Analyzing the Probability of Future Success with Intelligence Node’s Attributes Evolution Model
The analytics team at Intelligence Node have been working on developing a Limited Memory model (which first started as a Reactive model) aka the 'The Probability of Future Success' model. This model explores a new market driven approach to identifying future trends and probability of success for specific product attributes based on a series of dynamic metrics and attributes. Read this article to know more.
The age of fast-fashion and the evolving consumer buying trends have made it a lot more challenging and complicated for brands to predict future buying behavior and source products that are likely to be in demand. Intelligence Node’s access to immense online and competitor data and proprietary AI analytics puts it at an advantage to understand trends based on more than one factor and analyze this data to forecast the probability of future success based on historical data and product attributes.
In the article, we will shed light on the Probability of Future Success Model built by the analytics team at Intelligence Node.
The Probability of Future Success Model was developed as a Reactive model that has evolved into a Limited Memory model. Considering the application of the model and if and when ‘Theory of Mind’ systems are more advanced, we can transition and make the forecasts ‘aware of the variables that can actually influence feelings and behaviors’. We can start looking at the retail marketplace (that can be further segmented into groups) as an individual(s) with its own feelings and tantrums…the ‘Mr. Market’ allegory created by Benjamin Graham comes to mind.
A Deep Dive into the Probability of Future Success Model
Intelligence Node’s Probability of Future Success model runs on 4 key steps. Each step is critical to produce data that can together be used to infer the level of probable success a product will see in the next 6 to 12 months based on the historic behavior of certain attributes.
Methodology
Step 1: Analyze historical data
- The evolution of a trend/attribute can have multiple possible outcomes. By analyzing the historical data, we can estimate the probability of future success.
Step 2: Track established and emerging product attributes
- Attributes can be library-driven (established) or machine-driven (emerging). Tracking the attribute performance over a time period can help us understand probability of their future progress
Step 3: Evaluate the performance of key metrics
- For every trend/attribute, we evaluate the share of shelf, time rank and power rank (sub components include review velocity, sales velocity, product visibility, product lifecycle dynamics, etc)
Step 4: Analyze probability of future success
- Based on historical review overlaid with current market dynamics of the signal KPIs, we can identify trends/attributes that have a high probability of success in the future
Step 1 : Analyze Historical Data
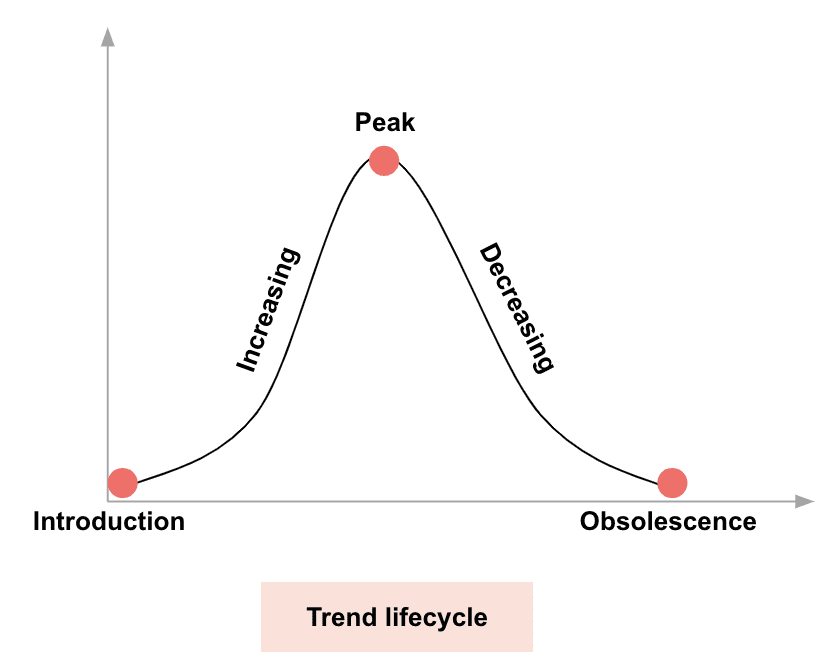
Historical data is a key factor in being able to determine the future trends and success probability for a product. By understanding how a product has performed in the past, where it is in the product life cycle and how it was received by the audience can lead to insights on its future success (and future success of emerging trends that are similar) if combined with other key determining factors. The evolution of a trend/attribute can have multiple possible outcomes and analyzing historical data can help estimate future success probability for various instances.
