued in a previous essay, I don’t think this is the wisest decision but merely a reaction due to being unprepared for the fast development of generative AI.
NYT’s Kevin Roose argues that “[ChatGPT’s] potential as an educational tool outweighs its risks.” Terence Tao, the great mathematician, agrees: “In the long term, it seems futile to fight against this; perhaps what we as lecturers need to do is to move to an “open books, open AI” mode of examination.”
Giada Pistilli, the principal ethicist at Hugging Face, explains the challenge schools face with ChatGPT:
“Unfortunately, the educational system seems forced to adapt to these new technologies. I think it is understandable as a reaction, since not much has been done to anticipate, mitigate or elaborate alternative solutions to contour the possible resulting problems. Disruptive technologies often demand user education because they cannot simply be thrown at people uncontrollably.”
That last sentence captures perfectly where the problem arises and the potential solution lies. We have to make an extra effort to educate users on how this tech works and what’s possible and not to do with them. That’s the approach Catalonia has taken. As Francesc Bracero and Carina Farreras report for La Vanguardia:
“In Catalonia, the Department of Education is not going to prohibit it ‘in the entire system and for everyone, since this would be an ineffective measure.’ According to sources from the ministry, it is better to ask the centers to educate in the use of AI, ‘which can provide a lot of knowledge and advantages.’”
The student’s best friend: A database of ChatGPT errors
Gary Marcus and Ernest Davis have set up an “error tracker” to capture and classify the errors language models like ChatGPT make (here’s more info about why they’re compiling this document and what they plan to do with it).
The database is public and anyone can participate. It’s a great resource that allows for rigorous study of how these models misbehave and how people could avoid misuse. Here’s a hilarious example of why this matters:
Source
OpenAI is aware of this and wants to fight mis- and disinformation: “Forecasting Potential Misuses of Language Models for Disinformation Campaigns — and How to Reduce Risk.”
GPT-4 info and misinfo
New information
Sam Altman hinted at a delay in GPT-4’s release in a conversation with Connie Loizos, the silicon valley editor at TechCrunch. Altman said that “in general, we are going to release technology much more slowly than people would like. We’re going to sit on it for much longer…” This is my take:
Source
(Altman also said there’s a video model in the works!)
Misinformation about GPT-4
There is a “GPT-4 = 100T” claim going viral everywhere on social media (I’ve mostly seen it on Twitter and LinkedIn). In case you haven’t seen it, it looks like this:
Source
Or this:
Source
All are slightly different versions of the same thing: An appealing visual graph that captures attention, and a strong hook with the GPT-4/GPT-3 comparison (they use GPT-3 as a proxy for ChatGPT).
I think sharing rumors and speculations and framing them as such is okay (I feel partly responsible for this), but posting unverifiable info with an authoritative tone and without references is reprehensible.
People doing this aren’t far from being as useless and dangerous as ChatGPT as sources of information — and with much stronger incentives to keep doing it. Beware of this because it’ll pollute every channel of information about AI going forward.
More generative AI news
A robot lawyer
Joshua Browder, CEO at DoNotPay, posted this on Jan 9:
Source
As it couldn’t be otherwise, this bold claim generated a lot of debate to the point that Twitter now flags the tweet with a link to the Supreme Court page of prohibited items.
Even if they finally can’t do it due to legal reasons, it’s worth considering the question from an ethical and social standpoint. What happens if the AI system makes a serious mistake? Could people without access to a lawyer benefit from a mature version of this technology?
Litigation against Stable Diffusion has begun
Matthew Butterick published this on Jan 13:
“On behalf of three wonderful artist plaintiffs — Sarah Andersen, Kelly McKernan, and Karla Ortiz — we’ve filed a class-action lawsuit against Stability AI, DeviantArt, and Midjourney for their use of Stable Diffusion, a 21st-century collage tool that remixes the copyrighted works of millions of artists whose work was used as training data.”
It begins — the first steps in what promises to be a long fight to moderate the training and use of generative AI. I agree with the motivation: “AI needs to be fair & ethical for everyone.”
But, like many others, I’ve found inaccuracies in the blog post. It goes deep into the technicalities of Stable Diffusion but fails to explain correctly some bits. Whether this is intentional as a means to bridge the technical gap for people who don’t know — and don’t have the time to learn — about how this technology works (or as a means to characterize the tech in a way that benefits them) or a mistake is open to speculation.
I argued in a previous article that right now the clash between AI art and traditional artists is strongly emotional. The responses to this lawsuit won’t be any different. We’ll have to wait for the judges to decide the outcome.
CNET publishing AI-generated articles
Futurism reported this a couple of weeks ago:
“CNET, a massively popular tech news outlet, has been quietly employing the help of “automation technology” — a stylistic euphemism for AI — on a new wave of financial explainer articles.”
Gael Breton, who first spotted this, wrote a deeper analysis on Friday. He explains that Google doesn’t seem to be hindering traffic to these posts. “Is AI content ok now?” he asks.
I find it CNET’s decision to fully disclose the use of AI in their articles a good precedent. How many people are publishing content right now using AI without disclosing it? However, the consequence is that people may lose their jobs if this works out (as I, and many others, predicted). It’s already happening:
Source
I fully agree with this Tweet from Santiago:
Source
RLHF for image generation
If reinforcement learning through human feedback works for language models, why not for text-to-image? That’s what PickaPic is trying to achieve.
The demo is for research purposes but could be an interesting addition to Stable Diffusion or DALL-E (Midjourney does something similar — they internally guide the model to output beautiful and artistic images).
A recipe to “make Siri/Alexa 10x better”
Recipes that mix different generative AI models to create some better than the sum of the parts:
Source
Alberto Romero is a freelance writer who focuses on tech and AI. He writes The Algorithmic Bridge, a newsletter that helps non-technical people make sense of news and events on AI. He's also a tech analyst at CambrianAI, where he specializes in large language models.
Original. Reposted with permission.