What 2 years of self-teaching data science taught me
Many of us self-learn data science from the very beginning. While continuing to self-learn on demand is crucial, especially after you become a professional, there can be many pitfalls early on for learning the wrong way or missing out on key ideas that are important for the real-world application of data science.
By Vishnu U, Campus Mind Trainee at Mindtree | Exploring Data Science.
Data Science enthusiasts are often self-taught at first instead of a master's degree taken later on. But, the reality of the vast field of Data Science is realized later on by beginners in the field, and the really valuable time is spent in the wrong way of learning. In this article, I will share few facts I learned through my journey of learning data science over the course of 2 years, which could help you learn in a better way.
Data Science is an Ocean

Keep Learning — There is no end to this field! (Image source).
Before you get started, get to know the fact that Data Science is a very vast field. Never expect to complete learning in a few months or by doing online courses. Research and development happen quite frequently, so be ready for a long time of learning. Also, do understand the fact that real-world data science is quite different from what we do by ourselves, but keep what you learn in memory.
You need not be an Einstein, but little math won’t hurt

Basic math is essential (Image source).
This is a common statement, but I felt a little math (the basics of probability, calculus, statistics, and linear algebra) is good. You do not necessarily need to go very deep into the subjects, but the basic understanding will be a great plus point when solving data problems. The majority of the workload from math calculations is done by libraries.
Save Machine Learning for later
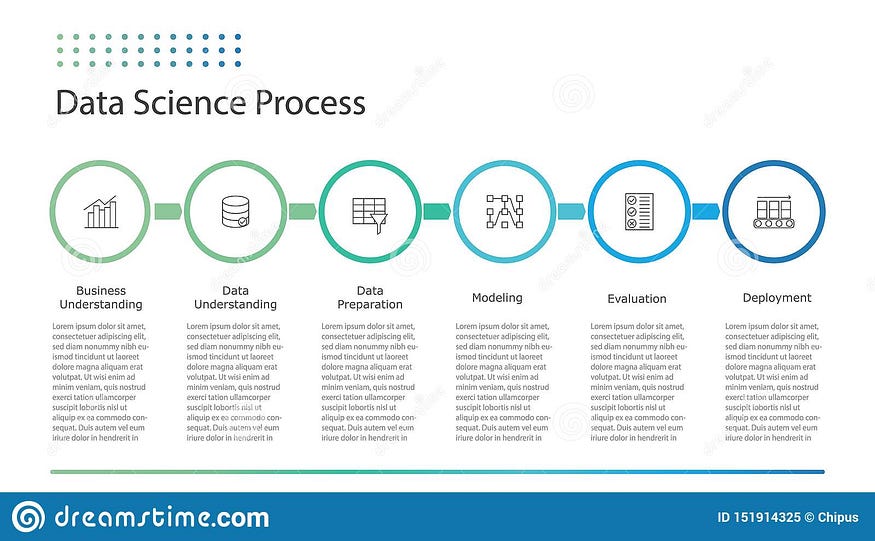
Data Science Process — Observe that collection and prepping of the correct data is essential (Image source).
The most common mistake is jumping directly into machine learning, kick-starting the learning from there, only in the reverse way. Machine learning is the last part of any data science process. Starting your learning from here will make you miss out on a lot of more important concepts — data loading and management, exploratory analysis, and data engineering. Start by learning Python, lading data, and working with datasets (pandas), then move on to generating dashboards and visualizations, and then move on to Machine Learning and predictive modelling. This article explains the general data science process.
Kaggle is the best place, but keep this in mind

Kaggle is a holy place for Data Science Enthusiasts — but always start with the basics (Image source).
Once you get your basics done, you can start working on projects on Kaggle. Kaggle is the site where you can find datasets — you can use that and work on Data Science skills. But do keep one thing in mind: if you are a beginner, start working on basic and small datasets with simpler tasks, and then move on to competitions. The reason is that Kaggle is a public platform where you may find industry experts and researchers. Their level of knowledge will be different from what you have as a rookie — so work on your own by starting with basic datasets and then moving on to complex modelling problems or competitions.
Stop comparing, start learning

Comparing brings in the infamous Imposter Syndrome — but it is just an illusion that you mind plays (Image source).
One of the most common mistakes that newbies make is to compare their work with others. This is a big mistake because of the difference in the level of experience and knowledge. Instead, think the other way around: try to learn what they have done if it is within the level of your understanding. Every one of the people who has the best works out there was once a beginner like you.
Welcome the skill of “understanding the business problem”

Problem-solving is a vital skill (Image source).
{kind=link}
All Data Science problems focus on solving a problem — in the real world or business. Moreover, understanding the business problem is often termed as “The first rule of Data Science.” The best advice out there is to work on datasets and projects that solve a problem rather than generating visualizations and models. The “Cats vs. Dogs” dataset is all good for learning and trying out things but not as a project or work.
It is not a CSV file every time, there are others too
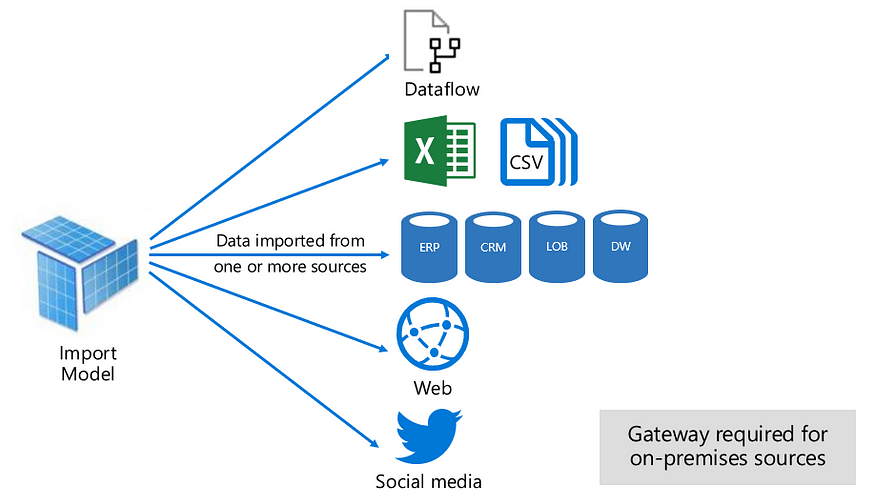
Data in the real world exists in many forms — get to know them to be a good Data Scientist (Image source).
For beginners, it is best to start with data in CSV file, but as you get used to it, learn to use other data sources as well: text files with RegExp, SQL databases, data warehouses with cloud interfacing, unstructured data (image and audio files), JSON data, etc. As you get used to the basic data sources, you can try out data scraping as well. You may have a read through this article as well.
Jack of all, master of none — it applies here

Learn to build things on-demand — do not expect to learn everything in a short time (Image source).
Data Science requires you to use a variety of libraries, tools, and APIs but you necessarily need not be a master in it (a good thing if you are). The main idea here is to have an idea of the concepts but not necessarily to know the complete library or API! Learn what is necessary on-demand.
Get used to Cloud Platforms
Cloud is a different field but comes in handy for many large-scale data science problems (Image source).
Cloud often comes in combination with Data Science problems either because of the large resource requirements or the solution can be deployed on the cloud itself. Get to know cloud platforms, various services, and their usage. The cloud also hosts various services for Big Data storage and management, which the field of Data Science revolves around.
Original. Reposted with permission.
Related: