
16 Essential DVC Commands for Data Science
Learn essential DVC commands to version large datasets and track and manage the machine learning experiments.

Image by Author
DVC (Data Version Control) is a useful tool to track data and machine learning models, pipelines, and experiments. It works seamlessly with Git to provide code and data versioning environments.
The DVC commands are similar to Git, and apart from version control, it provides a rich environment for training, validating, and deploying machine learning models. Similar to Git, you can share and collaborate on machine learning projects.
In this post, we will learn about essential commands used to initialize, manage, and share DVC projects.
The overview of 16 essential commands:
- init
- remote
- add
- remove
- status
- commit
- checkout
- push
- pull
- run
- exp
- repro
- metrics
- plots
- dag
- gc
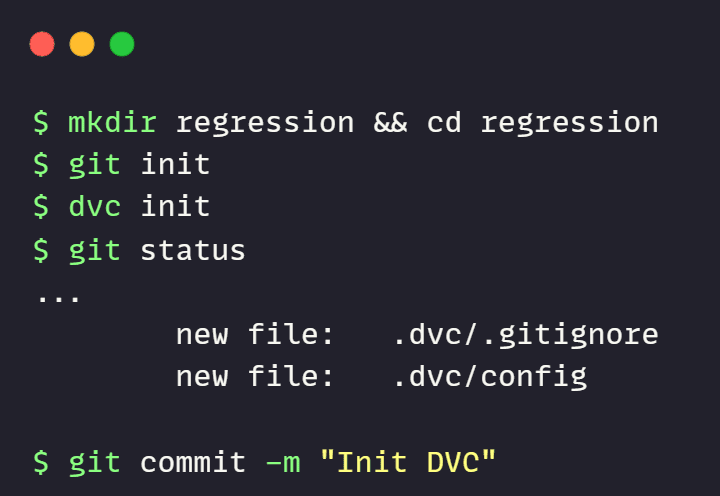
1. init
DVC initialization is dependent on Git. If you are in a new directory, first initialize the Git and then initialize DVC as shown below.
git init dvc init
The init command has created a .dvc directory. It consists of all metadata related to your DVC configuration and files.
2. remote
DVC remote command is used to share the data with a team or create a copy in remote storage.
Simply add a remote name and remote URL. As I told you early, the command is fairly similar to Git.
dvc remote add dagshub https://dagshub.com/kingabzpro/Urdu-ASR-SOTA.dvc
To view the list of remote storage, use:
dvc remote list >>> dagshub https://dagshub.com/kingabzpro/Urdu-ASR-SOTA.dvc
To modify your existing remote. You can use the command below. It requires a remote name and a new URL.
dvc remote modify dagshub https://dagshub.com/kingabzpro/solar-radiation-ISB-MLOps.dvc
You can rename or remove the remote using the above pattern. It is relatively easy.
3. add
Use this command to track single or multiple files and directories.
dvc add ./model ./data
When you add files to DVC, the command will remove it from Git using .gitignore. Instead, Git will track pointers with .dvc to track and commit the changes.
After running the add command, you have to add the file to the Git staging area.
git add model.dvc data.dvc .gitignore
4. remove
To stop tracking files and directories use the `dvc remove <file>` command. Make sure the directory or file has an extension .dvc. You can also use it to remove a stage from dvc.yml.
dvc remove model.dvc
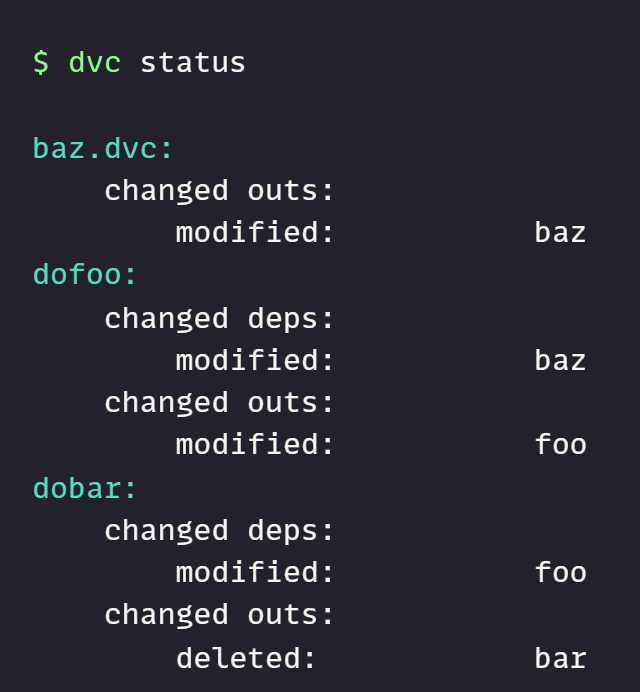
5. status
It will display the changes in the project pipelines and showcase changes between cache and workspace or remote storage.
dvc status
6. commit
The commit command is used to record changes in files and folders tracked by DVC.
dvc commit
7. checkout
When you use `git checkout` to change the repository to an older version, the `dvc checkout` is used to update tracked files in the workspace based on dvc.lock and .dvc files.
dvc checkout
8. push
Similar to Git, you can push the files from the local workspace to the default remote using `dvc push`. The push command is necessary for team collaboration and keeping multiple copies of data to avoid disasters.
I use DagsHub’s remote storage to store and update the models in production.
For default remote:
dvc push
For specific remote storage:
dvc push -r <remote-name>
9. pull
The pull command is used to update the local workspace using remote storage. The push and pull works similarly to Git.
For pulling files from default remote:
dvc pull
For pulling files from specific remote:
dvc pull -r <remote-name>

10. run
It helps you create and modify pipeline stages in dvc.yml. The run command can be used to assemble machine learning and data pipelines.
- -n is the name of stage
- -d is dependencies
- -o is outputs
dvc run -n printer -d write.sh -o pages ./write.sh
11. exp
The exp or experiment command is used to generate, manage, and run machine learning experiments. It is a new feature. You can read more about experiment management here.
dvc exp {show,apply,diff,run,gc,branch,list,push,pull,remove,init}

Image from DVC experiments
12. repro
The repro is similar to Make. You can use it to reproduce complete or partial pipelines. It executes commands defined in their stages in the correct order.
dvc repro
13. metrics
After running the machine learning pipeline using `dvc repro`, the model performance metrics are generated. It represents scalar numbers such as AUC.
To view the metrics in terminal use:
dvc metrics show
And to compare metrics use:
dvc metrics diff
The metric diff command will compare the metrics of workspace with HEAD. You can compare it with a specific commit too.
14. plots
The plots are used to visualize data series such as RMSE vs. epochs and loss functions. The plots work with image files (JPEG, GIF, or PNG) and data series files (JSON, YAML, CSV, or TSV). It uses data series files to render line graphs using Vega-Lite.
Show machine learning result:
dvc plots show logs.csv

Image from DVC Doc
Compare results with HEAD:
dvc plots diff HEAD^ --targets logs.csv

Image from DVC Doc
Note: Running experiments and visualizing results is quite interactive in DVC VSCode new extension.
15. dag
It is used to visualize the pipelines in the form of one or more graphs of connected stages.
dvc dag

16. gc
It is used to remove unused files or directories from cache or remote storage. Similar to Git, It is used to optimize repository.
dvc gc -w
Conclusion
DVC has become an essential tool for data science and machine learning operations. You get to version data and models, track experiments, develop pipelines, share and collaborate, and deploy models to production. In this post, we have learned about essential DVC commands. Read the documentation to learn about additional commands and functionalities.
If you are new and want to experience DVC interactively, try DagsHub. The platform is curated for data scientists and machine learning engineering. You can check out my profile here to get inspiration.
Note: If you want to remove dvc files, pipeline, experiments, and metrics from the git repository, use `dvc destroy`.
More topics on data science commands
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in Technology Management and a bachelor's degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.