How to Build a Real-Time Recommendation Engine Using Graph Databases
"You may also like" is a simple phrase that implies a new era in the way businesses interact and connect with their customers, and graph databases can easily help to build recommendation engines.
“This is for you”, “Suggested for you”, or “You may also like”, are phrases that have become essential in most digital businesses, particularly in e-commerce, or streaming platforms.
Although they may seem like a simple concept, they imply a new era in the way businesses interact and connect with their customers: the era of recommendations.
Let’s be honest, most of us, if not all of us, have been carried away by Netflix recommendations while looking for what to watch, or headed straight for the recommendations section on Amazon to see what to buy next.
In this article, I’m going to explain how a Real-Time Recommendation Engine can be built using Graph databases.
What is a Recommendation Engine?
A recommendation engine is a toolkit that applies advanced data filtering and predictive analysis to anticipate and predict customers’ needs and wants, i.e. which content, products, or services a customer is likely to consume or engage with.
For getting these recommendations, the engines use the combination of the following information:
- The customer’s past behaviors and history, e.g. purchased products or watched series.
- The customer’s current behaviors and relationships with other customers.
- The product’s ranking by customers.
- The business’ best sellers.
- The behaviors and history of similar or related customers.
What is a Graph database?
A Graph database is a NoSQL database where the data is stored in graph structures instead of tables or documents. A graph data structure consists of nodes that can be connected by relationships. Both nodes and relationships can have their own properties (key-value pairs), which further describe them.
The following image introduces the basic concepts of the graph data structure:
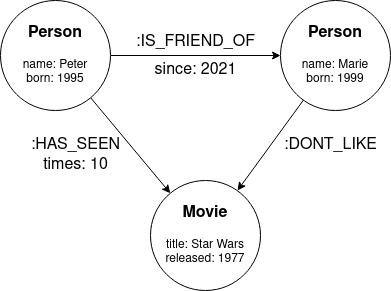
Example of a graph data structure
Real-Time Recommendation Engine for Streaming Platforms
Now that we know what are a recommendation engine and a graph database, we’re ready to get into how we can build a recommendation engine using graph databases for a streaming platform.
The graph below stores the movies two customers have seen and the relationship between the two customers.
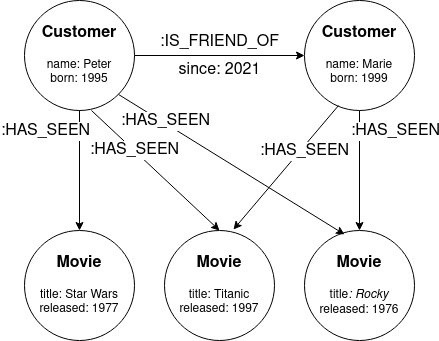
Example of a graph of the streaming platform.
Having this information stored as a graph, we can now think about movie recommendations to influence the next movie to watch. The simplest strategy is to show the most viewed movies on the entire platform. This can be easy using Cypher query language:
MATCH (:Customer)-[:HAS_SEEN]->(movie:Movie)
RETURN movie, count(movie)
ORDER BY count(movie) DESC LIMIT 5
However, this query is very generalist and does not take into account the context of the customer, so it’s not optimized for any given customer. We can do it much better using the social network of the customer, querying for friends and friends-of-friends relationships. With Cypher is very straightforward:
MATCH (customer:Customer {name:'Marie'})
<-[:IS_FRIEND_OF*1..2]-(friend:Customer)
WHERE customer <> friend
WITH DISTINCT friend
MATCH (friend)-[:HAS_SEEN]->(movie:Movie)
RETURN movie, count(movie)
ORDER BY count(movie) DESC LIMIT 5
This query has two parts divided by WITH clause, which allows us to pipe the results from the first part into the second.
With the first part of the query, we find the current customer ({name: 'Marie'}) and traverse the graph matching for either Marie’s direct friends or their friends (her friend-of-friends) using the flexible path-length notation -[:IS_FRIEND_OF*1..2]-> which means one or two IS_FRIEND_OF relationships deep.
We take care not to include Marie herself in the results (the WHERE clause) and not to get duplicate friends-of-friends that are also direct (the DISTINCT clause).
The second half of the query is the same as the simplest query, but now instead of taking into account all the customers on the platform, we are taking into account Marie’s friends and friends-of-friends.
And that’s it, we have just built our real-time recommendation engine for a streaming platform.
Wrapping up
In this article, the following topics have been seen:
- What a recommendation engine is and the amount of information it uses to make recommendations.
- What a graph database is and how the data is stored as a graph instead of a table or document.
- An example of how we can build a real-time recommendation engine for streaming platforms using graph databases.
José María Sánchez Salas is living in Norway. He is a freelance data engineer from Murcia (Spain). In the middle of business and development worlds, he also write a data engineering newsletter.