Step 2: Track established and emerging product attributes
We can identify market trends by analyzing machine driven attributes (and similar keywords). Let us take the example of ‘Recycled Jeans’ keyword below and understand how we use machine driven approach to identifying similar keywords/attributes:
Step 1 : Mining product copy for keywords
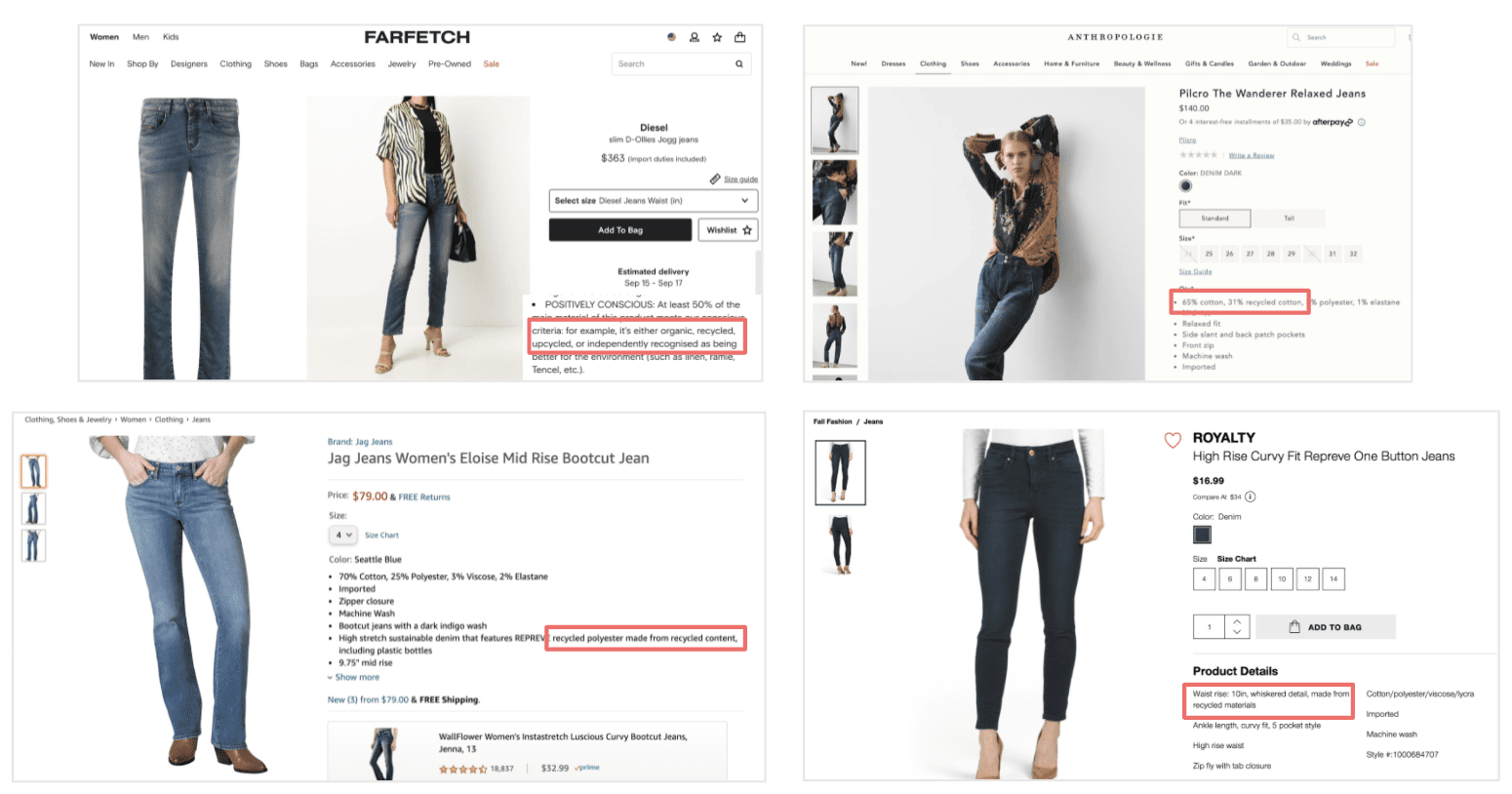
We capture the recurring keywords from product name/description across all competitor domains using our comprehensive attributes libraries (computer vision is deployed as well for maximum coverage).
Step 2: Filtering out attribute values
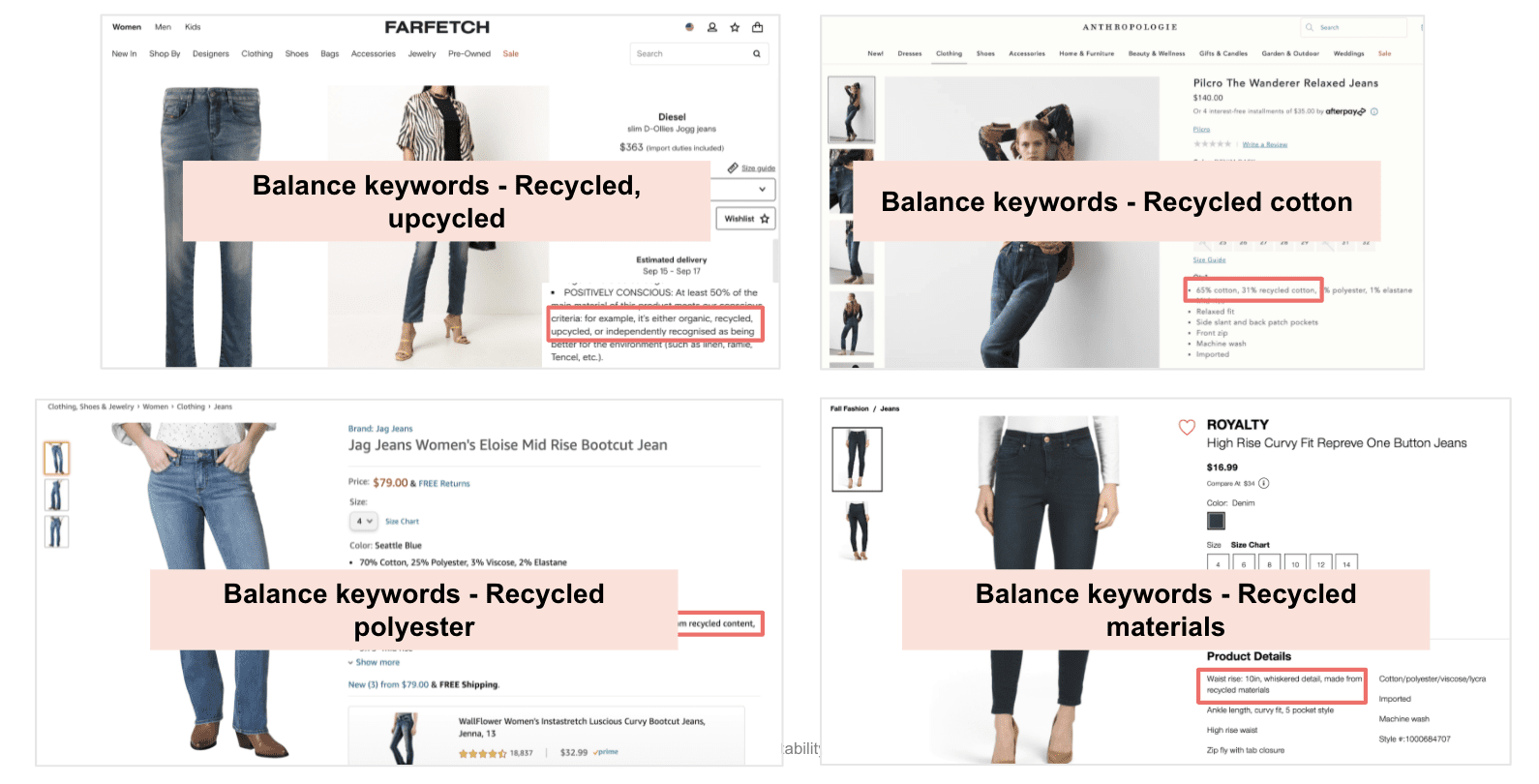
We filter out the existing attribute values from the attribute library and analyze the balance keywords (Transformer models are deployed + custom implementation of BERT extracts sentence vectors and uses them to train a fully connected feedforward NN).
Step 3: Running zero shot clustering on balance keywords
We run a custom zero shot clustering model (the model is programmed to recognize and adjust to its internal biases) to create “logical” clusters.

Step 4: Identifying similar keywords/attributes

Additionally, the model (custom developed NN measuring context similarity) looks for similar keywords that might revolve around the initial theme identified by the clustering e.g. environmental consciousness.
Step 3: Evaluate the performance of key metrics
Evaluating key metrics is one of the most important steps in the Probability of Future Success model. In this step, we analyze metrics like share of shelf, time rank, and power rank to comprehensively evaluate the performance of a product and infer the probability of its future success:

Share of shelf: Tracking the share of an attribute in comparison to the overall data
“Share of digital shelf” is the percentage visibility a product gets from a keyword/attribute inquiry.
Example:

Power rank: An important criterion pulling in a joint score of signal KPIs such as:
a. Customer reaction (number and velocity of product reviews and ratings)
We track this KPI by calculating the total count of customer reviews on the website along with the velocity of these reviews (how recently these reviews were posted) to analyze the customer sentiment at an attribute level.
Example:
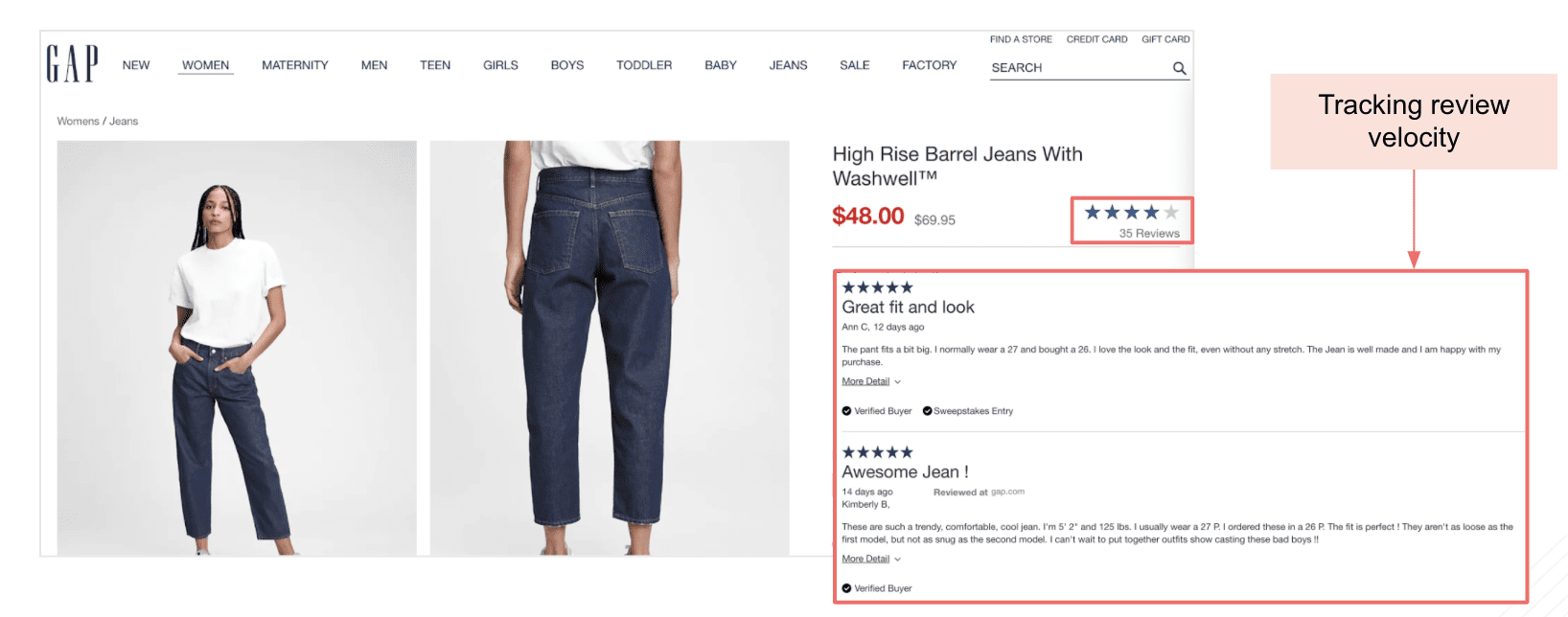
In the above example, we track the number of reviews and review velocity for GAP’s high rise barrel jeans.
b. Customer action (tracking sales velocity and product visibility across domains)
Our “smart recipe scraping” algorithms can track sales velocity by scraping inventory count from multiple sources including product page, shopping cart, Amazon buy box, etc. and analyzing the frequency at which the inventory levels are depleting over a certain period.
Example:

c. Customer discoverability (tracking product searchability and popularity using the search algorithm of the target competitor domain)
From a searchability perspective, we track the first 100 products on competitor domains and analyze the share of every attribute.
Example:

For instance “mom jeans” accounts for 26% of the first 100 products listed on H&M.
We also track weekly/monthly popularity of an attribute on Google trends. This data is a direct reflection of ‘actual search interest’ across the defined region.
d. Product Lifecycle
We can analyze product lifecycle dynamics by tracking key product activities at an attribute level such as product promotions, discount ratio, product affinity, product availability, rate of replenishment, average span of product stock outs, etc.
Example:

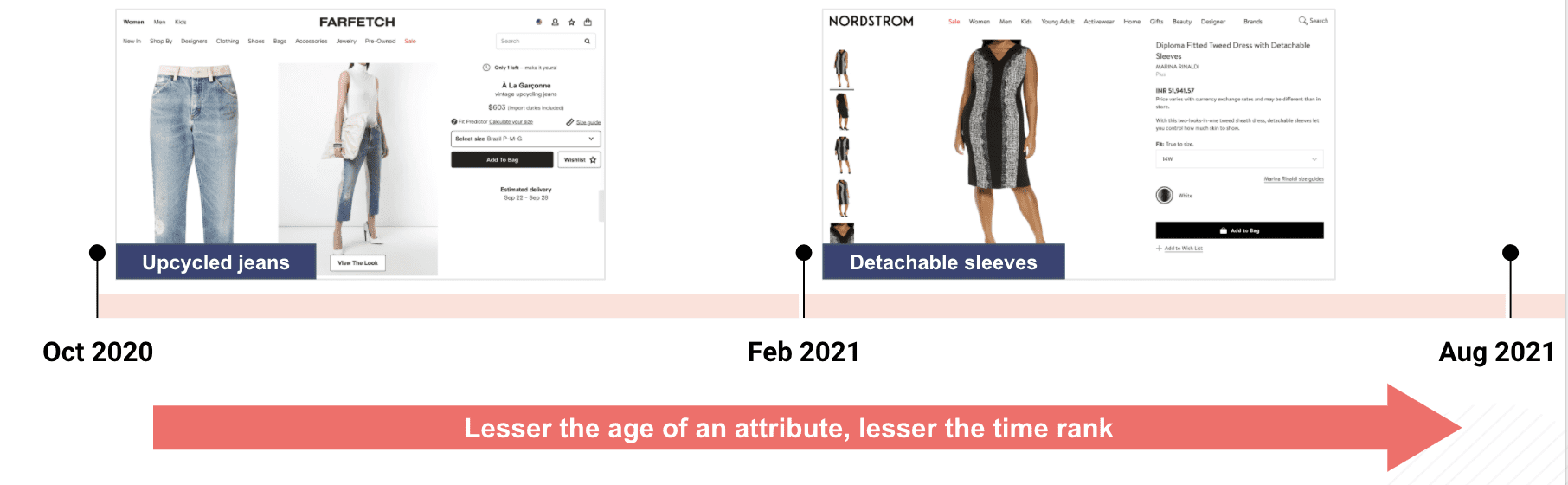
3. Time rank: Tracking the age of an attribute
We can track the age (time since inception) for every attribute. This can help in identifying new trends at an early stage, and also shed light on declining trends in the market.
Example
Step 4: Analyzing Probability of Future Success
Based on historical performance of all the metrics covered in step 3, we can identify trends/attributes that have a high probability of success in the future or are likely to go out of trend. With this analysis, manufacturers and brands can plan 6-12 months in advance on what products should be manufactured or ordered, what SKUs to stock up or invest in and what products can be discontinued to optimize inventory storage and warehousing, save costs and overheads and cater to the consumer demand in a planned and data-driven fashion.

In the above example, we have analyzed the performance of the key metrics for ‘straight fit jeans’ over the past 24 months. By applying our analytical approach, we can predict the probability of success for straight fit jeans months into the future.
Questions Data Analytics Answers for Retail Businesses
A data-driven approach to retail decision making, like the Probability of Future Success model explained in this article, is a new market driven approach to identifying future trends and probability of success for specific product attributes based on a series of pre-configured metrics and attributes. It answers many principal questions surrounding key business areas based on reliable real-time and historical data, in-depth data analysis, intuitive intelligence, and market and consumer trends. Let us look at some of the questions that the Probability of Future Success model helps answer:
- What new trends should I onboard?
- How should I calibrate established trends to maximize my chances of success?
- Are the established trends increasing in power?
- Are the established trends decreasing in power?
Final Word: Data-driven Analytics for the Future of Retail
The pace at which retail and consumer preferences are evolving today has made it essential for retail businesses to harness the power of advanced retail technology and AI analytics. The success of retail businesses will largely depend on how effective they are in harnessing data as a strategic decision-making tool. Leveraging advanced analytics will help retailers derive insights to identify future trends and consumer preferences for future-proofing retail businesses and making data-driven decisions that will positively impact future outcomes. This is exactly what Intelligence Node’s latest Probability of Future Success Model aims to offer to the retail ecosystem. It is a solution that will empower brands, retailers, and manufacturers with actionable insights into the probable future by analyzing and deriving insights from vast amounts of data, parameters, and attributes - enabling them to make manufacturing, sourcing, pricing, and assortment decisions with precision.
Yasen Dimitrov is Co-founder & Chief Analytics Officer at Intelligence Node, a retail intelligence platform delivering 99% data accuracy with patented AI.