 Deep Learning Research Review: Natural Language Processing
Deep Learning Research Review: Natural Language Processing
 Deep Learning Research Review: Natural Language Processing
Deep Learning Research Review: Natural Language ProcessingThis edition of Deep Learning Research Review explains recent research papers in Natural Language Processing (NLP). If you don't have the time to read the top papers yourself, or need an overview of NLP with Deep Learning, this post is for you.
Memory Networks
Introduction
The first paper, we’re going to talk about is a quite influential publication in the subfield of Question Answering. Authored by Jason Weston, Sumit Chopra, and Antoine Bordes, this paper introduced a class of models called memory networks.
The intuitive idea is that in order to accurately answer a question regarding a piece of text, you need to somehow store the initial information given to you. If I were to ask you the question “What does RNN stand for”, (assuming you’ve read this post fully J) you’ll be able to give me an answer because the information you absorbed by reading the first part of this post was stored somewhere in your memory. You just had to take a few seconds to locate that info and articulate it in words. Now, I have no clue how the brain is able to do that, but the idea of having a storage place for this information still remains.
The memory network described in the paper is unique because it has an associative memory that it is able to read and write to. It’s interesting to note that we don’t have this type of memory with CNNs or with Q-Networks (for reinforcement learning) or with traditional neural nets. This is in part because the task of question answering relies so heavily upon being able to model or keep track of long-term dependencies, such as keeping track of the characters in a story or a timeline of events. With CNNs and Q-Networks, “memory” is sort of built into the weights of the network as it learns different filters or mappings from states to actions. At first look, RNNs and LSTMs could be used, but these typically aren’t able to remember or memorize inputs from the past (which in question answering is quite critical).
Network Architecture
Okay, so now let’s look at how this network processes the initial text it is given. Like with most machine learning algorithms, the first step is to convert the input into a feature representation. This could entail using word vectors, part of speech labeling, parsing, etc. It’s really just up to the programmer.
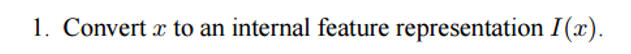
The next step would be taking the feature representation I(x) and allowing our memory m to be updated to reflect the new input x we’ve received.
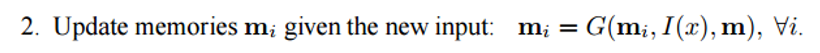
You can consider the memory m to be a sort of an array that is made up of individual memories mi. Each of these individual memories mi can be a function of the memory m as a whole, the feature representation I(x), and/or itself. This function G can be as simple as just storing the whole representation I(x) in the individual memory unit mi. You can modify this function G to update past memories based on new input. The 3rd and 4th steps involve reading from memory, based on the question, to get a feature representation o, and then decoding it to output a final answer r.

The function R could be an RNN that is used to convert the feature representations from memory into a readable and accurate answer to the question.
Now, let’s look at step 3 a little closer. We want this O module to output a feature representation that would best match a possible answer to our given question x. Now this question is going to be compared to every single individual memory unit and is going to be “scored” based on how well the memory unit supports the question.
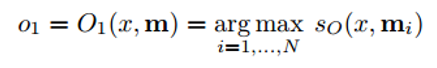
We take the argmax of the scoring function to find the output representation that best supports the question (You can also take multiple of the highest scoring units, doesn’t have to be limited to 1). The scoring function is one that computes the matrix product between different embeddings of the question and the chosen memory unit[s] (check paper for more details). You can think of this as when you multiply the word vectors of two words in order to find their similarity. This output representation o is then fed into an RNN or LSTM or another scoring function which will output a readable answer.
This network is trained in a supervised manner where training data includes the original text, the question, supporting sentences, and the ground truth answer. Here is the objective function.
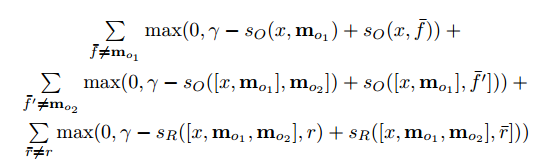
For those interested, these are some papers that built off of this memory network approach
- End to End Memory Networks (only requires supervision on outputs, not supporting sentences)
- Dynamic Memory Networks
- Dynamic Coattention Networks (Just got released 2 months ago and had the highest test score on Stanford’s Question Answering Dataset at the time)
Tree LSTMs for Sentiment Analysis
Introduction
The next paper looks into an advancement in Sentiment Analysis, the task of determining whether a phrase has a positive or negative connotation/meaning. More formally, sentiment can be defined as “a view or attitude toward a situation or event”. At the time, LSTMs were the most commonly used units in sentiment analysis networks. Authored by Kai Sheng Tai, Richard Socher, and Christopher Manning, this paper introduces a novel way of chaining together LSTMs in a non-linear structure.
The motivation behind this non-linear arrangement lies in the notion that natural language exhibits the property that words in sequence become phrases. These phrases, depending on the order of the words, can hold different meanings from their original word components. In order to represent this characteristic, a network of LSTM units must be arranged into a tree structure where different units are affected by their children nodes.
