How to Auto-Detect the Date/Datetime Columns and Set Their Datatype When Reading a CSV File in Pandas
When read_csv( ) reads e.g. “2021-03-04” and “2021-03-04 21:37:01.123” as mere “object” datatypes, often you can simply auto-convert them all at once to true datetime datatypes.
By David B Rosen (PhD), Lead Data Scientist for Automated Credit Approval at IBM Global Financing
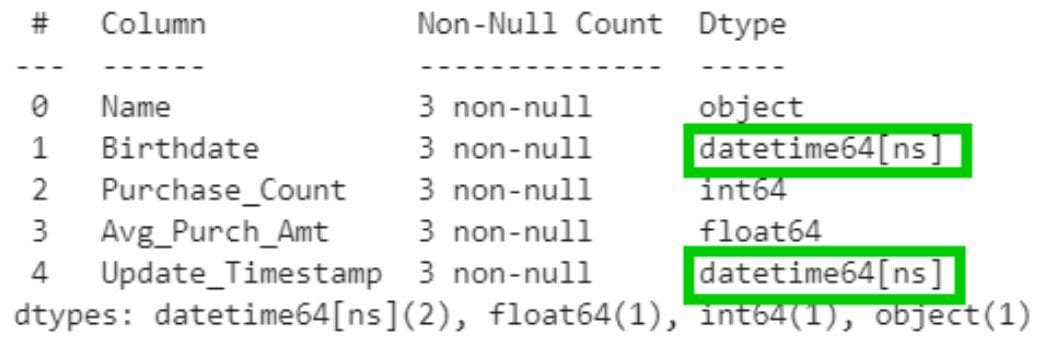
Say I have a CSV data file that I want to read into a Pandas dataframe, and some of its columns are dates or datetimes, but I don’t want to bother identifying/specifying the names of these columns in advance. Instead I would like to automatically obtain the datatypes shown in the df.info() output pictured above, where the appropriate columns have been automatically given a datetime datatype (green outline boxes). Here’s how to accomplish that:
from dt_auto import read_csv
df=read_csv('myfile.csv')
Note that I did not invoke pd.read_csv (the Pandas version of read_csv) above directly. My dt_auto.read_csv function (see its code down below) has invoked pd.read_csv() itself and then automatically detected and converted the datatype of the two detected datetime columns. (The contents of this df will be shown down below.)
If I had used the regular Pandas pd.read_csv(), I would have obtained merely generic object datatypes by default as below (red outline boxes):
from pandas import read_csv
df=read_csv('myfile.csv')
df.info()
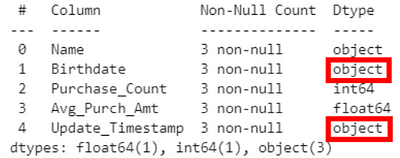
Note that the only difference from the original code is in the import statement, where I changed “from dt_auto” to “from pandas”. This is sufficient so long as you use only “=read_csv()” throughout, not qualifying it as as “=pd.read_csv()” or “=dt_auto.read_csv()”.
Here is the contents of my dt_auto.py (“datetime automatic”):
import pandas as pd
def dt_inplace(df):
"""Automatically detect and convert (in place!) each
dataframe column of datatype 'object' to a datetime just
when ALL of its non-NaN values can be successfully parsed
by pd.to_datetime(). Also returns a ref. to df for
convenient use in an expression.
"""
from pandas.errors import ParserError
for c in df.columns[df.dtypes=='object']: #don't cnvt num
try:
df[c]=pd.to_datetime(df[c])
except (ParserError,ValueError): #Can't cnvrt some
pass # ...so leave whole column as-is unconverted
return df
def read_csv(*args, **kwargs):
"""Drop-in replacement for Pandas pd.read_csv. It invokes
pd.read_csv() (passing its arguments) and then auto-
matically detects and converts each column whose datatype
is 'object' to a datetime just when ALL of the column's
non-NaN values can be successfully parsed by
pd.to_datetime(), and returns the resulting dataframe.
"""
return dt_inplace(pd.read_csv(*args, **kwargs))
But isn’t this risky? What if one of the columns wasn’t entirely a datetime column? Of course you could have some obscure strings that just happen to look like dates but aren’t, but there is not much risk that this code will blindly convert or lose non-datetime strings, for two reasons:
- This code will not convert any values in a column unless every non-NaN value in this column can successfully be parsed by pd.to_datetime and converted to a datetime. In other words, we will not let it ever convert a string to a pd.NaT (the “failure” result) because it can’t understand it as a datetime.
- It will not attempt to convert columns that have already been interpreted as being any type other than object, i.e. any specific type like int64 or float64, even though pd.to_datetime would have happily (but likely undesirably) converted a number like 2000 to the date 2000-01-01.
In my experience so far, the dt_auto.read_csv function does not take long to run on a typical dataframe. Even if there are a lot of non-datetime object (string) columns, it almost always very quickly encounters a value near the top of each such column that it can’t parse as a datetime and gives up and moves on to the next column without attempting to parse the rest of the column’s values.
Here’s what the resulting dataframe looks like from dt_auto.read_csv(), although you can’t necessarily tell by looking at it that the two appropriate columns are indeed datetime datatypes. As it happens, the CSV file had a varying number of decimal places (three, none, and nine) for the seconds in Update_Timestamp, but the datetime datatype itself shows nine such digits regardless. Birthdate in the csv file in fact had only dates (no times) but was stored as a full datetime, with zeros for the hours, minutes, and seconds (including zero as the decimal part), but all of the time components in the column being zero causes Pandas to display only the date (year-month-day) for this column.

Of course pd.to_datetime, and thus dt_auto.read_csv, cannot handle all possible date and datetime formats by default, but it will handle many common unambiguous (generally year month day) formats such as those written by the dataframe.to_csv method and many other tools, including many ISO datetime formats (which generally have a “T” separating the date from the time rather than a space). I haven’t experimented with datetimes that include timezone info because I don’t usually see data like that, but do please let me know in a response comment whether these could be handled better by further changes to the code.
What do you think? Did you find this little article useful? And should Pandas itself add (e.g. to the pd.read_csv function itself?) the capability to optionally do this for us so you wouldn’t need to copy/import my dt_auto.py code above? I’d be happy to see your comments and questions as responses here.
Thanks to Elliot Gunn.
Bio: David B Rosen (PhD) is Lead Data Scientist for Automated Credit Approval at IBM Global Financing. Find more of David's writing at dabruro.medium.com.
Original. Reposted with permission.
Related:
- 5 Python Data Processing Tips & Code Snippets
- CSV Files for Storage? No Thanks. There’s a Better Option
- How to Query Your Pandas Dataframe