A Beginner’s Guide to Q Learning
Learn the basics of Q-learning in this article, a model-free reinforcement learning algorithm.

Alexander Andrews via Unsplash
In order for you to understand what Q learning is, you need some knowledge of Reinforcement Learning.
Reinforcement Learning branches from Machine Learning, it aims to train a model that returns an optimum solution using a sequence of solutions that have been created for a specific problem.
The model will have a variety of solutions and when it chooses the right one, a reward signal is generated. If the model performs closer to the goal, a positive reward is generated; however, if the model performs further away from the goal, a negative reward is generated.
Reinforcement Learning consists of two types of algorithms
- Model-free: This excludes the dynamics of the environment to estimate the optimal policy
- Model-based: This includes the dynamics of the environment to estimate the optimal policy.
What is Q-Learning?
Q-Learning is a model-free reinforcement learning algorithm. It tries to find the next best action that can maximize the reward, randomly. The algorithm updates the value function based on an equation, making it a value-based learning algorithm.
It’s like when you’re trying to find a solution to your current situation, to ensure you reap maximum benefits. The model can generate its own rules and even operate outside of the policy provided. Implying that there is no need for a policy, making it an off-policy learner.
An off-policy learner is when the model learns the value of the optimal policy regardless of the agent’s actions. An on-policy learner is when the model learns the value of the policy carried out by the agent, finding an optimal policy.
Let’s look at advertisements based on a recommendation system. Advertisements no-a-days are based on your search history or previous watches. However, Q-Learning can go a step further by optimizing the ad recommendation system to recommend products that are known to be frequently bought together. The reward signal is if the user purchases or clicks on the suggested product.
‘Q’ in Q-Learning stands for Quality. It represents how effective a given action is in gaining rewards.
Bellman Equation
The Bellman Equation was named after Richard E. Bellman who was known as the father of Dynamic programming. Dynamic Programming aims to simplify complex problems/tasks, by breaking them down into smaller problems and then solving these smaller problems recursively before attacking the larger problem.
The Bellman Equation determines the value of a particular state and comes to a conclusion on how valuable it is in that state. The Q-function uses the Bellman equation and uses two inputs: the state (s) and the action (a).
How do we know which action to take if we know all the expected rewards for every action? You can choose the sequence of actions that generate the best rewards which we can represent as the Q value. Using this equation:

- Q(s, a) stands for the Q Value that has been yielded at state ‘s’ and selecting action ‘a’.
- This is calculated by r(s, a) which stands for the immediate reward received + the best Q Value from state ‘s’.
 is the discount factor that controls and determines the importance to the current state
is the discount factor that controls and determines the importance to the current state
The equation consists of the current state, the learning rate, the discount factor, the reward linked to that particular state, and the maximum expected reward. These are used to find the next state of the agent.
What is a Q-table?
You can imagine the different paths and solutions that Q-learning provides. Therefore, in order to manage and determine which is the best, we use Q-table.
Q-table is just a simple lookup table. It is created so we can calculate as well as manage the maximum expected future rewards. We can easily identify the best action for each state in the environment. Using the Bellman Equation at each state, we get the expected future state and reward, then save it in a table to make comparisons to other states.
For example:
| State: | Action: | |||
 |
 |
 |
 |
|
| 0 | 0 | 1 | 0 | 0 |
| .. | ||||
| 250 | -2.07469 | -2.34655 | -1.99878 | -2.03458 |
| .. | ||||
| 500 | 11.47930 | 7.23467 | 13.47290 | 9.53478 |
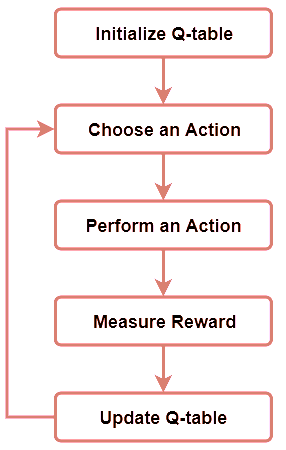
Q-learning Process
1. Initialize the Q-Table
The first step is creating the Q-table
- n = number of actions
- m = number of states
For example, n could be left, right, up, or down, whilst m could be start, idle, correct move, wrong move, and end in a game.
2. Choose and Perform an Action
Our Q-table should all have 0’s as no action has been performed. We then choose an action and update it in our Q-table in the correct section. This states that the action has been performed.
3. Calculate the Q-Value using Bellman Equation
Using the Bellman Equation, calculate the value of the actual reward and the Q-value for the action just performed.
4. Continue Steps 2 and 3
Repeat Steps 2 and 3 till an episode ends or the Q-table is filled.
Source: Authors image
Conclusion
This is a simple guide for beginners, if you want a better understanding of Q-learning and Reinforcement Learning, have a read of this book: Reinforcement Learning: An Introduction (2nd Edition) by Richard S. Sutton and Andrew G. Barto.
Nisha Arya is a Data Scientist and Freelance Technical Writer. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways Artificial Intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.