Network Architecture
One of the differences between a Tree-LSTM and a standard one is that the hidden state of the latter is a function of the current input and the hidden state at the previous time step. However, with a Tree-LSTM, its hidden state is a function of the current input and the hidden states of its child units.
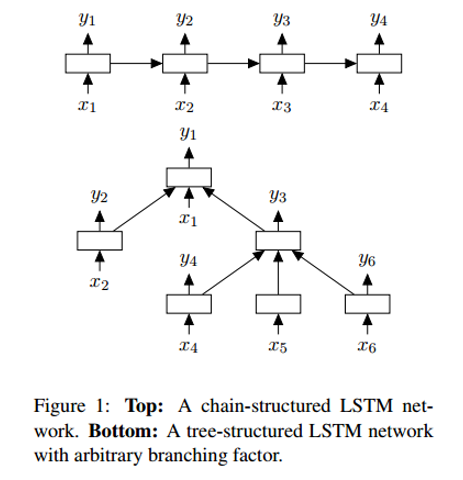
With this new tree-based structure, there are some mathematical changes including child units having forget gates. For those interested in the details, check the paper for more info. What I would like to focus on, however, is understanding why these models work better than a linear LSTM.
With a Tree-LSTM, a single unit is able to incorporate the hidden states of all of its children nodes. This is interesting because a unit is able to value each of its children nodes differently. During training, the network could realize that a specific word (maybe the word “not” or “very” in sentiment analysis) is extremely important to the overall sentiment of the sentence. The ability to value that node higher provides a lot of flexibility to network and could improve performance.
Neural Machine Translation
Introduction
The last paper we’ll look at today describes an approach to the task of Machine Translation. Authored by Google ML visionaries Jeff Dean, Greg Corrado, Orial Vinyals, and others, this paper introduced a machine translation system that serves as the backbone behind Google’s popular Translate service. The system reduced translation errors by an average of 60% compared to the previous production system Google used.
Traditional approaches to automated translation include variants of phrase-based matching. This approach required large amounts of linguistic domain knowledge and ultimately its design proved to be too brittle and lacked generalization ability. One of the problems with the traditional approach was that it would try to translate the input sentence piece by piece. It turns out the more effective approach (that NMT uses) is to translate the whole sentence at a time, thus allowing for a broader context and a more natural rearrangement of words.
Network Architecture
The authors in this paper introduce a deep LSTM network that can be trained end to end with 8 encoder and decoder layers. We can separate the system into 3 components, the encoder RNN, decoder RNN, and attention module. From a high level, the encoder works on the task on transforming the input sentence to vector representation, the decoder produces the output representation, and then the attention module tells the decoder what to focus on during the task of decoding (This is where the idea of utilizing the whole context of the sentence comes in).
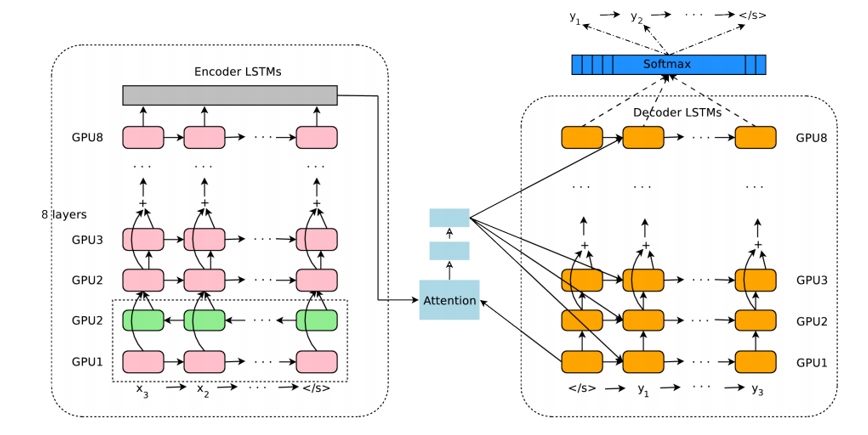
The rest of the paper mainly focuses on the challenges associated with deploying such a service at scale. Topics such as amount of computational resources, latency, and high volume deployment are discussed at length.
Conclusion
With that, we conclude this post on how deep learning can contribute to natural language processing tasks. In my mind, some future goals in the field could be to improve customer service chatbots, perfect machine translation, and hopefully get question answering systems to obtain a deeper understanding of unstructured or lengthy pieces of text (like Wikipedia pages).
Special thanks to Richard Socher and the staff behind Stanford CS 224D. Great slides (most of the images are attributed to their slides) and fantastic lectures.
Bio: Adit Deshpande is currently a second year undergraduate student majoring in computer science and minoring in Bioinformatics at UCLA. He is passionate about applying his knowledge of machine learning and computer vision to areas in healthcare where better solutions can be engineered for doctors and patients.
Original. Reposted with permission.
Related: